Bootstrapping and Maintaining a Google Cloud OrganizationPondération 20%

GCP
GCP · Professional
Google Professional Cloud DevOps Engineer
Téléchargez Cloud Pass et commencez à vous entraîner sur toutes les questions Google Professional Cloud DevOps Engineer.
Questions d'entraînement
Parcourir les 199+ questions
Chaque réponse est vérifiée par 3 modèles d'IA de pointe pour garantir une précision maximale. Obtenez des explications détaillées par option et une analyse approfondie des questions.
1
Question 1
Your media-streaming company operates on Google Cloud with 6 departments each mapped to a folder under the organization; there are 120 existing projects and about 10 new projects are created every month, and the security team requires that every log entry (all log types and resource types, across all regions) be exported in near real time to a third-party SIEM that ingests from a Cloud Pub/Sub topic named siem-ingest, so you must implement a solution that automatically covers all current and future projects with minimal ongoing maintenance and does not move logs into Cloud Logging buckets; what should you do?
2
Question 2
You manage the release pipeline for a payments API running on a regional GKE cluster in us-central1. The API is exposed via a Kubernetes Service (ClusterIP) behind an HTTP Ingress managed by Cloud Load Balancing. You implement blue/green by running two Deployments: pay-blue-v1 and pay-green-v2, each with 10 replicas and labels color=blue/green. During the cutover, you updated the Service selector to color=green to send 100% of ~1,500 RPS to pay-green-v2. Within 2 minutes, the HTTP 5xx error rate spikes to 7%, breaching the 1% SLO target. You must roll back immediately with less than 30 seconds of impact, without rebuilding images or modifying the Ingress configuration. What should you do?
3
Question 3
Your company runs a payments API behind an NGINX Ingress Controller on a GKE Standard cluster with three n2-standard-4 nodes; the Ops Agent DaemonSet is deployed on all nodes and forwards access logs to Cloud Logging. In the past hour you observed suspicious traffic from the IP address 198.51.100.77, and you need to visualize the per-minute count of requests from this IP in Cloud Monitoring without changing application code or deploying additional collectors. What should you do to achieve this with minimal operational overhead?
4
Question 4
Your team runs a CI pipeline that executes ~200 integration test jobs per day, and each job must call internal gRPC APIs that are reachable only on 10.20.0.0/16 in a Shared VPC with no external IPs or NAT; the security policy requires that test traffic must never traverse the public internet, you are not allowed to maintain bastion hosts or custom proxies, tests must finish within 10 minutes per run, and you want the least operational overhead for setup and ongoing management—what should you do?
5
Question 5
A biotech company aggregates container and application logs from 15 Google Cloud projects into a single Cloud Logging bucket in a dedicated observability project using aggregated sinks with a 30-day retention policy. Compliance requires that each of the 8 product squads can only view logs originating from their own project(s), while the SRE team must be able to view all logs across all projects. You must implement least-privilege access, avoid duplicating data, and minimize ongoing costs and operational overhead. What should you do?
Envie de vous entraîner partout ?
Téléchargez Cloud Pass — inclut des tests d'entraînement, le suivi de progression et plus encore.
6
Question 6
Your team operates a high-throughput webhook processor on Cloud Run (fully managed) in us-central1 with min instances set to 0, max instances set to 40, request concurrency set to 80, and container limits of 1 vCPU and 1 GiB memory; over the last 14 days peak traffic reached 2,500 RPS with p95 latency under 300 ms, and you need to accurately identify actual container CPU and memory utilization per revision to right-size resources and reduce Cloud Run costs by at least 20% without changing application code; which tool should you use to get these utilization metrics across all revisions?
7
Question 7
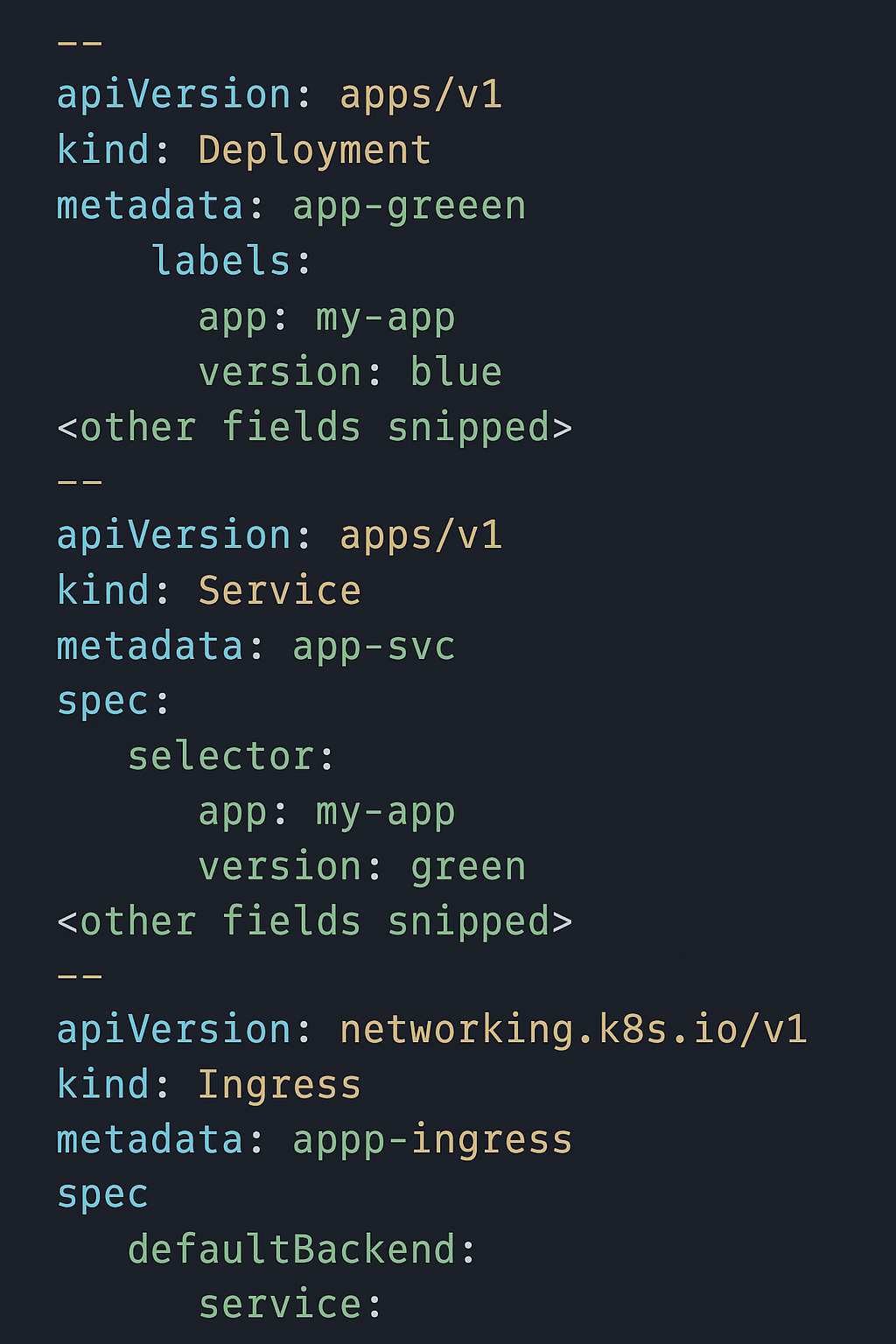
You are responsible for a customer-facing booking service deployed on Google Kubernetes Engine (GKE) using a blue/green deployment approach. The manifests include two Deployments (app-green and app-blue), a Service (app-svc), and an Ingress that routes traffic to the Service, as shown in the provided configuration. After updating app-green to the latest release, users report that most booking requests are failing in production, even though the release passed all pre-production tests. You must quickly restore service availability while giving developers a chance to debug the failing release. What should you do?
8
Question 8
(Sélectionnez 2)You are setting up an automated container image build in Cloud Build for a payment reconciliation microservice. The source code is hosted in Bitbucket Cloud. Your compliance policy mandates that production-grade images must be built only from the release/v1 branch, and that all merges into release/v1 must be explicitly approved by the governance group with at least two approvers. You want the process to be as automated as possible while meeting these requirements. What should you do? (Choose two.)
9
Question 9
You operate a high-frequency IoT telemetry ingestion service on Google Kubernetes Engine with separate production and staging clusters, each in its own VPC network; within each VPC, the API gateway nodes and stream processing nodes run on different subnets (api-subnet and proc-subnet), and a security analyst suspects an intermittent malicious beacon originating from the production API gateway nodes that occurs a few times per hour and lasts under 10 seconds, and you need to ensure network flow data is captured for forensic analysis without delaying the investigation; what should you do?
10
Question 10
You are the on-call SRE for a live trivia streaming platform running on Google Kubernetes Engine (GKE) behind a global external HTTP(S) Load Balancer with geo-based routing; each of 4 regions (us-central1, europe-west1, asia-southeast1, southamerica-east1) contains 3 regional GKE clusters serving traffic via NEG backends, and at 18:05 UTC you receive a page that asia-southeast1 users have had 100% connection failures (HTTP 502) for the past 7 minutes while other regions are healthy and asia-southeast1 normally serves 25% of global requests and the availability SLO is 99.95% monthly with a rapid burn alert firing; you want to resolve the incident following SRE best practices. What should you do first?
11
Question 11
Your retail analytics team is deploying a webhook service on Cloud Run that ingests inventory updates and uses the OpenTelemetry SDK with a BatchSpanProcessor to export traces to Cloud Trace every 5 seconds. Under light traffic (<1 request/second), about 30% of spans never appear in Cloud Trace even though requests return HTTP 200. The service is configured with min instances = 0, concurrency = 80, memory = 1 GiB, and 2 vCPU, and CPU is currently set to be allocated only during request processing. You must ensure reliable trace export without changing application code or adding external components. What should you do?
12
Question 12
Your fintech startup operates three GKE Autopilot clusters (dev, staging, prod) across us-central1 and europe-west4 and uses a GitOps workflow with a single Git repository per team. Product squads often need Google Cloud resources (for example, 12 Pub/Sub topics, 4 Cloud SQL instances, and multiple IAM bindings) to support their microservices. You must let engineers declare these resources as code from within their Kubernetes namespaces, enforce least-privilege access with Kubernetes RBAC, and have the system continuously reconcile desired state so that any manual console change is corrected within 10 minutes, following Google-recommended practices. What should you do?
13
Question 13
You are planning capacity for a real-time video engagement analytics platform ahead of an international rollout; the platform runs entirely in containers on Google Kubernetes Engine (GKE) Standard using a regional cluster in asia-southeast1 across three zones with the cluster autoscaler enabled, you forecast 10% month-over-month user growth over the next six months, current steady-state workload consumes about 28% of total deployed CPU capacity, and the service must remain resilient to the loss of any single zone; you want to minimize user impact from either growth or a zonal outage while avoiding unnecessary spend; how should you prepare to handle the predicted growth?
14
Question 14
You lead a team building Cloud Run–based microservices for a fintech product. Each repository includes end-to-end integration tests under tests/e2e that deploy a temporary Cloud Run revision into the staging project svc-stg-001 and delete it after completion. Source control is GitHub, and feature branches follow the pattern feature/*. You must automatically run the integration tests on every pull request targeting the main branch and block merges until tests pass. Tests should run only when files under service/ or tests/e2e/ change, and each run must finish within 30 minutes. You want a managed, GCP-native solution to automate this workflow. What should you do?
15
Question 15
Your retail analytics application runs on Cloud Run in us-central1 behind Cloud Load Balancing and depends on BigQuery and Cloud Storage; over the past week, P95 latency spiked from 180 ms to 3000 ms and 5xx errors peaked at 4.2% during three separate incidents. You need to build a Cloud Monitoring dashboard to troubleshoot and specifically determine whether the spikes are caused by your service or by outages/degradations in Google Cloud services you rely on (e.g., Cloud Load Balancing, BigQuery, Cloud Storage); what should you do?
16
Question 16
Your video analytics platform is deploying a frame-processing microservice on both GKE Autopilot in us-central1 (200 pods across 5 namespaces) and 30 on-premises Linux servers in a private data center; you must collect detailed, function-level performance data (CPU and heap profiles) with under 5% overhead, keep profiles for 30 days, and visualize everything centrally in a single Google Cloud project without building or operating your own metrics pipeline—what should you do?
17
Question 17
Your fintech startup adheres to SRE practices, and a SEV-1 incident is causing elevated HTTP 5xx errors (38%) in the payment authorization service in us-central1, impacting approximately 65% of live transactions; you are the designated Communications Lead, engineering has no ETA for recovery, and within the first 10 minutes you’ve received over 40 internal Slack DMs and 120 customer tickets requesting updates. What should you do to efficiently keep everyone informed while the mitigation is in progress?
18
Question 18
Your retail analytics team uses Cloud Build to deploy a containerized Python service to Cloud Run (min instances: 0, max instances: 3) on the staging project; the latest deployment failed because the container exited at startup with exit code 78 and the log message 'KeyError: PAYMENT_SERVICE_URL not set', which has occurred in roughly 30% of recent staging runs when new configs are introduced; you must determine the root cause and add a control in the CI/CD workflow that prevents future rollouts when required environment variables are missing, ensuring the pipeline fails in under 2 minutes if any of PAYMENT_SERVICE_URL, OAUTH_ISSUER, or REGION is absent or empty; what should you do?
19
Question 19
You are defining latency SLOs for a globally distributed checkout API used by a subscription media platform during concert livestream spikes; stakeholders expect consistent availability and fast responses, and current user feedback indicates performance is satisfactory. Over a rolling 30-day window, telemetry aggregated across all active-active regions shows the 90th percentile latency is 85 ms and the 95th percentile latency is 210 ms, measured at the HTTP request boundary. What latency SLO should the team publish?
20
Question 20
You work for a fintech company headquartered in Frankfurt where an Organization Policy enforces constraints/gcp.resourceLocations to allow only europe-west3 and europe-west1 for all resources. When you tried to create a secret in Secret Manager using automatic replication, you received the error: "Constraint constraints/gcp.resourceLocations violated for [orgpolicy:projects/1234567890] attempting to create a secret in [global]". You must resolve the error while remaining compliant and ensure the secret’s data resides only in the allowed EU regions. What should you do?
Domaines de l'examen
Entraînez-vous aux questions d'examen de certification GCP avec des réponses vérifiées par IA et des explications détaillées. 5 certifications disponibles.
Building and Implementing CI/CD Pipelines (Application, Infrastructure, ML Workloads)Pondération 25%
Applying Site Reliability Engineering (SRE) PracticesPondération 18%
Implementing Observability Practices and Troubleshooting IssuesPondération 25%
Optimizing Performance and CostPondération 12%
Tests d'entraînement
1 Tests d'entraînement · 50 Questions · 120 Minutes
Témoignages de réussite(6)
R
R**********Nov 24, 2025
Période de préparation: 1 month
The exam has many operational scenarios, and Cloud Pass prepared me well for them. The explanations were clear and helped me understand not just the “what” but the “why” behind each solution.
진
진**Nov 20, 2025
Période de préparation: 1 month
문제와 해설이 있어서 좋았고, 시험에서 무난하게 합격했어요. 시험에서 안보이던 유형도 나왔는데 잘 풀긴 했네요
J
J************Nov 17, 2025
Période de préparation: 1 month
The practice questions were challenging in a good way, and many matched the style of the real exam. I passed!
N
N************Nov 14, 2025
Période de préparation: 1 month
very close to the real exam format
D
D***********Oct 18, 2025
Période de préparation: 1 month
I used Cloud Pass during my last week of preparation, and it helped me fill in gaps I didn’t even know I had.
Autres certifications GCP

Google Associate Cloud Engineer
Associate

Google Professional Cloud Network Engineer
Professional

Google Associate Data Practitioner
Associate

Google Cloud Digital Leader
Foundational

Google Professional Cloud Security Engineer
Professional

Google Professional Cloud Architect
Professional

Google Professional Cloud Database Engineer
Professional

Google Professional Data Engineer
Professional

Google Professional Cloud Developer
Professional

Google Professional Machine Learning Engineer
Professional

Commencer à s'entraîner
Téléchargez Cloud Pass et commencez à vous entraîner sur toutes les questions Google Professional Cloud DevOps Engineer.