
Practice Test #2
50問と45分の制限時間で実際の試験をシミュレーションしましょう。AI検証済み解答と詳細な解説で学習できます。
AI搭載
3重AI検証済み解答&解説
すべての解答は3つの主要AIモデルで交差検証され、最高の精度を保証します。選択肢ごとの詳細な解説と深い問題分析を提供します。
練習問題
You have a transactional application that stores data in an Azure SQL managed instance. When should you implement a read-only database replica?
Correct. A read-only replica is designed to offload read-heavy workloads such as reporting, dashboards, and ad-hoc queries from the primary transactional database. This reduces contention for CPU/IO and minimizes the risk that long-running SELECT queries will degrade OLTP performance. It’s a classic read scale pattern: keep writes on the primary and direct reads to the replica.
Incorrect. Auditing focuses on tracking events such as logins, schema changes, and data access, typically using Azure SQL Auditing, diagnostic logs, or security tooling. A read-only replica does not provide an auditing trail by itself; it only provides another copy for read queries. You might query a replica for analysis, but it doesn’t replace proper auditing controls.
Incorrect. High availability for a regional outage requires cross-region disaster recovery, such as auto-failover groups or geo-replication to a paired region. A read-only replica is usually within the same region and is intended for read scale and local HA architecture, not for surviving a full regional outage scenario.
Incorrect. Recovery Point Objective (RPO) is about how much data loss is acceptable and is primarily influenced by backup frequency, transaction log backups, and DR replication to another region. A read-only replica used for read scale does not inherently improve RPO; it’s not a substitute for geo-DR or backup strategy.
問題分析
Core concept: A read-only database replica in Azure SQL Managed Instance is used to offload read workloads (queries) from the primary read-write instance. This aligns with the common pattern of separating OLTP (transactional) workloads from heavy read/reporting workloads to protect latency and throughput for transactions. Why the answer is correct: Transactional applications are sensitive to contention (CPU, memory, IO, locks/latches) caused by long-running SELECT queries, reporting, and ad-hoc analytics. Implementing a read-only replica lets you direct reporting queries to a secondary that is continuously synchronized from the primary, so report generation does not compete with the transactional workload. This improves performance predictability and supports the Azure Well-Architected Framework pillars of Performance Efficiency and Reliability by reducing resource contention and stabilizing the primary workload. Key features / how it’s used: In SQL Managed Instance, read scale/read-only replicas are commonly associated with Business Critical architecture (Always On availability groups under the hood). You typically connect to the read-only endpoint (or use application intent=ReadOnly where supported) for reporting/BI queries. The replica is not for writes; it is intended for read-only operations and can be used for near-real-time reporting. It’s also a common best practice to ensure reporting queries are optimized and to use appropriate isolation levels, but the main benefit is workload isolation. Common misconceptions: A read-only replica is not primarily an auditing feature. Auditing is handled by SQL Auditing, Microsoft Purview, or log-based approaches. It’s also not the main mechanism for regional outage protection; that’s addressed with geo-replication, auto-failover groups, or cross-region DR strategies. Finally, a read-only replica does not inherently improve RPO; RPO is driven by backup/restore strategy, log shipping/replication to another region, and DR configuration. Exam tips: For DP-900, map “read-only replica/read scale” to “offload reads/reporting from OLTP.” Map “regional outage/high availability” to geo-redundant designs (failover groups/geo-replication), and map “RPO/RTO” to backup/restore and DR features. If the question mentions reporting without impacting transactions, the read-only replica choice is the best fit.
HOTSPOT - For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
A Microsoft Power BI dashboard is associated with a single workspace.
Yes. In the Power BI service, a dashboard is created within (and owned by) a specific workspace. The workspace acts as the organizational and security boundary for the dashboard, including who can view or edit it. While dashboards can be shared with users outside the workspace (depending on tenant settings, permissions, and sharing method), the dashboard itself still resides in exactly one workspace. Why “No” is wrong: there isn’t a concept of a single dashboard being simultaneously associated with multiple workspaces. If you need the same dashboard-like experience in another workspace, you typically recreate it, use an app to distribute content, or rely on shared datasets/semantic models and separate dashboards per workspace. This workspace association is important for governance and access control, which is why DP-900 expects you to recognize the workspace as the container for dashboards.
A Microsoft Power BI dashboard can only display visualizations from a single dataset.
No. A Power BI dashboard can include tiles pinned from multiple reports, and those reports can be based on different datasets (semantic models). This is one of the key purposes of dashboards: to provide a consolidated view across different subject areas (for example, sales KPIs from one dataset and support ticket KPIs from another). Why “Yes” is wrong: the “single dataset” limitation applies more to certain report behaviors (a report is typically built on one dataset at a time, though it can use composite models and DirectQuery to multiple sources). Dashboards, however, are an aggregation layer of pinned visuals/tiles and are not restricted to a single dataset. On the exam, remember: dashboards = one page, many tiles, potentially many datasets.
A Microsoft Power BI dashboard can display visualizations from a Microsoft Excel workbook.
Yes. Power BI can use Excel workbooks as a data source, and visuals built from that Excel data can be shown on a dashboard. In the Power BI service, dashboard tiles are typically pinned from reports, and those reports can be created from imported Excel data or supported workbook content. "No" is incorrect because Excel is a supported source for Power BI analytics, but the dashboard does not directly render arbitrary Excel content unless it has been brought into Power BI in a supported way.
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
A relational database must be used when ______
Correct answer: D (strong consistency guarantees are required). Relational databases are the default choice when you require strong consistency and ACID transactions (Atomicity, Consistency, Isolation, Durability). These capabilities help ensure data integrity across multiple related tables and rows, enforce constraints (primary/foreign keys), and support transactional workloads where reads must reflect the latest committed writes. In Azure, services like Azure SQL Database provide strong consistency and robust transactional semantics. Why the others are wrong: A (a dynamic schema is required) typically points to non-relational/document databases (for example, Azure Cosmos DB for NoSQL) where schema can evolve without rigid table definitions. B (data will be stored as key/value pairs) is a classic key/value workload, better suited to key/value stores (for example, Cosmos DB key/value patterns, Azure Cache for Redis) rather than a relational engine. C (storing large images and videos) is best handled by object storage such as Azure Blob Storage, which is optimized for unstructured binary data and cost-effective large-scale storage.
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
To configure an Azure Storage account to support both security at the folder level and atomic directory manipulation, ______
Correct answer: A. enable the hierarchical namespace. Enabling hierarchical namespace (HNS) turns the storage account into Azure Data Lake Storage Gen2. This provides real directories and files (not just name prefixes) and supports POSIX-style ACLs that can be applied at directory (folder) and file level. It also enables atomic directory operations such as rename and move, which are important for analytics engines and data pipelines that reorganize partitions/folders. Why the others are wrong: - B (Account kind = BlobStorage): This is a legacy account type and does not provide HNS, directory objects, or ACL-based folder security. - C (Performance = Premium): Premium affects performance characteristics and pricing (e.g., for certain storage account types) but does not add hierarchical namespace or folder ACLs. - D (RA-GRS): Replication improves durability and read availability in a secondary region, but it does not change namespace semantics or enable folder-level security.
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
______ is an object associated with a table that sorts and stores the data rows in the table based on their key values.
Correct answer: A. A clustered index. A clustered index is an index type where the table’s data rows are physically stored in the order of the clustered index key. Because it determines the physical organization of the table, it effectively “sorts and stores the data rows in the table based on their key values.” In Azure SQL Database and SQL Server, a table can have only one clustered index because there is only one physical ordering of the data. Why the others are wrong: - B. FileTable: A specialized feature for storing files and documents with Windows file system semantics while maintaining relational access; it does not define row ordering for a table. - C. A foreign key: A constraint that enforces referential integrity between a child table and a parent table; it does not sort or store rows. - D. A stored procedure: A programmable database object that contains SQL statements and logic; it does not control physical row storage order.
外出先でもすべての問題を解きたいですか?
Cloud Passをダウンロード — 模擬試験、学習進捗の追跡などを提供します。
Your company has a reporting solution that has paginated reports. The reports query a dimensional model in a data warehouse. Which type of processing does the reporting solution use?
Stream processing is used for continuously ingesting and analyzing data in near real time (e.g., IoT telemetry, clickstreams) using services like Azure Stream Analytics or Spark Structured Streaming. Paginated reports querying a dimensional model do not imply continuous event-by-event processing; they typically query curated, stored warehouse data. Therefore, stream processing is not the best fit here.
Batch processing refers to processing data in scheduled chunks (e.g., nightly ETL/ELT loads into a warehouse using Azure Data Factory/Synapse pipelines). While a data warehouse is often populated via batch, the question asks about the reporting solution’s processing type. Querying a dimensional model for reporting is an analytical (OLAP) workload, regardless of whether the warehouse load is batch.
OLAP is designed for analytical queries over large, historical datasets, commonly modeled as facts and dimensions in a data warehouse. Dimensional models enable fast aggregations and slicing/dicing by attributes like time, product, and geography—exactly what reporting solutions use when generating summaries and grouped results. Paginated reports can be a front end, but the processing pattern is OLAP.
OLTP supports day-to-day transactional operations with many concurrent inserts, updates, and deletes (e.g., order entry, banking transactions). OLTP schemas are typically highly normalized to reduce redundancy and enforce integrity. A dimensional model in a data warehouse is the opposite pattern—denormalized for analytics—so OLTP is not the correct processing type for this reporting scenario.
問題分析
Core concept: This question tests recognition of analytics workloads and the difference between OLAP (analytics) and OLTP (transactions), plus how dimensional models and paginated reports fit into a data warehousing architecture. Why the answer is correct: Paginated reports (for example, SQL Server Reporting Services/Power BI Report Builder paginated reports) are designed for operational-style, pixel-perfect reporting, but when they query a dimensional model in a data warehouse (facts and dimensions, star/snowflake schema, measures, hierarchies), the underlying processing pattern is analytical. Dimensional models are optimized for aggregations, slicing/dicing, and read-heavy queries across large historical datasets—classic Online Analytical Processing (OLAP). Even if the report is “paginated,” the data source and query patterns (grouping, summarization, time intelligence, drill-down by dimensions) align with OLAP. Key features and best practices: OLAP workloads typically use a data warehouse or analytical engine (e.g., Azure Synapse Analytics dedicated SQL pool, Azure SQL Database for smaller warehouses, or semantic models in Power BI/Analysis Services). They emphasize columnar storage/MPP (where applicable), partitioning, pre-aggregations, and star schema design to improve scan and aggregation performance. From an Azure Well-Architected Framework perspective, OLAP aligns with Performance Efficiency (optimize for large scans/aggregations), Cost Optimization (separate compute/storage where possible, scale appropriately), and Reliability (ETL/ELT pipelines that load curated dimensional data). Common misconceptions: Many learners associate “reports” with batch processing because warehouses are often loaded in batches. However, the question asks what type of processing the reporting solution uses, not how the warehouse is loaded. The reporting queries are analytical (OLAP). Another trap is choosing OLTP because paginated reports can be used for operational reporting; but the presence of a dimensional model in a data warehouse strongly indicates OLAP. Exam tips: On DP-900, treat “dimensional model,” “data warehouse,” “facts and dimensions,” “aggregations,” and “historical analysis” as OLAP signals. Treat “orders, inserts/updates, point lookups, concurrency” as OLTP signals. Batch vs stream describes data ingestion/processing cadence, not the analytical vs transactional nature of the query workload.
DRAG DROP - Match the terms to the appropriate descriptions. To answer, drag the appropriate term from the column on the left to its description on the right. Each term may be used once, more than once, or not at all. NOTE: Each correct match is worth one point. Select and Place:
A database object that holds data
The correct match is table. A table is the primary database object used to store data in rows and columns, making it the persistent container for relational data. A view does not normally store the underlying data; it stores a query definition. An index helps the database find data faster, but it is not the main object used to hold the business data itself.
A database object whose content is defined by a query
The correct match is view. A view is a database object whose contents are defined by a SELECT query against one or more underlying tables. It presents a virtual result set rather than acting as the primary storage location for the data. A table stores the actual rows, while an index is used to improve query performance rather than define content through a query.
A database object that helps improve the speed of data retrieval
The correct match is index. An index is a database object that improves the speed of data retrieval by providing an efficient structure for locating rows. This reduces the need for full table scans in many queries. A table stores the data itself, and a view defines a query-based presentation of data, so neither is the best match for retrieval optimization.
HOTSPOT - To complete the sentence, select the appropriate option in the answer area. Hot Area:
A key/value data store is optimized for ______.
Correct answer: B. simple lookups. A key/value data store is optimized for retrieving a value when you already know the key (for example, get session:12345 or get userPref:alice). The data model is intentionally minimal: the store typically treats the value as an opaque blob (string/JSON/binary), and the primary operation is fast GET/SET by key. This design enables very low-latency access and easy horizontal scaling, which is why key/value stores are commonly used for caching, session state, and quick configuration reads. Why the other options are wrong: A. enforcing constraints is a relational database strength (primary/foreign keys, check constraints). Key/value stores generally do not enforce schema or referential integrity. C. table joins are a relational capability; key/value stores do not support joins because there are no related tables. D. transactions (especially multi-record ACID transactions) are typically associated with relational systems. Some key/value systems offer limited atomic operations, but transactions are not the primary optimization goal in the DP-900 context.
HOTSPOT - For each of the following statements, select Yes if the statement is true. Otherwise, select No. NOTE: Each correct selection is worth one point. Hot Area:
The Azure Cosmos DB API is configured separately for each database in an Azure Cosmos DB account.
No. In Azure Cosmos DB, the API is configured at the Azure Cosmos DB account level, not separately per database. When you create a Cosmos DB account, you select the API (such as Azure Cosmos DB for NoSQL, MongoDB, Cassandra, Gremlin, or Table). All databases and containers created within that account use that same API model and endpoint/protocol. Why “Yes” is wrong: it implies you can have different APIs per database inside one account (for example, one database using NoSQL and another using MongoDB). That is not how Cosmos DB is structured for the exam: mixing APIs requires separate Cosmos DB accounts. This is an important design consideration because the API choice influences SDKs, query language/semantics, and compatibility, and it is part of the account’s foundational configuration.
Partition keys are used in Azure Cosmos DB to optimize queries.
Yes. Partition keys are used to optimize queries and operations in Azure Cosmos DB by enabling efficient routing and distribution. When a query includes the partition key (typically an equality predicate on the partition key value), Cosmos DB can target the specific logical partition that contains the relevant items. This avoids scanning or fanning out across multiple partitions, reducing RU consumption and improving latency. Why this matters: partitioning is primarily for scalability and performance. It distributes data and throughput across physical partitions, but it also directly impacts query efficiency. Queries that do not specify the partition key may become cross-partition queries, which generally cost more RUs and can be slower. While indexes also optimize queries, the partition key is a key mechanism for query targeting and is therefore a correct statement in the context of Cosmos DB fundamentals.
Items contained in the same Azure Cosmos DB logical partition can have different partition keys.
No. Items contained in the same Azure Cosmos DB logical partition cannot have different partition key values. A logical partition is defined as the set of items that share the same partition key value within a container. Therefore, if two items have different partition key values, they belong to different logical partitions. Why “Yes” is wrong: it contradicts the definition of a logical partition. Cosmos DB uses the partition key value to group items; that grouping is what enables targeted reads/writes and efficient single-partition queries/transactions (where supported). Practically, this is why choosing a good partition key is critical: it determines how items are grouped, affects data distribution (avoiding hot partitions), and influences whether common queries and operations can be served from a single logical partition versus requiring cross-partition fan-out.
DRAG DROP - Match the datastore services to the appropriate descriptions.
Which option shows the correct matching for the image below?
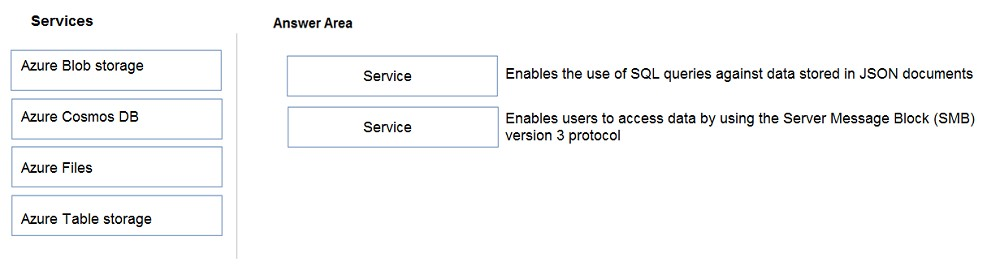
Azure Blob storage stores objects such as files and images, but it is not the service used for SQL-style queries against JSON documents.
Correct. Azure Cosmos DB stores JSON documents and supports SQL-like queries through its NoSQL/Core API. Azure Files provides managed file shares that can be accessed by using the SMB protocol, including SMB 3.x.
Azure Table storage is a key/attribute NoSQL store, not the SQL-style JSON document service. Azure Cosmos DB is not the SMB file share service.
Azure Cosmos DB is correct for JSON document querying, but Azure Blob storage is not accessed as an SMB file share. SMB access points to Azure Files.
問題分析
This question focuses on two strong keywords: JSON documents with SQL-style queries, and SMB version 3 access. JSON document querying points to Azure Cosmos DB, while SMB file share access points to Azure Files.
重要な学習ポイント
- JSON documents plus SQL-like queries -> Azure Cosmos DB
- SMB file share access -> Azure Files
- Blob storage is object storage, not an SMB file share

今すぐ学習を始める
Cloud Passをダウンロードして、すべてのMicrosoft DP-900練習問題を利用しましょう。