
Practice Test #5
Simulate the real exam experience with 50 questions and a 100-minute time limit. Practice with AI-verified answers and detailed explanations.
AI-Powered
Triple AI-Verified Answers & Explanations
GPT Pro, Claude Opus, and Gemini Pro cross-check every answer and explanation. See the reasoning for each option, requirement breakdowns, and solution architectures.
Practice Questions
You have a Microsoft Power BI report. The size of PBIX file is 550 MB. The report is accessed by using an App workspace in shared capacity of powerbi.com. The report uses an imported dataset that contains one fact table. The fact table contains 12 million rows. The dataset is scheduled to refresh twice a day at 08:00 and 17:00. The report is a single page that contains 15 AppSource visuals and 10 default visuals. Users say that the report is slow to load the visuals when they access and interact with the report. You need to recommend a solution to improve the performance of the report. What should you recommend?
HOTSPOT - You have a Power BI report. You have the following tables. Name Description Balances The table contains daily records of closing balances for every active bank account. The closing balances appear for every day the account is live, including the last day. Date The table contains a record per day for the calendar years of 2000 to 2025. There is a hierarchy for financial year, quarter, month, and day. You have the following DAX measure. Accounts := CALCULATE ( DISTINCTCOUNT (Balances[AccountID]), LASTDATE ('Date'[Date]) For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
A table visual that displays the date hierarchy at the year level and the [Accounts] measure will show the total number of accounts that were live throughout the year.
A table visual that displays the date hierarchy at the month level and the [Accounts] measure will show the total number of accounts that were live throughout the month.
A table visual that displays the date hierarchy at the day level and the [Accounts] measure will show the total number of accounts that were live that day.
You have a Microsoft Excel file in a Microsoft OneDrive folder. The file must be imported to a Power BI dataset. You need to ensure that the dataset can be refreshed in powerbi.com. Which two connectors can you use to connect to the file? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
HOTSPOT - You have a Power BI imported dataset that contains the data model shown in the following exhibit.
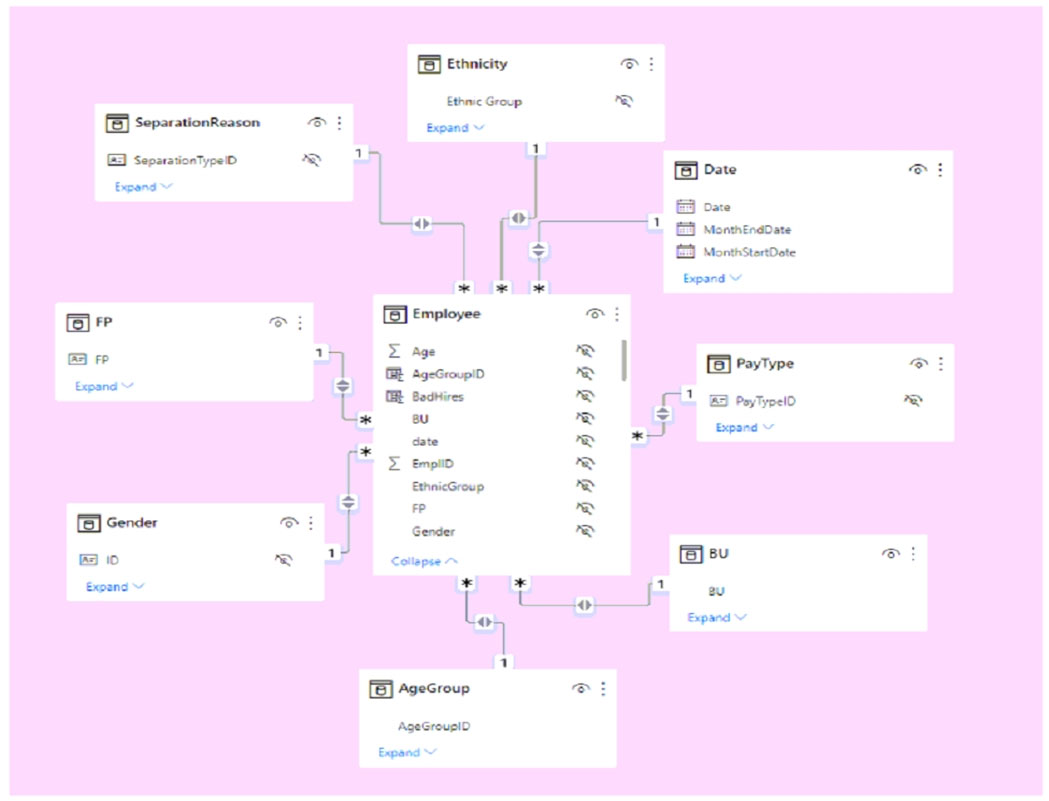
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:
Changing the ______ setting of the relationships will improve report query performance.
The data model is organized into a ______.
HOTSPOT - You plan to create Power BI dataset to analyze attendance at a school. Data will come from two separate views named View1 and View2 in an Azure SQL database. View1 contains the columns shown in the following table. Name Data type Attendance Date Date Student ID Bigint Period Number Tinyint Class ID Int View2 contains the columns shown in the following table.
The views can be related based on the Class ID column. Class ID is the unique identifier for the specified class, period, teacher, and school year. For example, the same class can be taught by the same teacher during two different periods, but the class will have a different class ID. You need to design a star schema data model by using the data in both views. The solution must facilitate the following analysis: ✑ The count of classes that occur by period ✑ The count of students in attendance by period by day ✑ The average number of students attending a class each month In which table should you include the Teacher First Name and Period Number fields? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Class ID is of data type Bigint.
Class Name is of data type Varchar(200).
Class Subject is of data type Varchar(100).
Teacher ID is of data type Int.
Teacher First Name is of data type Varchar(100).
Teacher Last Name is of data type Varchar(100).
Period Number is of data type Tinyint.
School Year is of data type Varchar(50).
Period Start Time is of data type Time.
Period End Time is of data type Time.
Teacher First Name: ______
Period Number: ______
Keep your exam routine moving
Get timed mock exams, AI explanations, focused review, and learning insights.
You import two Microsoft Excel tables named Customer and Address into Power Query. Customer contains the following columns: ✑ Customer ID ✑ Customer Name ✑ Phone ✑ Email Address ✑ Address ID Address contains the following columns: ✑ Address ID ✑ Address Line 1 ✑ Address Line 2 ✑ City ✑ State/Region ✑ Country ✑ Postal Code Each Customer ID represents a unique customer in the Customer table. Each Address ID represents a unique address in the Address table. You need to create a query that has one row per customer. Each row must contain City, State/Region, and Country for each customer. What should you do?
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You have five reports and two dashboards in a workspace. You need to grant all organizational users read access to one dashboard and three reports. Solution: You create an Azure Active Directory group that contains all the users. You share each selected report and the one dashboard to the group. Does this meet the goal?
You need to create relationships to meet the reporting requirements of the customer service department. What should you create?
You have a Power BI report that contains three pages named Page1, Page2, and Page3. All the pages have the same slicers. You need to ensure that all the filters applied to Page1 apply to Page1 and Page3 only. What should you do?
You are creating a Power BI report by using Power BI Desktop. You need to include a visual that shows trends and other useful information automatically. The visual must update based on selections in other visuals. Which type of visual should you use?

Start Practicing Now
Download Cloud Pass and start practicing all PL-300: Microsoft Power BI Data Analyst exam questions.