
Practice Test #5
50問と100分の制限時間で実際の試験をシミュレーションしましょう。AI検証済み解答と詳細な解説で学習できます。
AI搭載
3重AI検証済み解答&解説
すべての解答は3つの主要AIモデルで交差検証され、最高の精度を保証します。選択肢ごとの詳細な解説と深い問題分析を提供します。
練習問題
You are developing a solution that will use Azure messaging services. You need to ensure that the solution uses a publish-subscribe model and eliminates the need for constant polling. What are two possible ways to achieve the goal? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You develop a software as a service (SaaS) offering to manage photographs. Users upload photos to a web service which then stores the photos in Azure Storage Blob storage. The storage account type is General-purpose V2. When photos are uploaded, they must be processed to produce and save a mobile-friendly version of the image. The process to produce a mobile-friendly version of the image must start in less than one minute. You need to design the process that starts the photo processing. Solution: Convert the Azure Storage account to a BlockBlobStorage storage account. Does the solution meet the goal?
You need to secure the Shipping Logic App. What should you use?
DRAG DROP - Contoso, Ltd. provides an API to customers by using Azure API Management (APIM). The API authorizes users with a JWT token. You must implement response caching for the APIM gateway. The caching mechanism must detect the user ID of the client that accesses data for a given location and cache the response for that user ID. You need to add the following policies to the policies file: ✑ a set-variable policy to store the detected user identity ✑ a cache-lookup-value policy ✑ a cache-store-value policy ✑ a find-and-replace policy to update the response body with the user profile information To which policy section should you add the policies? To answer, drag the appropriate sections to the correct policies. Each section may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point. Select and Place:
Policy: Set-variable, Policy section: ______
Policy: Cache-lookup-value, Policy section: ______
Policy: Cache-store-value, Policy section: ______
Policy: Find-and-replace, Policy section: ______
HOTSPOT - You are working for Contoso, Ltd. You define an API Policy object by using the following XML markup:
("bodySize"))
For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
The XML segment belongs in the <inbound> section of the policy.
If the body size is >256k, an error will occur.
If the request is http://contoso.com/api/9.2/, the policy will retain the higher version.
外出先でもすべての問題を解きたいですか?
Cloud Passをダウンロード — 模擬試験、学習進捗の追跡などを提供します。
You are creating a hazard notification system that has a single signaling server which triggers audio and visual alarms to start and stop. You implement Azure Service Bus to publish alarms. Each alarm controller uses Azure Service Bus to receive alarm signals as part of a transaction. Alarm events must be recorded for audit purposes. Each transaction record must include information about the alarm type that was activated. You need to implement a reply trail auditing solution. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
DRAG DROP - You are maintaining an existing application that uses an Azure Blob GPv1 Premium storage account. Data older than three months is rarely used. Data newer than three months must be available immediately. Data older than a year must be saved but does not need to be available immediately. You need to configure the account to support a lifecycle management rule that moves blob data to archive storage for data not modified in the last year. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Exhibit:
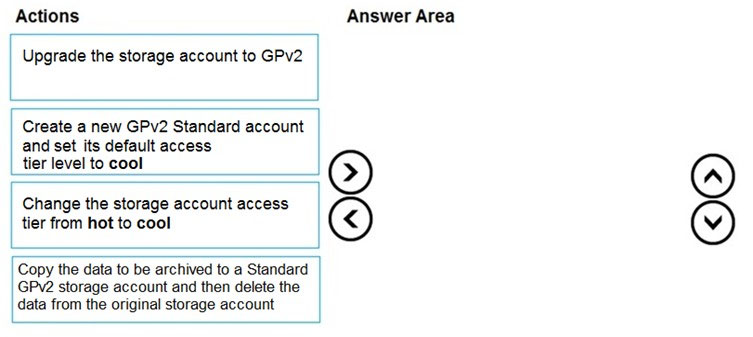
Which actions should you perform to support lifecycle management and lower storage cost?
HOTSPOT - You need to configure Azure Service Bus to Event Grid integration. Which Azure Service Bus settings should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Tier ______
RBAC role ______
You are developing an Azure function that connects to an Azure SQL Database instance. The function is triggered by an Azure Storage queue.
You receive reports of numerous System.InvalidOperationExceptions with the following message:
Timeout expired. The timeout period elapsed prior to obtaining a connection from the pool. This may have occurred because all pooled connections were in use and max pool size was reached.
You need to prevent the exception.
What should you do?
HOTSPOT - You are configuring a development environment for your team. You deploy the latest Visual Studio image from the Azure Marketplace to your Azure subscription. The development environment requires several software development kits (SDKs) and third-party components to support application development across the organization. You install and customize the deployed virtual machine (VM) for your development team. The customized VM must be saved to allow provisioning of a new team member development environment. You need to save the customized VM for future provisioning. Which tools or services should you use? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
Generalize the VM. ______
Store images. ______

今すぐ学習を始める
Cloud Passをダウンロードして、すべてのMicrosoft AZ-204練習問題を利用しましょう。