
Practice Test #2
50개 문제와 45분 시간 제한으로 실제 시험을 시뮬레이션하세요. AI 검증 답안과 상세 해설로 학습하세요.
AI 기반
3중 AI 검증 답안 및 해설
GPT Pro, Claude Opus, Gemini Pro가 답안과 해설을 교차 검증합니다. 선택지별 근거부터 요구사항 분해와 정답 아키텍처까지 확인하세요.
실전형 문제
Azure SQL managed instance에 데이터를 저장하는 트랜잭션 애플리케이션이 있습니다. 언제 읽기 전용 데이터베이스 replica를 구현해야 합니까?
HOTSPOT - 다음 각 진술에 대해, 진술이 참이면 Yes를 선택합니다. 그렇지 않으면 No를 선택합니다. 참고: 각 정답 선택은 1점입니다. 핫 영역:
Microsoft Power BI 대시보드는 단일 workspace에 연결됩니다.
Microsoft Power BI 대시보드는 단일 dataset의 시각화만 표시할 수 있다.
Microsoft Power BI 대시보드는 Microsoft Excel 통합 문서의 시각화를 표시할 수 있습니다.
HOTSPOT - 문장을 완성하려면 답안 영역에서 적절한 옵션을 선택하세요. 핫 영역:
관계형 데이터베이스는 ______ 경우에 반드시 사용해야 합니다.
HOTSPOT - 문장을 완성하려면 답변 영역에서 적절한 옵션을 선택하세요. 핫 영역:
폴더 수준의 보안과 atomic 디렉터리 조작을 모두 지원하도록 Azure Storage account를 구성하려면, ______
HOTSPOT - 문장을 완성하려면 답안 영역에서 적절한 옵션을 선택하십시오. 핫 영역:
______는 테이블과 연관된 객체로, 키 값에 따라 테이블의 데이터 행을 정렬하고 저장합니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
귀사는 페이지가 매겨진 보고서가 있는 보고 솔루션을 보유하고 있습니다. 해당 보고서는 데이터 웨어하우스의 차원 모델을 쿼리합니다. 이 보고 솔루션은 어떤 유형의 처리를 사용합니까?
DRAG DROP - 용어를 적절한 설명과 매칭하세요. 답하려면 왼쪽 열에서 적절한 용어를 오른쪽의 설명으로 드래그하세요. 각 용어는 한 번만, 여러 번, 또는 전혀 사용하지 않을 수 있습니다. 참고: 각 올바른 매칭은 1점입니다. 선택 및 배치:
데이터를 보관하는 데이터베이스 개체
쿼리에 의해 내용이 정의되는 database object
데이터 검색 속도를 향상시키는 데 도움이 되는 database object
HOTSPOT - 문장을 완성하려면 답안 영역에서 적절한 옵션을 선택하세요. 핫 영역:
키/값 데이터 저장소는 ______에 최적화되어 있습니다.
HOTSPOT - 다음 각 문장에 대해 문장이 참이면 Yes를 선택합니다. 그렇지 않으면 No를 선택합니다. 참고: 각 정답 선택은 1점입니다. 핫 영역:
Azure Cosmos DB API는 Azure Cosmos DB 계정의 각 데이터베이스마다 별도로 구성됩니다.
Partition key는 Azure Cosmos DB에서 쿼리를 최적화하는 데 사용됩니다.
동일한 Azure Cosmos DB 논리적 파티션에 포함된 항목은 서로 다른 파티션 키를 가질 수 있습니다.
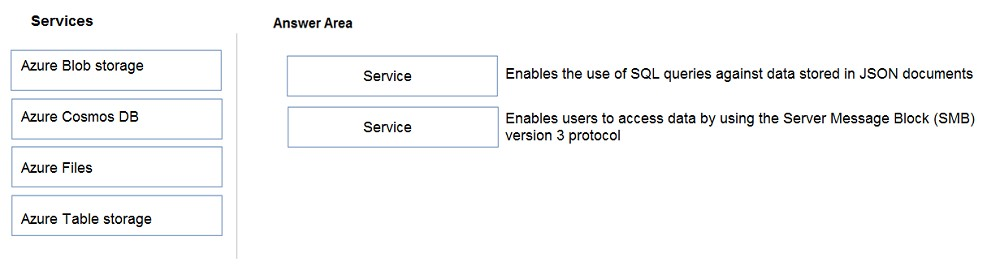
DRAG DROP - 데이터 저장소 서비스를 적절한 설명과 매칭하는 문제입니다.
아래 이미지의 정답 영역에 들어갈 올바른 매칭 조합은 무엇인가요?

지금 학습 시작하기
Cloud Pass를 다운로드하고 Microsoft DP-900 자격증 학습을 이어가세요.