
Practice Test #3
Simuliere die echte Prüfungserfahrung mit 50 Fragen und einem Zeitlimit von 100 Minuten. Übe mit KI-verifizierten Antworten und detaillierten Erklärungen.
KI-gestützt
Dreifach KI-verifizierte Antworten & Erklärungen
Jede Antwort wird von 3 führenden KI-Modellen kreuzverifiziert, um maximale Genauigkeit zu gewährleisten. Erhalte detaillierte Erklärungen zu jeder Option und tiefgehende Fragenanalysen.
Übungsfragen
You are creating a report in Power BI Desktop. You load a data extract that includes a free text field named coll. You need to analyze the frequency distribution of the string lengths in col1. The solution must not affect the size of the model. What should you do?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are modeling data by using Microsoft Power BI. Part of the data model is a large Microsoft SQL Server table named Order that has more than 100 million records. During the development process, you need to import a sample of the data from the Order table. Solution: You write a DAX expression that uses the FILTER function. Does this meet the goal?
You have a report that contains four pages. Each page contains slicers for the same four fields. Users report that when they select values in a slicer on one page, the selections are not persisted on other pages. You need to recommend a solution to ensure that users can select a value once to filter the results on all the pages. What are two possible recommendations to achieve this goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
DRAG DROP -
You receive revenue data that must be included in Microsoft Power BI reports. You preview the data from a Microsoft Excel source in Power Query as shown in the following exhibit. Column1 Column2 Column3 Column4 Column5 Column6 Valid: 100% Valid: 100% Valid: 100% Valid: 100% Valid: 100% Valid: 100% Error: 0% Error: 0% Error: 0% Error: 0% Error: 0% Error: 0% Empty: 0% Empty: 0% Empty: 0% Empty: 0% Empty: 0% Empty: 0%
Department Product 2016 2017 2018 2019 Bikes Carbon mountainbike 1002815 1006617 1007814 1007239 Bikes Aluminium road bike 1007024 1001454 1005842 1007105 Bikes Touring bike 1003676 1005171 1001669 1003244 Accessories Bell 76713 10247 60590 52927 Accessories Bottle holder 26690 29613 67955 71466 Accessories Satnav 83189 40113 71684 24697 Accessories Mobilephone holder 68641 80336 58099 45706 You plan to create several visuals from the data, including a visual that shows revenue split by year and product. You need to transform the data to ensure that you can build the visuals. The solution must ensure that the columns are named appropriately for the data that they contain. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
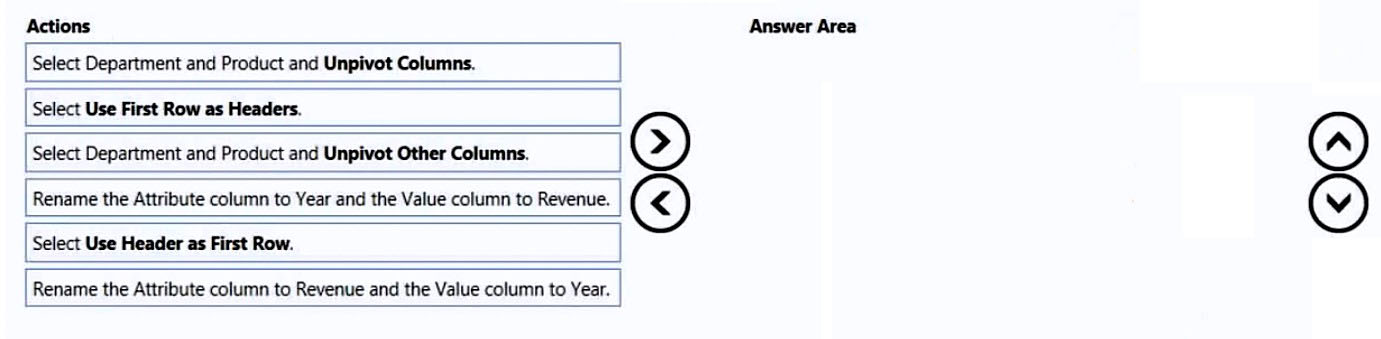
Which Power Query transformation sequence produces a long revenue table with Department, Product, Year, and Revenue columns?
DRAG DROP -
You are modifying a Power BI model by using Power BI Desktop. You have a table named Sales that contains the following fields. Name Data type Transaction ID Whole Number Customer Key Whole Number Sales Date Key Date Sales Amount Whole Number You have a table named Transaction Size that contains the following data. Transaction Size ID | Transaction Size | Min | Max 1 | Small | 0 | 10,000 2 | Medium | 10,001 | 100,000 3 | Large | 100,001 | 999,999,999 You need to create a calculated column to classify each transaction as small, medium, or large based on the value in Sales Amount. How should you complete the code? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
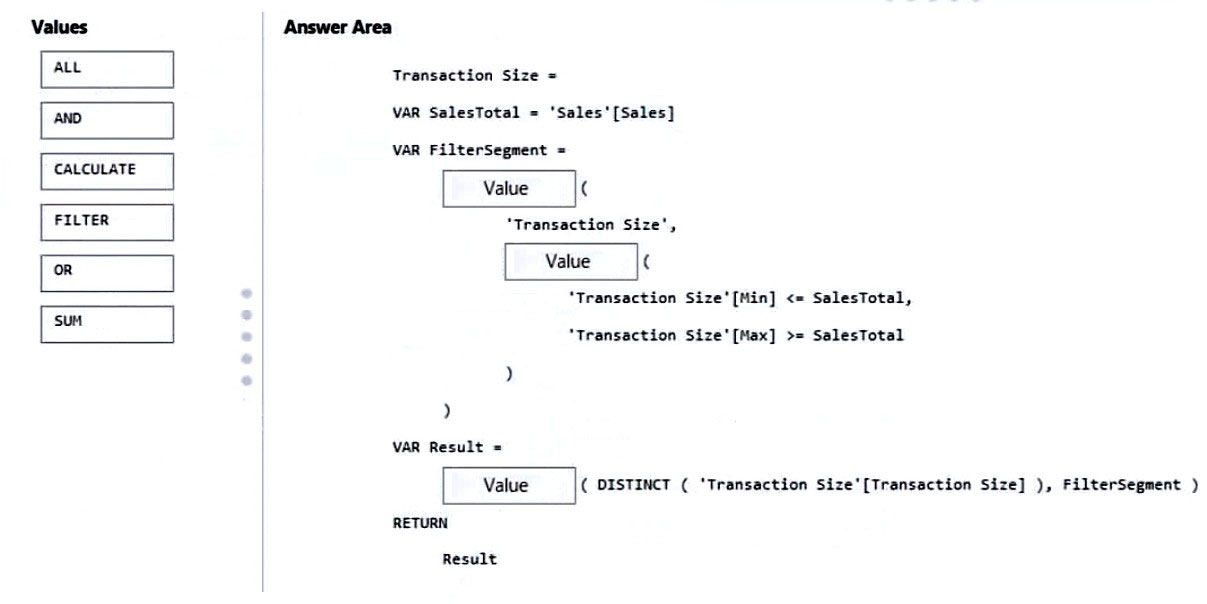
Which DAX functions complete the calculated column expression?
Möchtest du alle Fragen unterwegs üben?
Lade Cloud Pass herunter – mit Übungstests, Fortschrittsverfolgung und mehr.
HOTSPOT - You have two CSV files named Products and Categories. The Products file contains the following columns: ✑ ProductID ✑ ProductName ✑ SupplierID ✑ CategoryID The Categories file contains the following columns: ✑ CategoryID ✑ CategoryName ✑ CategoryDescription From Power BI Desktop, you import the files into Power Query Editor. You need to create a Power BI dataset that will contain a single table named Product. The Product will table includes the following columns: ✑ ProductID ✑ ProductName ✑ SupplierID ✑ CategoryID ✑ CategoryName ✑ CategoryDescription How should you combine the queries, and what should you do on the Categories query? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Combine the queries by performing a: ______
On the Categories query: ______
HOTSPOT - You have the Power BI dashboard shown in the Dashboard exhibit. (Click the Dashboard tab.)
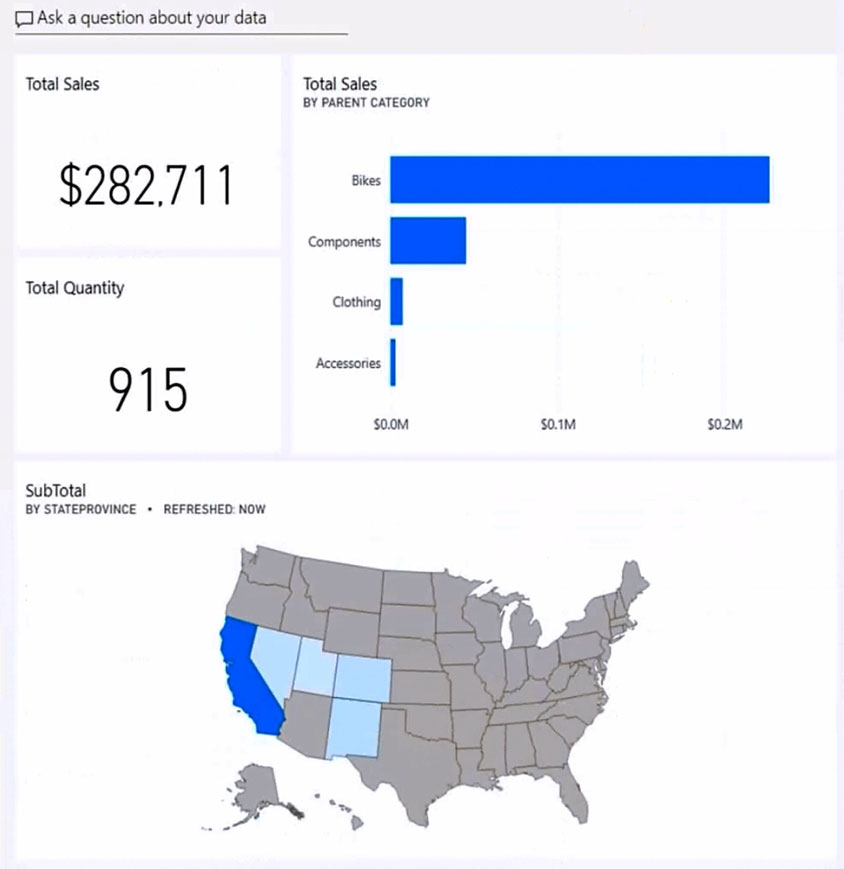
You need to ensure that when users view the dashboard on a mobile device, the dashboard appears as shown in the Mobile exhibit. (Click the Mobile tab.)
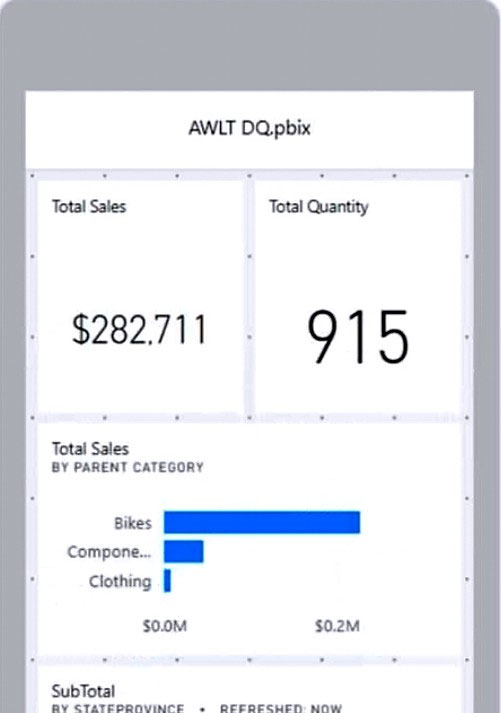
What should you do? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Update the layout in the: Dashboard mobile layout
Update the layout in the: Dashboard web layout
Update the layout in the: Report mobile layout
Resize and move: The SubTotal map tile
Resize and move: The Total Sales and Total Quantity tiles
Resize and move: The Total Sales by Parent Category tile
You have a report that contains three pages. One of the pages contains a KPI visualization. You need to filter all the visualizations in the report except for the KPI visualization. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A business intelligence (BI) developer creates a dataflow in Power BI that uses DirectQuery to access tables from an on-premises Microsoft SQL server. The Enhanced Dataflows Compute Engine is turned on for the dataflow. You need to use the dataflow in a report. The solution must meet the following requirements: ✑ Minimize online processing operations. ✑ Minimize calculation times and render times for visuals. ✑ Include data from the current year, up to and including the previous day. What should you do?
You have a Power BI tenant. You have reports that use financial datasets and are exported as PDF files. You need to ensure that the reports are encrypted. What should you implement?

Jetzt mit dem Üben beginnen
Lade Cloud Pass herunter und beginne alle PL-300: Microsoft Power BI Data Analyst-Übungsfragen zu üben.