
Practice Test #1
Simuliere die echte Prüfungserfahrung mit 50 Fragen und einem Zeitlimit von 100 Minuten. Übe mit KI-verifizierten Antworten und detaillierten Erklärungen.
KI-gestützt
Dreifach KI-verifizierte Antworten & Erklärungen
Jede Antwort wird von 3 führenden KI-Modellen kreuzverifiziert, um maximale Genauigkeit zu gewährleisten. Erhalte detaillierte Erklärungen zu jeder Option und tiefgehende Fragenanalysen.
Übungsfragen
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You develop an HTTP triggered Azure Function app to process Azure Storage blob data. The app is triggered using an output binding on the blob. The app continues to time out after four minutes. The app must process the blob data. You need to ensure the app does not time out and processes the blob data. Solution: Use the Durable Function async pattern to process the blob data. Does the solution meet the goal?
HOTSPOT - You have a web service that is used to pay for food deliveries. The web service uses Azure Cosmos DB as the data store. You plan to add a new feature that allows users to set a tip amount. The new feature requires that a property named tip on the document in Cosmos DB must be present and contain a numeric value. There are many existing websites and mobile apps that use the web service that will not be updated to set the tip property for some time. How should you complete the trigger? NOTE: Each correct selection is worth one point. Hot Area:
var r = ______
if (______) {
r.______
DRAG DROP - You are a developer for a software as a service (SaaS) company that uses an Azure Function to process orders. The Azure Function currently runs on an Azure Function app that is triggered by an Azure Storage queue. You are preparing to migrate the Azure Function to Kubernetes using Kubernetes-based Event Driven Autoscaling (KEDA). You need to configure Kubernetes Custom Resource Definitions (CRD) for the Azure Function. Which CRDs should you configure? To answer, drag the appropriate CRD types to the correct locations. Each CRD type may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
Azure Function code belongs to which CRD type?
Polling interval belongs to which CRD type?
Azure Storage connection string belongs to which CRD type?
DRAG DROP - You are developing a new page for a website that uses Azure Cosmos DB for data storage. The feature uses documents that have the following format:
{
"name": "John",
"city": "Seattle"
}
You must display data for the new page in a specific order. You create the following query for the page:
SELECT*
FROM People p
ORDER BY p.name, p.city DESC
You need to configure a Cosmos DB policy to support the query. How should you configure the policy? To answer, drag the appropriate JSON segments to the correct locations. Each JSON segment may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
Exhibit:
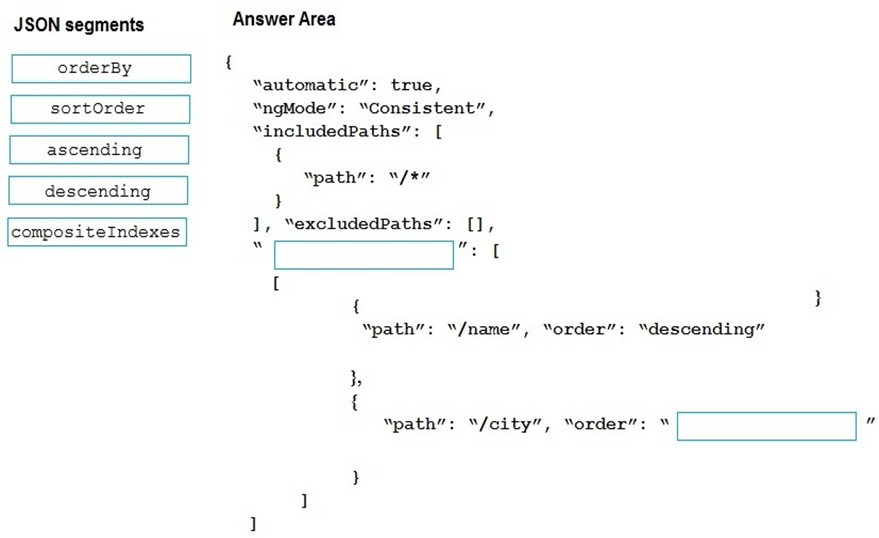
Which Cosmos DB indexing policy supports the ORDER BY query?
HOTSPOT - You are developing a ticket reservation system for an airline. The storage solution for the application must meet the following requirements: ✑ Ensure at least 99.99% availability and provide low latency. ✑ Accept reservations even when localized network outages or other unforeseen failures occur. ✑ Process reservations in the exact sequence as reservations are submitted to minimize overbooking or selling the same seat to multiple travelers. ✑ Allow simultaneous and out-of-order reservations with a maximum five-second tolerance window. You provision a resource group named airlineResourceGroup in the Azure South-Central US region. You need to provision a SQL API Cosmos DB account to support the app. How should you complete the Azure CLI commands? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
consistencyLevel = ______
az cosmosdb create \ --name $name \ ______ \ --resource-group $resourceGroupName \ --max-interval 5 \
--locations ______ \ --default-consistency-level = $consistencylevel
Möchtest du alle Fragen unterwegs üben?
Lade Cloud Pass herunter – mit Übungstests, Fortschrittsverfolgung und mehr.
HOTSPOT - You are developing an application that uses Azure Storage Queues. You have the following code:
CloudStorageAccount storageAccount = CloudStorageAccount.Parse
(CloudConfigurationManager.GetSetting("StorageConnectionString"));
CloudQueueClient queueClient = storageAccount.CreateCloudQueueClient();
CloudQueue queue = queueClient.GetQueueReference("appqueue");
await queue.CreateIfNotExistsAsync();
CloudQueueMessage peekedMessage = await queue.PeekMessageAsync();
if (peekedMessage != null)
{
Console.WriteLine("The peeked message is: {0}", peekedMessage.AsString);
}
CloudQueueMessage message = await queue.GetMessageAsync();
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
The code configures the lock duration for the queue.
The last message read remains in the queue after the code runs.
The storage queue remains in the storage account after the code runs.
You are building a website that uses Azure Blob storage for data storage. You configure Azure Blob storage lifecycle to move all blobs to the archive tier after 30 days. Customers have requested a service-level agreement (SLA) for viewing data older than 30 days. You need to document the minimum SLA for data recovery. Which SLA should you use?
You develop and deploy an ASP.NET web app to Azure App Service. You use Application Insights telemetry to monitor the app. You must test the app to ensure that the app is available and responsive from various points around the world and at regular intervals. If the app is not responding, you must send an alert to support staff. You need to configure a test for the web app. Which two test types can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
HOTSPOT - You are implementing a software as a service (SaaS) ASP.NET Core web service that will run as an Azure Web App. The web service will use an on-premises SQL Server database for storage. The web service also includes a WebJob that processes data updates. Four customers will use the web service. ✑ Each instance of the WebJob processes data for a single customer and must run as a singleton instance. ✑ Each deployment must be tested by using deployment slots prior to serving production data. ✑ Azure costs must be minimized. ✑ Azure resources must be located in an isolated network. You need to configure the App Service plan for the Web App. How should you configure the App Service plan? To answer, select the appropriate settings in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Number of VM instances ______
Pricing tier ______
You are developing an ASP.NET Core website that uses Azure FrontDoor. The website is used to build custom weather data sets for researchers. Data sets are downloaded by users as Comma Separated Value (CSV) files. The data is refreshed every 10 hours. Specific files must be purged from the FrontDoor cache based upon Response Header values. You need to purge individual assets from the Front Door cache. Which type of cache purge should you use?

Jetzt mit dem Üben beginnen
Lade Cloud Pass herunter und beginne alle Microsoft AZ-204-Übungsfragen zu üben.