Describe Artificial Intelligence Workloads and ConsiderationsGewichtung 19%

Microsoft
Microsoft · Fundamentals
Microsoft AI-900
Microsoft Azure AI Fundamentals
Übungsfragen
242+ Fragen durchsuchen
Jede Antwort wird von 3 führenden KI-Modellen kreuzverifiziert, um maximale Genauigkeit zu gewährleisten. Erhalte detaillierte Erklärungen zu jeder Option und tiefgehende Fragenanalysen.
1
Frage 1
DRAG DROP - Match the types of machine learning to the appropriate scenarios. To answer, drag the appropriate machine learning type from the column on the left to its scenario on the right. Each machine learning type may be used once, more than once, or not at all. NOTE: Each correct selection is worth one point. Select and Place:
Teil 1:
Predict how many minutes late a flight will arrive based on the amount of snowfall at an airport. ______
Predicting “how many minutes late” is predicting a continuous numeric value (minutes). That is the defining characteristic of a regression problem: the model learns a relationship between input features (for example, snowfall amount, airport, time of year, historical delay patterns) and a numeric target. Why not classification? Classification would apply if the output were a category such as “on time / late” or “late by 0–15, 16–30, 31+ minutes.” Those are discrete classes, not a continuous number. Why not clustering? Clustering is used to discover groups without a labeled target. Here, you explicitly have a target variable (minutes late) and want a direct prediction, so supervised regression is appropriate.
Teil 2:
Segment customers into different groups to support a marketing department. ______
Customer segmentation for marketing is a classic clustering scenario. Typically, you have customer attributes and behaviors (purchase frequency, average order value, product categories, website activity, demographics) but you do not already have labels like “Segment A, Segment B.” Clustering algorithms group customers so that customers within a cluster are more similar to each other than to those in other clusters. Why not classification? Classification would require predefined segment labels in historical data (for example, you already know each customer’s segment and want to predict it for new customers). That’s not implied here. Why not regression? Regression predicts a numeric value (like lifetime value). Segmentation is about grouping, not predicting a continuous number.
Teil 3:
Predict whether a student will complete a university course. ______
Predicting whether a student will complete a course is a yes/no outcome, which is a binary classification problem. The model uses features such as attendance, assignment submissions, grades, engagement metrics, and prior course history to predict one of two discrete classes: “complete” or “not complete.” Why not regression? Regression would be used if you were predicting a continuous value such as “final grade percentage” or “number of weeks until completion.” Even if you encoded yes/no as 1/0, the underlying task is still classification because the desired output is a category. Why not clustering? Clustering could group students by behavior patterns, but it would not directly answer the labeled question of completion without additional interpretation.
2
Frage 2
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
Teil 1:
A banking system that predicts whether a loan will be repaid is an example of the ______ type of machine learning.
Correct answer: A (classification). Predicting whether a loan will be repaid is a supervised learning problem where the target is a discrete label, such as “repaid” vs “not repaid” (default). That is the definition of classification: learning from historical labeled examples (past loans with known outcomes) to predict a category for a new case. Why not regression (B): Regression is used when the output is a continuous numeric value, such as predicting the exact loan loss amount, interest rate, or customer lifetime value. While a credit model might output a probability (a number), the core task described—“whether a loan will be repaid”—is a categorical decision. Why not clustering (C): Clustering is unsupervised and groups data points by similarity without known labels (e.g., segmenting customers into risk groups when you don’t have repayment outcomes). Here, the bank explicitly wants a known outcome prediction, which requires labeled training data and classification.
3
Frage 3
What is a use case for classification?
This is regression, not classification. The outcome is “how many cups of coffee,” which is a numeric quantity (a continuous or count value). Regression models predict numbers, such as demand forecasting or estimating consumption. Even though it uses input features (hours slept) to make a prediction, the predicted value is not a category/label.
This describes clustering (unsupervised learning). The task is to analyze images and group them based on similar colors without stating predefined labels (like “red-themed,” “blue-themed”) provided during training. Clustering finds natural groupings in data. Classification would require labeled categories to predict, such as “sunset” vs “forest.”
This is a binary classification use case. The predicted outcome is categorical: whether someone uses a bicycle to commute (Yes/No). The input feature given is distance from home to work, and the model would learn from labeled examples. This aligns with classification tasks in Azure Machine Learning and is evaluated with metrics like precision/recall and AUC.
This is regression. The prediction target is “how many minutes it will take” to run a race, which is a continuous numeric value (time). Using past race times as features to predict a future time is a classic regression scenario. Classification would instead predict a category, such as “will finish under 30 minutes: Yes/No.”
Fragenanalyse
Core concept: This question tests your ability to distinguish classification from regression and clustering. In machine learning, classification predicts a discrete category/label (for example, Yes/No, Fraud/Not Fraud, Cat/Dog). Regression predicts a continuous numeric value (for example, time, price, quantity). Clustering groups items by similarity without predefined labels. Why the answer is correct: Option C asks to predict whether someone uses a bicycle to travel to work based on distance. The target outcome is categorical (uses a bicycle: Yes/No). That is a classic binary classification problem. The model learns a decision boundary from labeled training data (examples where the input features like distance—and possibly other features—are paired with the known label of bicycle usage). Key features and best practices: For classification, you typically: - Use labeled data with a categorical target. - Split data into training/validation/test sets to avoid overfitting. - Evaluate with classification metrics such as accuracy, precision, recall, F1-score, and AUC (especially when classes are imbalanced). - Consider feature engineering (for example, binning distance ranges) and handling class imbalance (resampling or class weights). In Azure, this maps to Azure Machine Learning classification tasks (AutoML or custom training) where you select “Classification” as the task type. Common misconceptions: Many learners confuse “predicting” with classification. The key is what you predict: a number (regression) vs a category (classification). Options A and D are predictions but they output numeric quantities, making them regression. Option B involves grouping by similarity, which is clustering (unsupervised), not classification. Exam tips: On AI-900, quickly identify the target variable type: - Yes/No or named categories => classification. - Numeric amount/time => regression. - “Group similar items” with no labels => clustering. Also watch for wording like “whether” (often classification) versus “how many/how much/how long” (often regression).
4
Frage 4
Which type of machine learning should you use to predict the number of gift cards that will be sold next month?
Classification is supervised learning used to predict a categorical label, such as “will sales be high/medium/low?” or “will we meet target: yes/no?”. It does not predict an exact numeric quantity. You could convert the problem into classes (bins), but the question asks for the number of gift cards sold, which is a numeric prediction, making classification the wrong fit here.
Regression is supervised learning used to predict a numeric value, such as units sold, revenue, or demand. Predicting the number of gift cards that will be sold next month is a classic regression/forecasting scenario: train on historical sales and related features (seasonality, promotions, holidays) and output a numeric estimate. This directly matches the problem statement.
Clustering is unsupervised learning used to group similar items or customers when you don’t have labeled outcomes. For example, clustering could segment customers by purchasing behavior, but it won’t directly predict next month’s gift card sales quantity. Since the question is about forecasting a numeric value, clustering is not appropriate.
Fragenanalyse
Core Concept: This question tests your ability to choose the correct machine learning task type. Predicting “the number of gift cards that will be sold next month” is a prediction of a numeric quantity, which maps to supervised learning—specifically regression. Why the Answer is Correct: Regression is used when the target (label) is a continuous numeric value (or a count treated as numeric) such as sales amount, demand, temperature, or number of items sold. Here, the label is “number of gift cards sold next month,” which is a numeric outcome. You would train a model using historical data (previous months’ gift card sales) and relevant features (seasonality, promotions, holidays, store traffic, economic indicators, etc.). The model learns relationships between features and the numeric label, then outputs a predicted number for the next month. Key Features / How It’s Done in Azure: In Azure Machine Learning, this is typically framed as a regression problem (or time-series forecasting, which is often implemented using regression-style approaches). You would: - Prepare labeled training data: features + historical sales (label). - Split data into train/validation/test sets. - Train a regression algorithm (e.g., linear regression, decision trees/boosting, or AutoML for regression/forecasting). - Evaluate with regression metrics such as MAE, RMSE, or R-squared. From an Azure Well-Architected Framework perspective, ensure reliability (monitor drift, retrain periodically), cost optimization (right-size compute, use AutoML efficiently), and operational excellence (MLOps pipelines for repeatable training/deployment). Common Misconceptions: - Classification can feel tempting because “sold” sounds like a category, but classification predicts discrete classes (e.g., “high/medium/low demand”), not an exact number. - Clustering is unsupervised and groups similar records without a labeled target; it doesn’t directly predict next month’s sales quantity. Exam Tips: If the output is a number (price, demand, quantity, revenue), think regression. If the output is a category (spam/ham, yes/no, risk level), think classification. If there are no labels and you’re grouping data, think clustering.
5
Frage 5
HOTSPOT - You are developing a model to predict events by using classification. You have a confusion matrix for the model scored on test data as shown in the following exhibit.
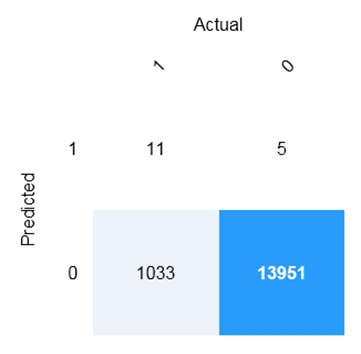
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:
Teil 1:
There are ______ correctly predicted positives.
“Correctly predicted positives” means True Positives (TP): cases where the model predicted class 1 and the actual class is also 1. In the confusion matrix, that is the intersection of Predicted = 1 (row) and Actual = 1 (column), which is the top-left cell. The value shown there is 11, so there are 11 correctly predicted positives. Why the other options are wrong: - 5 is False Positives (predicted 1, actual 0). - 1,033 is False Negatives (predicted 0, actual 1). - 13,951 is True Negatives (predicted 0, actual 0).
Teil 2:
There are ______ false negatives.
False Negatives (FN) are cases where the model predicted the negative class (0) but the actual class is positive (1). This represents missed positives, which is often critical in scenarios like fraud detection or medical screening. In the confusion matrix, FN is located at Predicted = 0 (row) and Actual = 1 (column), which is the bottom-left cell. The value in that cell is 1,033, so there are 1,033 false negatives. Why the other options are wrong: - 11 is True Positives (predicted 1, actual 1). - 5 is False Positives (predicted 1, actual 0). - 13,951 is True Negatives (predicted 0, actual 0).
Möchtest du alle Fragen unterwegs üben?
Lade Cloud Pass herunter – mit Übungstests, Fortschrittsverfolgung und mehr.
6
Frage 6
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
Teil 1:
Data values that influence the prediction of a model are called ______.
Correct answer: B. features. Features are the input data values (columns) that the model uses to learn patterns and make predictions. For example, in a house-price model, square footage, number of bedrooms, and location are features because they influence the predicted price. Why the others are wrong: - A. dependant variables: In most ML terminology, the dependent variable is the target/output you are trying to predict (often synonymous with the label), not the inputs that influence the prediction. - C. identifiers: Identifiers (like CustomerID) uniquely identify records but typically should not be used as predictive inputs because they don’t represent generalizable patterns; they can also introduce data leakage. - D. labels: A label is the known outcome/target value used for training in supervised learning (for example, “price” or “spam/not spam”), not the input values that influence the prediction.
7
Frage 7
(2 auswählen)What are two tasks that can be performed by using computer vision? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
Predicting stock prices is typically a machine learning forecasting/regression task using time-series data (historical prices, indicators, macro signals). It does not require interpreting images. In Azure, this aligns more with Azure Machine Learning or other ML approaches rather than Azure AI Vision. It can be confused with “AI” broadly, but it is not computer vision.
Detecting brands in an image is a computer vision capability. The system analyzes pixels to identify known logos/brands and often returns the brand name and a bounding box location. In Azure AI Vision, brand detection is part of image analysis features and is commonly used for media monitoring, compliance, and marketing analytics.
Detecting the color scheme (dominant colors, accent color, background/foreground colors) is a computer vision task because it derives visual attributes directly from image content. Azure AI Vision image analysis can return color information as part of its response. This is useful for design compliance, cataloging, and accessibility-related scenarios.
Translating text between languages is a Natural Language Processing workload, typically handled by Azure AI Translator. While computer vision can extract text from images via OCR, the act of translating language is not a vision task. The key distinction: translation operates on text/language, not on visual understanding.
Extracting key phrases is an NLP task (text analytics) that identifies important terms from a body of text. In Azure, this is provided by Azure AI Language (Text Analytics features). It may appear “AI-related,” but it does not involve analyzing images or video, so it is not computer vision.
Fragenanalyse
Core concept: This question tests recognition of typical Computer Vision workloads. In AI-900, “computer vision” refers to AI that interprets visual content (images/video) to identify objects, attributes, text, or other visual features. In Azure, these capabilities are commonly delivered through Azure AI Vision (formerly part of Cognitive Services), including image analysis, object detection, tagging, and brand detection. Why the answer is correct: B (Detect brands in an image) is a classic computer vision task. Brand detection identifies known logos/brands present in an image (for example, detecting a Microsoft or Coca-Cola logo). This is a built-in capability in Azure AI Vision’s image analysis features. C (Detect the color scheme in an image) is also a computer vision task. Image analysis can return dominant colors, accent color, and whether an image is black-and-white. This is part of extracting visual attributes from pixels—squarely within computer vision. Key features and best practices: Computer vision solutions typically involve: - Image analysis (tags, categories, objects, brands, colors, captions) - OCR (extracting printed/handwritten text from images) - Spatial understanding (bounding boxes for detected objects/brands) From an Azure Well-Architected Framework perspective, consider: - Reliability: handle transient failures and rate limits with retries/backoff. - Security: protect images in transit (HTTPS) and at rest; use managed identities and least privilege. - Cost optimization: batch requests where possible and choose appropriate pricing tiers. Common misconceptions: Options D and E are language tasks (translation and key phrase extraction), which belong to NLP, not computer vision. Option A (predict stock prices) is a time-series forecasting/regression machine learning scenario, not a vision workload. Exam tips: If the input is an image/video and the output is visual attributes (objects, brands, colors, text in images), it’s computer vision. If the input is text and the output is language understanding (translation, sentiment, key phrases), it’s NLP. If the input is numeric/time-series and the output is a prediction, it’s machine learning forecasting/regression.
8
Frage 8
HOTSPOT - For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
Teil 1:
Forecasting housing prices based on historical data is an example of anomaly detection.
Forecasting housing prices based on historical data is not anomaly detection. The key phrase is “forecasting … based on historical data,” which indicates a time-series forecasting problem: you use past values (and possibly external variables like interest rates, inventory, seasonality) to predict future prices. The objective is to estimate expected future values, not to identify rare deviations. Anomaly detection would instead focus on finding unusual house prices or transactions that deviate from normal patterns (for example, a sale price far above comparable properties, potentially indicating data errors or fraud). In AI-900, forecasting and anomaly detection are distinct workload types: forecasting predicts what will happen; anomaly detection flags what is unusual compared to normal behavior. Therefore, the correct answer is No.
Teil 2:
Identifying suspicious sign-ins by looking for deviations from usual patterns is an example of anomaly detection.
Identifying suspicious sign-ins by looking for deviations from usual patterns is a classic anomaly detection scenario. The goal is to detect rare or unusual events—such as logins from atypical locations, impossible travel (two distant sign-ins in a short time), unusual device fingerprints, abnormal login times, or spikes in failed attempts—relative to a baseline of normal user behavior. This aligns directly with the definition of anomaly detection: finding observations that differ significantly from the majority. It is often used in cybersecurity and fraud detection because anomalies can indicate compromised accounts or malicious activity. This is not primarily forecasting (predicting a future numeric value) or standard classification unless you already have labeled examples of “suspicious” vs. “normal.” Even when classification is used, the underlying concept in the prompt—“deviations from usual patterns”—maps to anomaly detection. Therefore, the correct answer is Yes.
Teil 3:
Predicting whether a patient will develop diabetes based on the patient’s medical history is an example of anomaly detection.
Predicting whether a patient will develop diabetes based on the patient’s medical history is not anomaly detection; it is classification. The output is a discrete label (for example, “will develop diabetes: yes/no”), and the model is trained on historical patient records where the outcome is known. This is a supervised learning task. Anomaly detection would be more appropriate if the goal were to identify unusual patient measurements or rare patterns that deviate from a normal population (for example, detecting abnormal lab results that might indicate an undiagnosed condition). But the prompt is explicitly about predicting a specific outcome (diabetes development), which is a typical binary classification use case. In AI-900, remember: classification predicts categories, regression predicts numbers, forecasting predicts future time-based values, and anomaly detection flags rare deviations. Since the scenario is outcome prediction (yes/no), the correct answer is No.
9
Frage 9
For a machine learning progress, how should you split data for training and evaluation?
Incorrect. Training a supervised model requires both features and labels so the algorithm can learn the mapping and compute a loss/error signal. Evaluation also requires labels to compare predictions to ground truth and calculate metrics (accuracy, RMSE, etc.). Separating features for training and labels for evaluation breaks the per-row relationship between inputs and targets and is not a valid split strategy.
Correct. The standard approach is to randomly split the dataset by rows (examples) into training and evaluation sets. Each set includes both features and labels for those rows. This allows the model to learn from training examples and then be evaluated on unseen examples to estimate generalization. Randomization (often stratified for classification) helps reduce bias and improves representativeness.
Incorrect. Labels alone cannot be used to train a supervised model because the model needs input features to learn how to predict the label. Likewise, evaluating using only features without labels prevents you from calculating performance metrics because there is no ground truth for comparison. This option reflects a misunderstanding of the roles of features (inputs) and labels (targets).
Incorrect. Splitting by columns means you are separating features from other features (or potentially separating the label column), which changes the problem definition and typically makes training/evaluation invalid. The goal is to test generalization to new examples, not to remove parts of the input space. Column splits are only used in specialized scenarios (for example, feature ablation studies), not standard evaluation.
Fragenanalyse
Core concept: This question tests the fundamental machine learning principle of creating separate datasets for training and evaluation (validation/test) to measure how well a model generalizes to unseen data. In supervised learning, each row (example) contains features (inputs) and a label (target). The split should preserve that relationship. Why the answer is correct: You should randomly split the dataset by rows into a training set and an evaluation set. Each split contains both the features and the labels for those rows. The model learns patterns from the training rows, then you evaluate performance by comparing the model’s predictions against the true labels in the evaluation rows. Random row splitting reduces selection bias and helps ensure the evaluation set represents the same underlying distribution as training. Key features / best practices: Common splits are 70/30 or 80/20, and for small datasets you may use k-fold cross-validation. For classification, a stratified split is often preferred to keep class proportions similar in both sets. To avoid data leakage, preprocessing steps that learn from data (for example, normalization parameters, imputation values, feature selection) should be fit on the training set only and then applied to evaluation. In time-series scenarios, you typically do not randomize; you split by time to respect temporal order. Common misconceptions: A frequent mistake is thinking “features are for training and labels are for evaluation” (or vice versa). Labels are required during training (to compute loss) and during evaluation (to compute metrics). Another misconception is splitting by columns, which breaks the meaning of features and can remove essential inputs, producing invalid evaluation. Exam tips: For AI-900, remember: supervised learning uses features + labels together per row. Training and evaluation sets are created by splitting examples (rows), not splitting features (columns). Watch for wording that implies separating features from labels—this is almost always incorrect unless the question is specifically about inference/prediction after training.
10
Frage 10
DRAG DROP - You plan to apply Text Analytics API features to a technical support ticketing system. Match the Text Analytics API features to the appropriate natural language processing scenarios. To answer, drag the appropriate feature from the column on the left to its scenario on the right. Each feature may be used once, more than once, or not at all. NOTE: Each correct selection is worth one point. Select and Place:
Teil 1:
______ Understand how upset a customer is based on the text contained in the support ticket.
Sentiment analysis is the correct feature because the scenario is explicitly about understanding how upset a customer is, which is an opinion/emotion classification problem. Azure AI Language sentiment analysis evaluates text and returns sentiment labels (such as negative/neutral/positive) and often confidence scores; it can also provide sentence-level sentiment to pinpoint the most negative parts of a ticket. Why the others are wrong: - Entity recognition extracts structured items (like dates, names, products) but does not measure emotion. - Key phrase extraction identifies important terms/topics (e.g., “login failure”, “billing issue”) but not how the customer feels. - Language detection only identifies the language of the text and does not assess sentiment. In a ticketing system, sentiment is commonly used for prioritization/escalation rules (e.g., highly negative tickets routed to senior support).
Teil 2:
______ Summarize important information from the support ticket.
Key phrase extraction is the best match for summarizing important information from a support ticket. This feature pulls out the most relevant words and phrases that represent the main topics of the text (for example: “VPN connection”, “authentication error”, “password reset”). That effectively creates a lightweight “summary” suitable for tagging, search indexing, routing, and analytics dashboards. Why the others are wrong: - Sentiment analysis summarizes emotional tone, not the key technical content. - Entity recognition extracts specific entity types (dates, organizations, products), but it may miss the broader topic phrases and is not intended as a general summary. - Language detection only identifies the language and provides no content summary. On AI-900, “summarize important information” in the context of Text Analytics typically maps to key phrase extraction rather than abstractive summarization (which is a different capability).
Teil 3:
______ Extract key dates from the support ticket.
Entity recognition is correct for extracting key dates from the support ticket because dates are a standard entity type that Named Entity Recognition (NER) can detect and return in structured form. For example, it can identify values like “January 15, 2026”, “last Friday”, or “10/12/2025” as date/time entities, enabling you to populate ticket fields, correlate incidents, or validate SLAs. Why the others are wrong: - Key phrase extraction might surface a date-like phrase, but it is not designed to reliably classify and structure dates as entities. - Sentiment analysis evaluates tone and does not extract factual items like dates. - Language detection only determines the language of the ticket. In practice, entity recognition is used to extract many structured fields (dates, product names, locations, people) from unstructured ticket text to support automation and reporting.
Möchtest du alle Fragen unterwegs üben?
Lade Cloud Pass herunter – mit Übungstests, Fortschrittsverfolgung und mehr.
11
Frage 11
A company employs a team of customer service agents to provide telephone and email support to customers. The company develops a webchat bot to provide automated answers to common customer queries. Which business benefit should the company expect as a result of creating the webchat bot solution?
Increased sales is possible as an indirect outcome if faster answers improve customer satisfaction or reduce abandonment. However, the scenario focuses on automated answers to common support queries, not lead generation, recommendations, or upsell workflows. On AI-900, you should select the most direct and predictable benefit of a support chatbot, which is operational efficiency rather than revenue growth.
A webchat bot that answers common questions provides “contact deflection,” meaning fewer routine issues reach human agents. This reduces call/email volume, shortens queues, and frees agents to handle complex cases. This is the clearest, most immediate business benefit tied to conversational AI/NLP solutions in customer support scenarios and is commonly cited as a primary driver for chatbot adoption.
Improved product reliability refers to the product’s stability, fewer defects, and higher uptime—typically achieved through better engineering practices, monitoring, redundancy, and testing. A support chatbot may improve the support experience, but it does not directly change the product’s underlying reliability characteristics. Therefore, this is not the expected primary business benefit in this scenario.
Fragenanalyse
Core concept: A webchat bot is an AI workload in the Natural Language Processing (NLP) space. In Azure exam context (AI-900), this aligns with conversational AI solutions such as Azure AI Bot Service and Azure AI Language (or integrated language understanding capabilities) that can interpret user text, route intents, and provide automated responses. Why the answer is correct: The most direct and expected business benefit of deploying a webchat bot to answer common customer questions is reducing the workload on human customer service agents. The bot can handle high-volume, repetitive, “Tier 0/Tier 1” queries (hours, password resets, order status, basic troubleshooting) 24/7, which decreases the number of calls/emails that require an agent. This typically improves operational efficiency, reduces wait times, and allows agents to focus on complex or sensitive cases that require empathy, judgment, or access to specialized systems. Key features and best practices: Chatbots commonly use intent recognition and entity extraction to understand what the customer wants, plus predefined answers or knowledge base retrieval. Good implementations include escalation/handoff to a human agent when confidence is low, logging and analytics to identify new FAQs, and continuous improvement via conversation transcripts. From an Azure Well-Architected perspective, this supports Cost Optimization (deflecting routine contacts), Operational Excellence (standardized responses), and Reliability (consistent availability when properly designed). Common misconceptions: “Increased sales” can happen indirectly (better responsiveness), but it is not the primary guaranteed benefit of an FAQ-style support bot. “Improved product reliability” relates to engineering quality and uptime of the product itself; a bot does not inherently make the product more reliable. Exam tips: For AI-900, map the scenario to the workload type: chatbots = NLP/conversational AI. Then choose the most immediate, measurable business outcome: contact deflection and reduced agent workload. If the bot is described as answering common queries, expect benefits around efficiency and support scalability rather than revenue growth or product engineering outcomes.
12
Frage 12
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
Teil 1:
The handling of unusual or missing values provided to an AI system is a consideration for the Microsoft ______ principle for responsible AI.
Correct answer: C (reliability and safety). “Handling of unusual or missing values” is fundamentally about how robust and dependable an AI system is when it encounters imperfect or unexpected input. Reliability and safety in Microsoft’s Responsible AI principles focuses on ensuring AI systems perform consistently under normal conditions and degrade gracefully under abnormal conditions (for example, null values, outliers, corrupted records, or unexpected formats). It also includes preventing harmful outcomes when the system is uncertain or failing. Why the others are wrong: - A (inclusiveness) is about designing systems that empower and include people of diverse abilities and backgrounds (accessibility, equitable user experience), not about input anomaly handling. - B (privacy and security) concerns protecting sensitive data, access control, encryption, and resisting data leakage or adversarial attacks. - D (transparency) is about explainability and communicating how the system works, its limitations, and when it may be unreliable—related, but not the core principle for handling missing/unusual values. In practice, reliability/safety is addressed via validation, fallback logic, monitoring, and testing with edge cases.
13
Frage 13
DRAG DROP - Match the Microsoft guiding principles for responsible AI to the appropriate descriptions. To answer, drag the appropriate principle from the column on the left to its description on the right. Each principle may be used once, more than once, or not at all. NOTE: Each correct selection is worth one point. Select and Place:
Teil 1:
Ensure that AI systems operate as they were originally designed, respond to unanticipated conditions, and resist harmful manipulation.
Correct: E (Reliability and safety). The description emphasizes that AI systems should behave consistently with their intended design, handle unexpected conditions, and resist harmful manipulation. These are classic reliability/safety concerns: robustness, fault tolerance, resilience to adversarial inputs, and safe operation under edge cases. Why others are wrong: - A (Accountability) is about who is responsible and ensuring oversight and governance, not the technical/operational robustness of the model. - B (Fairness) focuses on avoiding discriminatory outcomes across groups. - C (Inclusiveness) focuses on accessibility and ensuring solutions work for people with diverse abilities and needs. - D (Privacy and security) focuses on protecting data and controlling data usage, not primarily on model robustness and safe behavior.
Teil 2:
Implementing processes to ensure that decisions made by AI systems can be overridden by humans.
Correct: A (Accountability). The key phrase is that AI decisions “can be overridden by humans.” This is human-in-the-loop governance: ensuring there is appropriate oversight, escalation paths, and the ability for people to intervene when an automated decision is incorrect or inappropriate. Accountability also implies clear ownership for outcomes and processes for auditing and remediation. Why others are wrong: - E (Reliability and safety) is about the system operating safely and robustly, but the explicit requirement for human override maps more directly to accountability and governance. - D (Privacy and security) concerns data protection and consent, not decision override. - B (Fairness) concerns bias and equitable outcomes. - C (Inclusiveness) concerns accessibility and designing for diverse users.
Teil 3:
Provide consumers with information and controls over the collection, use, and storage of their data.
Correct: D (Privacy and security). The description is explicitly about giving consumers information and controls over the collection, use, and storage of their data. That aligns directly with privacy principles (transparency, consent, data minimization, appropriate retention) and security principles (protecting data at rest/in transit, access control). Why others are wrong: - A (Accountability) is about oversight and responsibility for AI outcomes, not user controls over personal data. - E (Reliability and safety) is about robust and safe system behavior. - B (Fairness) is about avoiding biased outcomes. - C (Inclusiveness) is about ensuring the solution is usable and beneficial for people with diverse needs, not data governance.
14
Frage 14
(2 auswählen)What are two tasks that can be performed by using the Computer Vision service? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
Incorrect. Training a custom image classification model is typically done with Azure AI Custom Vision, which is designed for building and training custom classifiers and object detectors using labeled images. The Computer Vision service focuses on prebuilt analysis (tags, captions, OCR, etc.) rather than training your own classification model. In AI-900, “custom training” is a key clue pointing to Custom Vision.
Correct. Computer Vision can detect faces in an image by locating them and returning bounding boxes (and sometimes related attributes depending on the API/version and policy constraints). This is face detection, not identity recognition. For AI-900, treat “detect faces” as a Computer Vision capability, while person identification/verification is associated with the Face service and has additional governance requirements.
Correct. Recognizing handwritten text is supported through Computer Vision OCR (often referred to as the Read capability). It can extract both printed and handwritten text from images and documents, returning the text plus positional information. This is a common workload for digitizing notes, forms, and scanned paperwork, and it is a standard example of Computer Vision functionality in AI-900.
Incorrect. Translating text between languages is performed by Azure AI Translator (an NLP service). While Computer Vision can extract the text from an image using OCR, it does not translate it. A typical solution is a two-step pipeline: Computer Vision (OCR) to read the text, then Translator to translate the extracted text into the target language.
Fragenanalyse
Core concept: This question tests what you can do with Azure AI Vision (commonly referred to in AI-900 as the Computer Vision service). Computer Vision provides prebuilt models for analyzing images and extracting information such as objects, tags, captions, OCR text, and face-related detection (depending on feature availability and responsible AI constraints). Why the answer is correct: B (Detect faces in an image) is a supported Computer Vision capability. The service can detect the presence and location of faces (for example, returning bounding boxes). In exam context, “detect faces” is distinct from “identify/verify a person,” which is handled by Azure Face (a separate capability/service area with stricter access requirements). C (Recognize handwritten text) is also a core Computer Vision capability via Optical Character Recognition (OCR). Azure AI Vision Read/OCR can extract printed and handwritten text from images and documents, returning the recognized text and its layout/coordinates. Key features and best practices: - OCR/Read supports both printed and handwritten text and is commonly used for digitizing forms, receipts, notes, and scanned documents. - Face detection returns geometric information (bounding boxes/landmarks) but does not inherently perform identity recognition. - From an Azure Well-Architected perspective, use managed AI services to reduce operational burden (Operational Excellence) and ensure you follow Responsible AI and privacy requirements (Security). Common misconceptions: A seems plausible because “image classification” is a vision task, but training a custom image classification model is done with Azure AI Custom Vision (a separate service) rather than the prebuilt Computer Vision service. D seems plausible because OCR extracts text, but translating text between languages is an NLP task performed by Azure AI Translator. A common pattern is: Computer Vision OCR to extract text, then Translator to translate it. Exam tips: - Remember the split: prebuilt image analysis/OCR/face detection = Computer Vision; custom training for classification/detection = Custom Vision. - Translation is not a vision feature; it’s handled by Translator. - Watch for wording: “detect faces” (yes) vs “recognize/identify people” (not Computer Vision in AI-900 framing).
15
Frage 15
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
Teil 1:
Natural language processing can be used to ______
Correct answer: A. Classifying email messages as work-related or personal is a classic NLP task called text classification. The input is unstructured text (email subject/body), and the model or service determines a label/category based on language features (words, phrases, semantics). In Azure, this aligns with NLP capabilities such as Azure AI Language (text classification) or custom text classification. Why the others are wrong: B (predict the number of future car rentals) is forecasting/regression on historical numeric data (time series), which is a machine learning workload, not NLP. C (predict which website visitors will make a transaction) is typically a binary classification ML problem using clickstream/session attributes and customer features; it doesn’t require language understanding. D (stop a process in a factory when extremely high temperatures are registered) is a sensor/IoT threshold or anomaly detection scenario; it involves telemetry and operational rules rather than processing human language.
Möchtest du alle Fragen unterwegs üben?
Lade Cloud Pass herunter – mit Übungstests, Fortschrittsverfolgung und mehr.
16
Frage 16
You use natural language processing to process text from a Microsoft news story. You receive the output shown in the following exhibit.

Which type of natural languages processing was performed?
Entity recognition (Named Entity Recognition) identifies mentions of real-world entities in text and classifies them into types such as Person, Organization, Location, DateTime, and Quantity. The exhibit shows extracted terms with explicit labels like [Organization], [DateTime], and [Quantity-Number], which is the hallmark output of NER in Azure AI Language/Text Analytics.
Key phrase extraction returns the main talking points from a document (for example, “distance learning”, “remote learning environments”), typically as an unlabeled list of phrases. It does not usually assign semantic categories like Organization, DateTime, or Quantity. Because the exhibit includes typed labels, it goes beyond key phrases and indicates entity recognition.
Sentiment analysis determines whether text expresses positive, negative, neutral, or mixed sentiment and often provides confidence scores. The output would look like sentiment labels and numeric scores per document or sentence, not a list of detected terms categorized as PersonType, Organization, or DateTime. The exhibit is about identifying entities, not emotions or opinions.
Translation converts text from one language to another (for example, English to Spanish). The exhibit shows the same English content but annotated with entity types, not translated into a different language. There is no bilingual output or target-language text, so translation is not the NLP technique demonstrated here.
Fragenanalyse
Core Concept: This question tests Named Entity Recognition (NER), an NLP capability provided in Azure AI Language (and historically in Text Analytics). NER identifies and categorizes “entities” in unstructured text into predefined types such as Person, Organization, Location, DateTime, Quantity, and Skill. Why the Answer is Correct: The exhibit shows the original news paragraph on the left and, on the right, extracted terms labeled with categories like "now [DateTime]", "students [PersonType]", "Microsoft [Organization]", "175 [Quantity-Number]", and "183,000 [Quantity-Number]". This is exactly what entity recognition does: it detects mentions of real-world concepts and assigns them semantic labels. The presence of typed labels (Organization, DateTime, Location, Quantity) is the key indicator. Key Features: In Azure AI Language, entity recognition can return: - Entity text spans (the words found in the document) - Entity categories and subcategories (e.g., Quantity-Number) - Confidence scores - Offsets/positions in the text (useful for highlighting in apps) Common use cases include indexing/search enrichment, compliance and redaction workflows, customer support analytics, and knowledge mining with Azure AI Search. Common Misconceptions: Key phrase extraction also pulls important terms, but it does not typically label them with semantic types like Organization or DateTime. Sentiment analysis outputs polarity (positive/negative/neutral) and confidence scores, not entity lists. Translation converts text between languages; nothing in the exhibit indicates language conversion. Exam Tips: For AI-900, look for clues in the output format: - If you see categories like Person/Location/Organization/DateTime/Quantity, it’s entity recognition. - If you see a short list of “important phrases” without types, it’s key phrase extraction. - If you see sentiment labels and scores, it’s sentiment analysis. - If you see text in another language, it’s translation. Also remember that these capabilities fall under NLP workloads (Azure AI Language) and are commonly used to structure unstructured text for downstream analytics and search.
17
Frage 17
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
Teil 1:
From Azure Machine Learning designer, to deploy a real-time inference pipeline as a service for others to consume, you must deploy the model to ______.
Correct answer: B. Azure Container Instances. In Azure Machine Learning Designer, when you want to deploy a real-time inference pipeline so others can call it (typically via a REST endpoint), you deploy it to a compute target that hosts the web service. Azure Container Instances (ACI) is the standard, simplest managed option for real-time endpoints—commonly used for development, testing, and low-to-moderate traffic production scenarios. It requires minimal infrastructure management and is frequently referenced in AI-900-level content as the default real-time deployment target. Why the others are wrong: A. A local web service is for local testing/debugging and is not a cloud-hosted service intended for broad consumption. C. AKS is also a valid real-time hosting option, but it’s typically chosen for production at scale (high availability, autoscaling, advanced networking). The question doesn’t indicate those requirements, so ACI is the most appropriate. D. Azure ML compute is primarily for training and batch processing; it isn’t the typical hosting target for a deployed real-time web service endpoint.
18
Frage 18
Your company wants to build a recycling machine for bottles. The recycling machine must automatically identify bottles of the correct shape and reject all other items. Which type of AI workload should the company use?
Anomaly detection focuses on identifying rare or unusual patterns compared to a baseline, commonly in numeric data such as sensor telemetry, logs, or transactions. It can be used for defect detection in manufacturing when you mostly know what “normal” looks like. However, the question’s core requirement is visual identification of bottle shape from images, which is better addressed by computer vision classification/detection.
Conversational AI is designed for interactive experiences using natural language, such as chatbots and voice bots. It involves intent recognition, dialog management, and generating responses (for example, with Azure Bot Service). A recycling machine identifying bottle shapes is not a dialog or conversation problem, so conversational AI does not fit the workload described.
Computer vision is the correct workload because the machine must visually recognize whether an item matches the correct bottle shape and reject others. This maps to image classification and/or object detection. In Azure, you could use Azure AI Vision for prebuilt capabilities or Custom Vision to train a model on your specific bottle shapes under different lighting and orientations, enabling accurate automated acceptance/rejection.
Natural language processing (NLP) deals with understanding and generating human language in text or speech-to-text scenarios—tasks like sentiment analysis, entity extraction, translation, and summarization. Since the recycling machine’s input is the physical appearance (shape) of items rather than text or spoken language, NLP is not the appropriate AI workload.
Fragenanalyse
Core Concept: This scenario is a computer vision workload: using images/video to detect, classify, or verify physical objects based on visual characteristics (shape, size, contours). In Azure AI terms, this aligns with services like Azure AI Vision (image analysis) and Custom Vision (train a model to classify items or detect objects). Why the Answer is Correct: A recycling machine that must “identify bottles of the correct shape and reject all other items” needs to visually inspect items. The key requirement is recognizing an object’s shape and deciding whether it matches an accepted class (correct bottle) or not. That is classic image classification (Is this an accepted bottle type?) and/or object detection (Where is the bottle and what type is it?)—both are computer vision tasks. Key Features / How it’s commonly implemented: - Image classification: Train a model with labeled images of acceptable bottles vs. non-bottles/other items. The model outputs probabilities for each class. - Object detection: If items appear in different positions/orientations, detection can locate the object and classify it. - Custom Vision: Often used when you need domain-specific recognition (your bottle shapes) rather than generic labels. - Operational considerations: Use adequate training data across lighting, angles, occlusions, and bottle variations; validate with a test set; monitor drift (new bottle designs). For edge/real-time needs, deploy to edge devices (e.g., Azure IoT Edge) to reduce latency. Common Misconceptions: Anomaly detection can sound plausible because “reject all other items” resembles “detect outliers.” However, anomaly detection is typically used for unusual patterns in numeric/time-series data (sensor readings, transactions) or for “defect detection” when you mostly have examples of normal and few of abnormal. Here, the primary signal is visual shape recognition, which is computer vision. Exam Tips: When the input is images/video (cameras) and the goal is to recognize objects, shapes, text in images, or scenes, choose computer vision. Reserve NLP for text/language, conversational AI for chatbots/voice assistants, and anomaly detection for outlier detection in metrics or sensor/telemetry streams. (Well-Architected tie-in: For reliability and performance, consider edge inference for low latency and resilience; for security, protect camera feeds and model endpoints; for cost optimization, right-size compute and retrain only as needed.)
19
Frage 19
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
Teil 1:
You can use the ______ service to train an object detection model by using your own images.
Correct answer: B. Custom Vision. Azure AI Custom Vision is designed specifically to train custom computer vision models using your own images. For object detection, you upload images, draw bounding boxes around objects, label them, and train a model that can locate and classify objects within new images. This directly matches the requirement “train an object detection model by using your own images.” Why the others are wrong: - A. Computer Vision (Azure AI Vision) provides prebuilt models (for example, tagging, OCR, and general detection) but is not the primary service for training a custom object detector with your own labeled dataset in the AI-900 context. - C. Form Recognizer (Azure AI Document Intelligence) is for extracting structured data from documents (forms, invoices, receipts) using OCR + layout/field extraction, not general object detection in images. - D. Video Indexer is for extracting insights from video/audio (transcripts, faces, keywords, scenes) rather than training an object detection model from your own still images.
20
Frage 20
HOTSPOT - For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
Teil 1:
Labelling is the process of tagging training data with known values.
Yes. Labeling is the process of associating each training example with the correct known value (the “ground truth”). In supervised learning, these labels are what the model learns to predict—for example, tagging images as “cat” or “dog,” marking emails as “spam” or “not spam,” or assigning a numeric target value for regression such as “house price.” Labeling can be done manually by humans, programmatically (when rules or existing systems provide ground truth), or via assisted labeling tools. Without labels, you typically move into unsupervised learning (clustering, dimensionality reduction) or self-supervised approaches, which are different problem types. Therefore, the statement correctly describes labeling as tagging training data with known values.
Teil 2:
You should evaluate a model by using the same data used to train the model.
No. You should not evaluate a model using the same data used to train it because it does not measure generalization. Training performance often looks better than real-world performance, especially if the model overfits (learns noise or memorizes examples). Proper evaluation uses a separate test dataset (or validation dataset) that the model has not seen during training. Common approaches include train/test splits, train/validation/test splits, and cross-validation. This helps estimate how the model will perform on new data and supports better decisions about model selection and hyperparameter tuning. Using training data for evaluation can lead to deploying a model that appears accurate in development but fails in production.
Teil 3:
Accuracy is always the primary metric used to measure a model’s performance.
No. Accuracy is not always the primary metric; the best metric depends on the task and the consequences of different error types. In imbalanced classification (e.g., fraud detection), a model can achieve high accuracy by always predicting the majority class while missing the minority class entirely. In such cases, recall (sensitivity), precision, F1-score, and PR-AUC are often more informative. If false positives are costly (flagging legitimate transactions as fraud), precision may matter more; if false negatives are costly (missing fraud), recall may be prioritized. For regression problems, accuracy is not the standard metric at all—metrics like MAE or RMSE are used. Therefore, accuracy is not universally the primary measure of model performance.
Prüfungsbereiche
Übe Microsoft-Zertifizierungsprüfungsfragen mit KI-verifizierten Antworten und detaillierten Erklärungen. 5 Zertifizierungen verfügbar.
Describe Fundamental Principles of Machine Learning on AzureGewichtung 19%
Describe Features of Computer Vision Workloads on AzureGewichtung 19%
Describe Features of Natural Language Processing (NLP) Workloads on AzureGewichtung 19%
Describe Features of Generative AI Workloads on AzureGewichtung 24%
Übungstests
2 Übungstests · 50 Fragen · 45 Minuten
Weitere Microsoft-Zertifizierungen












Jetzt mit dem Üben beginnen
Lade Cloud Pass herunter und beginne alle Microsoft AI-900-Übungsfragen zu üben.