
Practice Test #3
50問と100分の制限時間で実際の試験をシミュレーションしましょう。AI検証済み解答と詳細な解説で学習できます。
AI搭載
3重AI検証済み解答&解説
すべての解答は3つの主要AIモデルで交差検証され、最高の精度を保証します。選択肢ごとの詳細な解説と深い問題分析を提供します。
練習問題
HOTSPOT - You are building a chatbot that will provide information to users as shown in the following exhibit.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic. NOTE: Each correct selection is worth one point. Hot Area:
The chatbot is showing ______.
The card includes ______.
A customer uses Azure Cognitive Search. The customer plans to enable a server-side encryption and use customer-managed keys (CMK) stored in Azure. What are three implications of the planned change? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
HOTSPOT - You have a Computer Vision resource named contoso1 that is hosted in the West US Azure region. You need to use contoso1 to make a different size of a product photo by using the smart cropping feature. How should you complete the API URL? To answer, select the appropriate options in the answer area. NOTE: Each correct selection is worth one point. Hot Area:
curl -H "Ocp-Apim-Subscription-Key: xxx" / -o "sample.png" -H "Content-Type: application/json" / "______" /vision/v3.1/
/vision/v3.1/______?width=100&height=100&smartCropping=true" /
DRAG DROP -
You train a Custom Vision model used in a mobile app. You receive 1,000 new images that do not have any associated data. You need to use the images to retrain the model. The solution must minimize how long it takes to retrain the model. Which three actions should you perform in the Custom Vision portal? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Review the original DRAG DROP image, then choose the fastest Custom Vision portal workflow for retraining with unlabeled images.
You plan to provision a QnA Maker service in a new resource group named RG1. In RG1, you create an App Service plan named AP1. Which two Azure resources are automatically created in RG1 when you provision the QnA Maker service? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
外出先でもすべての問題を解きたいですか?
Cloud Passをダウンロード — 模擬試験、学習進捗の追跡などを提供します。
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution. After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen. You create a web app named app1 that runs on an Azure virtual machine named vm1. Vm1 is on an Azure virtual network named vnet1. You plan to create a new Azure Cognitive Search service named service1. You need to ensure that app1 can connect directly to service1 without routing traffic over the public internet. Solution: You deploy service1 and a public endpoint, and you configure an IP firewall rule. Does this meet the goal?
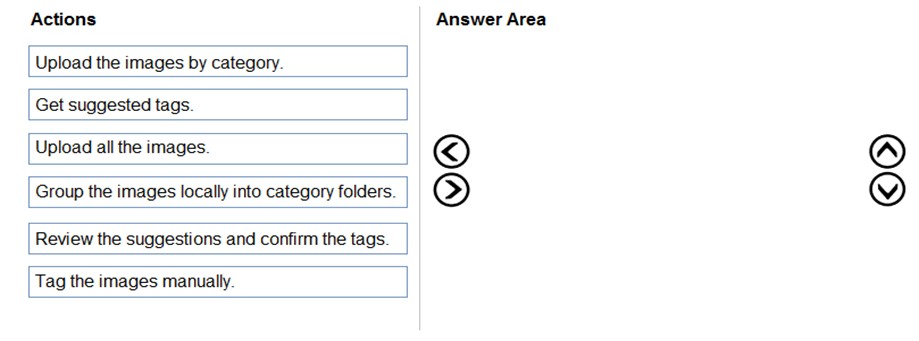
You are developing the smart e-commerce project. You need to implement autocompletion as part of the Cognitive Search solution. Which three actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
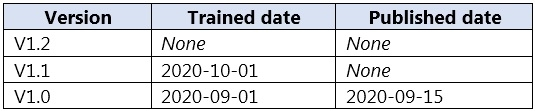
DRAG DROP - You plan to use a Language Understanding application named app1 that is deployed to a container. App1 was developed by using a Language Understanding authoring resource named lu1. App1 has the versions shown in the following table.
You need to create a container that uses the latest deployable version of app1. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. Select and Place:
Run a container that has version set as an environment variable.
Export the model by using the Export as JSON option.
Select v1.1 of app1.
Run a container and mount the model file.
Select v1.0 of app1.
Export the model by using the Export for containers (GZIP) option.
Select v1.2 of app1.
You have receipts that are accessible from a URL. You need to extract data from the receipts by using Form Recognizer and the SDK. The solution must use a prebuilt model. Which client and method should you use?
DRAG DROP - You plan to use containerized versions of the Anomaly Detector API on local devices for testing and in on-premises datacenters. You need to ensure that the containerized deployments meet the following requirements: ✑ Prevent billing and API information from being stored in the command-line histories of the devices that run the container. ✑ Control access to the container images by using Azure role-based access control (Azure RBAC). Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order. NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select. Select and Place:
Create a custom Dockerfile.
Pull the Anomaly Detector container image.
Distribute a docker run script.
Push the image to an Azure container registry.
Build the image.
Push the image to Docker Hub.

今すぐ学習を始める
Cloud Passをダウンロードして、すべてのMicrosoft AI-102練習問題を利用しましょう。