
Practice Test #3
Simule a experiência real do exame com 50 questões e limite de tempo de 100 minutos. Pratique com respostas verificadas por IA e explicações detalhadas.
Powered by IA
Respostas e Explicações Verificadas por 3 IAs
Cada resposta é verificada por 3 modelos de IA líderes para garantir máxima precisão. Receba explicações detalhadas por alternativa e análise aprofundada das questões.
Questões de Prática
You need to store the user agreements. Where should you store the agreement after it is completed?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You develop a software as a service (SaaS) offering to manage photographs. Users upload photos to a web service which then stores the photos in Azure Storage Blob storage. The storage account type is General-purpose V2. When photos are uploaded, they must be processed to produce and save a mobile-friendly version of the image. The process to produce a mobile-friendly version of the image must start in less than one minute. You need to design the process that starts the photo processing. Solution: Trigger the photo processing from Blob storage events. Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You are developing an Azure solution to collect point-of-sale (POS) device data from 2,000 stores located throughout the world. A single device can produce 2 megabytes (MB) of data every 24 hours. Each store location has one to five devices that send data. You must store the device data in Azure Blob storage. Device data must be correlated based on a device identifier. Additional stores are expected to open in the future. You need to implement a solution to receive the device data. Solution: Provision an Azure Service Bus. Configure a topic to receive the device data by using a correlation filter. Does the solution meet the goal?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You develop Azure solutions. You must grant a virtual machine (VM) access to specific resource groups in Azure Resource Manager. You need to obtain an Azure Resource Manager access token. Solution: Use an X.509 certificate to authenticate the VM with Azure Resource Manager. Does the solution meet the goal?
You are developing an e-commerce solution that uses a microservice architecture. You need to design a communication backplane for communicating transactional messages between various parts of the solution. Messages must be communicated in first-in-first-out (FIFO) order. What should you use?
Quer praticar todas as questões em qualquer lugar?
Baixe o Cloud Pass — inclui simulados, acompanhamento de progresso e mais.
HOTSPOT - You plan to deploy a web app to App Service on Linux. You create an App Service plan. You create and push a custom Docker image that contains the web app to Azure Container Registry. You need to access the console logs generated from inside the container in real-time. How should you complete the Azure CLI command? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
az webapp log ______ --name Contosoweb --resource-group ContosoDevRG
______ filesystem
az ______ log ______ --name ContosoWeb --resource-group ContosoDevRG
az webapp log ______ --name ContosoWeb --resource-group ContosoDevRG
DRAG DROP - You are developing an application to use Azure Blob storage. You have configured Azure Blob storage to include change feeds. A copy of your storage account must be created in another region. Data must be copied from the current storage account to the new storage account directly between the storage servers. You need to create a copy of the storage account in another region and copy the data. In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Exhibit:
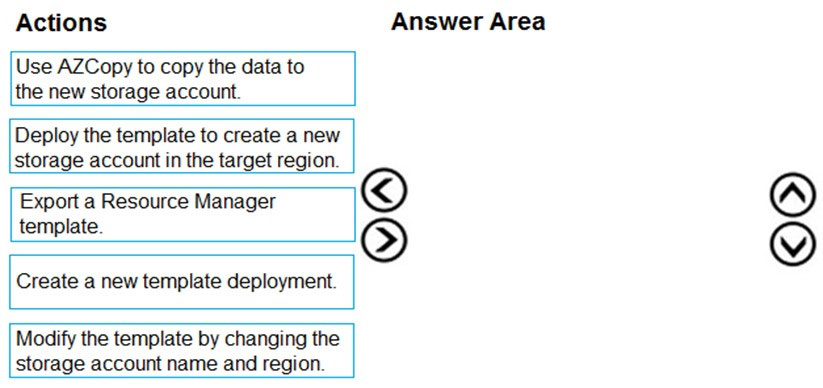
Which sequence should you use to recreate the storage account in another region and copy the data?
DRAG DROP - You are developing a microservices solution. You plan to deploy the solution to a multinode Azure Kubernetes Service (AKS) cluster. You need to deploy a solution that includes the following features: ✑ reverse proxy capabilities ✑ configurable traffic routing ✑ TLS termination with a custom certificate Which components should you use? To answer, drag the appropriate components to the correct requirements. Each component may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
Deploy solution.
View cluster and external IP addressing.
Implement a single, public IP endpoint that is routed to multiple microservices.
You develop a website. You plan to host the website in Azure. You expect the website to experience high traffic volumes after it is published. You must ensure that the website remains available and responsive while minimizing cost. You need to deploy the website. What should you do?
You provide an Azure API Management managed web service to clients. The back-end web service implements HTTP Strict Transport Security (HSTS). Every request to the backend service must include a valid HTTP authorization header. You need to configure the Azure API Management instance with an authentication policy. Which two policies can you use? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.

Comece a Praticar Agora
Baixe o Cloud Pass e comece a praticar todas as questões de Microsoft AZ-204.