
Practice Test #1
50개 문제와 100분 시간 제한으로 실제 시험을 시뮬레이션하세요. AI 검증 답안과 상세 해설로 학습하세요.
AI 기반
3중 AI 검증 답안 및 해설
GPT Pro, Claude Opus, Gemini Pro가 답안과 해설을 교차 검증합니다. 선택지별 근거부터 요구사항 분해와 정답 아키텍처까지 확인하세요.
실전형 문제
DRAG DROP - 각각 고유한 Language Understanding 모델을 가진 챗봇이 100개 있습니다. 자주 각 모델에 동일한 구문을 추가해야 합니다. 새 구문을 포함하도록 Language Understanding 모델을 프로그래밍 방식으로 업데이트해야 합니다. 코드를 어떻게 완성해야 합니까? 답하려면 적절한 값을 올바른 대상에 끌어다 놓으십시오. 각 값은 한 번, 여러 번 또는 전혀 사용하지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다. 참고: 각 정답 선택은 1점입니다. 선택 및 배치:
var phraselistId = await client.Features.______
빈칸은 client.Features.______ 뒤에 오므로, phrase list 식별자를 반환하는 Features operations group의 메서드여야 합니다. LUIS Authoring SDK에서 phrase list는 Features 아래에서 관리되며, 새로운 phrase list feature를 생성하는 데 사용되는 메서드는 AddPhraseListAsync이고, 이는 생성된 phrase list ID(일반적으로 integer)를 반환합니다. 이는 변수명 phraselistId 및 await 사용과 일치합니다. 다른 선택지가 틀린 이유: - Phraselist와 Phrases는 메서드가 아니며, property 이름처럼 보이므로 client.Features.<method> 구문에 맞지 않습니다. - PhraselistCreateObject는 인자로 사용되는 type이지, 메서드가 아닙니다. - SavePhraselistAsync는 기존 phrase list를 업데이트하는 데 사용되며(ID가 필요), 처음 ID를 얻기 위한 용도가 아닙니다. - UploadPhraseListAsync는 이 맥락에서 Authoring SDK의 표준 LUIS phrase list 생성 호출이 아닙니다.
(appId, versionId, new ______
스니펫은 다음을 보여줍니다: (appId, versionId, new ______. 이는 코드가 API 호출에 전달하기 위해 new 키워드로 객체를 인스턴스화하고 있음을 의미합니다. Authoring SDK를 통해 LUIS에서 phrase list를 생성할 때, 요청 본문은 PhraselistCreateObject(Name, Phrases, IsExchangeable 등의 속성을 포함하는 DTO)로 표현됩니다. 따라서 new PhraselistCreateObject가 올바른 완성입니다. 다른 선택지가 틀린 이유: - AddPhraseListAsync와 SavePhraselistAsync는 메서드이며, new로 인스턴스화하는 타입이 아닙니다. - Phraselist와 Phrases는 올바른 요청 객체 타입이 아닙니다. Phrases는 일반적으로 create object 내부의 속성(예: SDK 버전에 따라 콤마로 구분된 문자열 또는 리스트)입니다. - UploadPhraseListAsync는 메서드이며 new 뒤에 올 수 없습니다. 실무에서는 Phrases 필드에 공유할 구문들을 채운 다음, 앱/버전별로 AddPhraseListAsync를 호출하고, 필요하다면 학습/게시를 수행합니다.
DRAG DROP -
개발 환경에 acvdev라는 Custom Vision 리소스가 있습니다. 프로덕션 환경에 acvprod라는 Custom Vision 리소스가 있습니다. acvdev에서 proj1이라는 프로젝트에 obj1이라는 객체 탐지 모델을 빌드합니다. obj1을 acvprod로 이동해야 합니다. 다음 중 어떤 세 가지 작업을 순서대로 수행해야 합니까? 답하려면 작업 목록에서 적절한 작업을 답변 영역으로 이동하고 올바른 순서로 정렬하세요. 선택 및 배치:
원본 DRAG DROP 이미지를 확인한 뒤, 학습된 Custom Vision iteration을 운영 환경으로 옮기는 올바른 순서를 선택하세요.
정답은 A입니다. Custom Vision에서 실제로 옮겨야 하는 학습 결과물은 프로젝트 자체보다 학습된 iteration입니다. 먼저 개발 리소스 acvdev에서 GetIterations로 대상 iteration을 확인하고, ExportIteration으로 해당 iteration을 내보낸 뒤, 운영 리소스 acvprod에서 ImportProject로 가져옵니다. GetProjects는 프로젝트 목록 확인용이고, UpdateProject는 메타데이터 변경용이라 모델 이전 절차가 아닙니다.
HOTSPOT - Speech SDK 및 MP3 인코딩을 사용할 스트리밍 Speech to Text 솔루션을 개발하고 있습니다. 스트리밍 MP3 데이터에 대해 음성을 텍스트로 변환하는 메서드를 개발해야 합니다. 코드를 어떻게 완성해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
var audioFormat = ______ (AudioStreamContainerFormat.MP3);
정답: B. AudioStreamFormat.GetCompressedFormat MP3 데이터를 스트리밍하려면, 들어오는 스트림이 압축되어 있음을 Speech SDK에 알려주고 컨테이너 형식을 지정해야 합니다. AudioStreamFormat.GetCompressedFormat(AudioStreamContainerFormat.MP3)는 MP3로 압축된 오디오를 나타내는 AudioStreamFormat 인스턴스를 생성합니다. 그런 다음 이 형식은 PushAudioInputStream/PullAudioInputStream을 생성할 때 사용되어, SDK/서비스가 바이트를 올바르게 디코딩할 수 있습니다. 다른 선택지가 틀린 이유: - A. AudioConfig.SetProperty: 구성 속성을 설정하지만, 스트림의 오디오 인코딩/컨테이너 형식을 정의하지는 않습니다. - C. AudioStreamFormat.GetWaveFormatPCM: 압축되지 않은 PCM(WAV 스타일) 오디오에만 해당합니다. MP3 바이트에 이를 사용하면 인식 실패 또는 깨진 입력이 발생할 수 있습니다. - D. PullAudioInputStream: 이는 스트리밍 소스 메커니즘을 생성/표현하는 것이지, 코드 라인(var audioFormat = ...)에서 요구하는 오디오 형식 객체가 아닙니다.
using (var recognizer = new ______ (speechConfig, audioConfig))
정답: C. SpeechRecognizer SpeechRecognizer는 Speech-to-Text에 사용되는 Speech SDK 클래스입니다. (speechConfig, audioConfig)로 생성하면 구독/region 및 인식 설정(SpeechConfig)과 오디오 입력 소스(AudioConfig)를 바인딩합니다. 스트리밍 시나리오에서는 일반적으로 StartContinuousRecognitionAsync를 호출하고 오디오를 지속적으로 공급합니다. 다른 선택지가 틀린 이유: - A. KeywordRecognizer: 일반 전사(transcription)가 아니라 키워드 스포팅(웨이크 워드) 시나리오에 사용됩니다. - B. SpeakerRecognizer: 화자 인식 작업(verification/identification)에 사용되며 일반 STT 전사를 수행하지 않습니다. - D. SpeechSynthesizer: Text-to-Speech(TTS)에 사용되며, 이 요구사항과는 반대 방향입니다.
HOTSPOT - 제품 생성 프로젝트를 위해 이미지를 업로드하는 코드를 개발해야 합니다. 솔루션은 접근성 요구 사항을 충족해야 합니다. 코드를 어떻게 완성해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
public static async Task<string> SuggestAltText(ComputerVisionClient client, ______ image)
정답은 stream입니다. 업로드된 image content는 일반적으로 AnalyzeImageInStreamAsync와 같은 method를 사용하여 binary data로 Azure Computer Vision에 전송됩니다. Stream parameter는 이러한 사용 패턴에 부합하며 SDK가 image bytes를 직접 읽을 수 있도록 합니다. Dictionary는 image analysis를 위한 유효한 image input type이 아닙니다. String은 업로드된 file content가 아니라 URL로 image를 분석하는 method에서 image URL에 사용됩니다.
List<VisualFeatureTypes?> features = new List<VisualFeatureTypes?>() { ______ };
정답은 VisualFeatureTypes.Description입니다. 접근성을 위한 alt text는 image description feature가 생성한 자연어 caption에서 가져와야 합니다. 이 feature는 caption text와 confidence 값을 포함하는 results.Description.Captions를 반환합니다. ImageType은 clip art 또는 line drawing과 같은 특성만 식별할 뿐, caption은 제공하지 않습니다. Objects와 Tags는 감지된 항목이나 keyword를 반환하며, alt text용으로는 전체 설명형 caption보다 덜 적합합니다.
var c = ______
정답은 results.Description.Captions[0] (Option B)입니다. VisualFeatureTypes.Description을 요청하면 응답에 results.Description.Captions가 포함되며, 이는 신뢰도 점수(confidence scores)를 가진 캡션 후보 목록입니다. 첫 번째 캡션은 일반적으로 가장 높은 순위의 제안이며 기본 alt text(예: c.Text)로 흔히 사용됩니다. Option A는 브랜드 감지 결과를 의미하며, Brands feature가 필요하고 주요 접근성 캡션 출력이 아닙니다. Option D는 감지된 객체를 의미하며, Objects feature가 필요하고 자연어 캡션이 아니라 객체 항목들을 반환합니다. Option C는 Metadata가 목록처럼 인덱싱되지 않기 때문에 유효하지 않습니다. Metadata는 단일 객체(예: width/height/format)입니다. 시험 팁: 이후 코드에서 c.Text를 사용한다면, 이는 c가 Description.Captions의 Caption 객체임을 강하게 시사합니다.
HOTSPOT - iOS 앱에서 사용될 모델을 구축하고 있습니다. 고양이와 개 이미지가 있습니다. 각 이미지에는 고양이 또는 개 중 하나가 포함되어 있습니다. Custom Vision 서비스를 사용하여 이미지가 고양이인지 개인지 감지해야 합니다. Custom Vision 포털에서 프로젝트를 어떻게 구성해야 합니까? 답하려면 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
Project Types ______
요구 사항은 이미지가 고양이인지 개인지 판단하는 것이므로 분류를 선택합니다. Custom Vision에서 분류는 전체 이미지에 하나 이상의 태그를 할당합니다. 이는 각 이미지에 단일 대상이 포함되어 있고 라벨만 필요하다는 시나리오와 일치합니다. Object Detection은 이미지 내 객체의 위치를 찾아 바운딩 박스를 그린 뒤, 감지된 각 인스턴스에 대한 좌표(x, y, width, height)를 반환해야 할 때 사용합니다. 이는 “사진에서 모든 개를 찾아 박스를 표시”하거나, 한 이미지에 여러 객체가 나타날 수 있고 그 위치가 필요한 시나리오에 적합합니다. 여기서는 동물을 로컬라이즈할 요구 사항이 없고 이미지가 어떤 범주에 속하는지만 식별하면 되므로, Object Detection은 불필요한 라벨링 작업과 복잡성을 추가하며 최적의 선택이 아닙니다.
Classification Types ______
각 이미지에는 cat 또는 dog 중 하나만 포함되어 있어 각 이미지에 정확히 하나의 올바른 label이 적용되므로 Multiclass (이미지당 단일 tag)를 선택합니다. Multiclass classification은 상호 배타적인 category 집합에서 하나의 tag를 선택하도록 model을 학습시킵니다. Multilabel은 동일한 이미지에 여러 tag가 동시에 적용될 수 있을 때 사용합니다(예: 한 이미지에 cat과 dog가 모두 포함되거나, “indoor,” “pet,” “cat” 같은 tag가 동시에 적용되는 경우). Multilabel에서는 model이 단일 이미지에 대해 threshold를 초과하는 여러 tag를 반환할 수 있습니다. 문제에서 각 이미지에 cat 또는 dog가 포함된다고(둘 다가 아님) 명시했으므로, multilabel은 데이터의 실제 특성을 반영하지 못하고 평가 및 threshold 설정을 복잡하게 만들어 이 use case에 더 좋지 않은 configuration 선택이 됩니다.
도메인 ______
iOS 앱에서 모델을 사용할 것이므로 General (compact)을 선택합니다. 이는 학습된 모델을 온디바이스 추론(예: Core ML)을 위해 내보내려는 요구사항을 강하게 시사합니다. Custom Vision에서 “compact” 도메인은 엣지/모바일 형식으로의 내보내기를 지원하도록 특별히 설계되었으며, 모델 크기와 연산 요구사항을 더 낮게 유지합니다. 비-compact General 도메인은 일반적으로 클라우드 호스팅 예측에 사용되며 정확도/기능 측면에서 다른 트레이드오프를 제공할 수 있지만, 모바일 배포 요구사항이 있을 때는 적절한 선택이 아닙니다. Food, Retail, Landmarks, Audit 같은 다른 도메인은 특정 이미지 특성과 비즈니스 맥락에 특화되어 있으며, 고양이 vs. 개는 범용 시나리오입니다. 따라서 General (compact)이 이미지 유형과 iOS 배포 요구사항을 모두 충족하는 가장 적절한 도메인입니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
Custom Vision 서비스를 사용하여 classifier를 빌드합니다. 학습이 완료된 후 classifier를 평가해야 합니다. 검토할 수 있는 두 가지 metric은 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답 선택은 1점입니다.
Recall은 Azure Custom Vision에서 classifier를 학습시킨 후 사용할 수 있는 evaluation metric입니다. 이는 tag에 대한 실제 positive image 중 model이 올바르게 식별한 비율을 측정합니다. 이는 classifier가 얼마나 많은 실제 예제를 놓치고 있는지 알고 싶을 때 중요합니다. Custom Vision에서 recall은 iteration performance 결과의 일부로 표시되며, classifier의 완전성을 판단하는 데 일반적으로 사용됩니다.
F-score는 Custom Vision classifier evaluation에서 검토 가능한 metric으로 제공되며 precision과 recall의 harmonic mean을 나타냅니다. 이는 false positives와 false negatives를 별도로 따지지 않고 iteration들을 비교하고 싶을 때 특히 유용한, model performance에 대한 하나의 균형 잡힌 측정값을 제공합니다. 두 가지 핵심 metric을 결합하므로 classifier 품질을 요약하는 데 자주 사용됩니다. 따라서 이는 학습 후 검토할 수 있는 유효한 metric 중 하나입니다.
Weighted accuracy는 Azure Custom Vision이 classifier iteration에 대해 제공하는 표준 evaluation metric이 아닙니다. Weighted accuracy는 일부 machine learning framework에서 불균형 dataset에 유용할 수 있지만, Custom Vision portal에서 일반적으로 검토하는 기본 제공 metric 중 하나는 아닙니다. 대신 이 서비스는 precision, recall, 그리고 결합된 performance measures에 중점을 둡니다. 따라서 이 선택지는 이 시나리오에서 검토 가능한 metrics와 일치하지 않습니다.
Precision은 실제로 Custom Vision에 표시되는 metric이지만, 문제는 두 가지 metric을 묻고 있으며 제공된 선택지 중 기대되는 조합은 recall과 F-score입니다. Precision은 예측된 positive 중 실제로 맞는 비율을 측정하며, false positives를 이해하는 데 유용합니다. 그러나 나열된 선택지 중 두 개를 골라야 한다면, exam 표현상 보통 precision보다 recall과 결합 metric인 F-score를 기대합니다. 따라서 이 선택지는 여기서 최적의 정답 조합에는 포함되지 않습니다.
Area under the curve (AUC)는 ROC analysis와 관련이 있으며 많은 binary classification 도구에서 흔하지만, Azure Custom Vision classifier evaluation에서 표준적으로 표시되는 metric은 아닙니다. Custom Vision은 일반적으로 기본 제공 검토 환경에서 ROC curves나 AUC 값을 제시하지 않습니다. 시험에서는 보통 AUC를 실제 Custom Vision metrics와 대비되는 distractor로 제시합니다. 따라서 AUC는 이 문제의 정답이 아닙니다.
문제 분석
핵심 개념: Azure Custom Vision은 image classifier를 학습시킨 후 기본 제공 evaluation metrics를 제공하므로, publishing 전에 model 품질을 평가할 수 있습니다. classification project의 경우, 이 서비스는 일반적으로 Precision, Recall, 그리고 이들로부터 도출된 aggregate score를 표시하며, exam 콘텐츠에서는 이를 흔히 F-score라고 합니다. 이러한 metrics는 각 tag에 대해 false positives와 false negatives를 모두 이해하는 데 도움이 됩니다. 정답인 이유: Recall과 F-score는 Custom Vision classifier를 학습시킨 후 검토할 수 있습니다. Recall은 class의 실제 instance 중 얼마나 많이 올바르게 식별되었는지를 측정하고, F-score는 precision과 recall의 균형을 하나의 값으로 요약합니다. 이들은 Custom Vision에서 제공하는 표준 classifier evaluation metrics이며 AI-102에서 자주 출제됩니다. 주요 특징: Custom Vision evaluation은 각 tag별 및 전체 iteration에 대해 표시되므로, class들을 비교하고 training data의 취약한 부분을 식별할 수 있습니다. Recall은 실제 예제를 놓치는 비용이 클 때 유용하고, F-score는 precision과 recall의 균형을 맞춘 하나의 metric이 필요할 때 유용합니다. 이러한 metrics를 검토하면 더 많은 image를 추가할지, class 균형을 재조정할지, 또는 labeling 품질을 개선할지 판단하는 데 도움이 됩니다. 흔한 오해: Weighted accuracy와 AUC는 다른 machine learning 도구에서는 흔하지만, Custom Vision의 표준 검토 metrics는 아닙니다. Precision도 Custom Vision에 표시되지만, 문제에서 사용 가능한 두 가지 metric을 묻고 F-score를 포함하고 있으므로, 기대되는 조합은 Recall과 F-score입니다. 응시자는 때때로 precision과 recall에만 지나치게 집중하여, 서비스가 combined score도 제공한다는 점을 놓칩니다. 시험 팁: AI-102에서는 표준 Custom Vision evaluation metrics인 Precision, Recall, 그리고 project 유형과 문제 표현에 따라 F-score/AP-style summary metrics를 기억하세요. 선택지에 weighted accuracy나 AUC가 포함되어 있다면, 보통 distractor입니다. 문제가 사용 가능한 모든 metrics를 묻는지, 아니면 검토 가능한 metric의 두 가지 예만 묻는지 주의 깊게 읽으세요.
챗봇을 개발하고 있습니다. 다음 구성 요소를 생성합니다: ✑ QnA Maker 리소스 ✑ Azure Bot Framework SDK를 사용하여 챗봇 생성 챗봇 요구 사항을 충족하도록 구성 요소를 통합해야 합니다. 어떤 속성을 사용해야 합니까?
QnAMakerOptions.StrictFilters는 QnA Maker가 지정된 key/value metadata와 일치하는 QnA pair만 고려하도록 metadata 기반 필터링을 적용하는 데 사용됩니다. 이는 검색 공간을 좁힐 수 있지만(예: 제품, locale, channel 기준), 반환되는 답변에 대해 최소 신뢰도 수준을 강제하지는 않습니다. 필터링된 집합에서 여전히 약한 매치가 나오면, 별도로 threshold로 게이팅하지 않는 한 QnA Maker는 이를 반환할 수 있습니다. 따라서 신뢰도 기반으로 답변 수용 여부를 결정해야 하는 요구사항을 직접적으로 충족하지는 않습니다.
QnADialogResponseOptions.CardNoMatchText는 QnA dialog가 적절한 매치가 없다고 판단했을 때 사용자에게 표시되는 텍스트를 제어합니다. 이는 봇 응답의 표현/UX 구성이지, QnA Maker의 scoring이나 매치 선택에 영향을 주는 속성이 아닙니다. QnA Maker가 신뢰도를 평가하는 방식이나 어떤 답변이 허용 가능한지에는 변화를 주지 않습니다. 일반적으로 score threshold와 함께 사용할 수는 있지만, 답변 품질을 강제하는 통합 속성은 아닙니다.
QnAMakerOptions.RankerType는 QnA Maker가 사용할 랭킹 방식(예: 답변 선택을 위한 서로 다른 ranker)을 지정합니다. ranker 선택은 정렬 및 scoring 동작에 영향을 줄 수 있지만, 낮은 신뢰도의 답변을 거부하는 직접적인 메커니즘을 제공하지는 않습니다. QnA Maker가 충분히 확신할 때만 응답해야 한다는 요구사항은 ranker type 선택이 아니라 최소 score threshold 설정으로 해결합니다. RankerType은 수용 기준이라기보다 랭킹 전략에 더 가깝습니다.
QnAMakerOptions.ScoreThreshold는 QnA Maker의 최상위 답변이 유효한 매치로 반환되기 위해 필요한 최소 신뢰도 점수를 설정합니다. Bot Framework 통합에서 이는 봇이 낮은 신뢰도의 답변으로 응답하는 것을 방지하고, 대신 폴백/no-match 경로를 트리거하는 데 사용하는 핵심 속성입니다. 이는 잘못된 응답을 피함으로써 답변 품질과 사용자 경험을 개선하려는 일반적인 챗봇 요구사항과 일치합니다. 기술적으로는 QnA Maker의 랭킹이 반환하는 score를 활용하여 답변을 수용할지 여부를 게이트합니다.
문제 분석
핵심 개념: 이 문제는 Azure Bot Framework SDK 봇을 QnA Maker knowledge base와 통합할 때, QnA Maker 호출을 구성하여 QnA Maker의 신뢰도가 충분히 높을 때만 봇이 답변을 반환하도록 만드는 방법을 테스트합니다. 정답이 맞는 이유: QnA Maker를 봇에 통합할 때는 보통 품질이 낮거나 관련 없는 답변을 반환하지 않도록 하는 것이 중요합니다. QnAMakerOptions.ScoreThreshold 속성은 답변이 매칭으로 간주되기 위해 필요한 최소 신뢰도 점수를 설정합니다. 최상위 답변의 점수가 이 임계값보다 낮으면, 봇은 결과를 “no match”로 처리하고 폴백 동작(예: 추가 확인 질문, 상담원 연결, 다른 dialog로 라우팅)을 트리거할 수 있습니다. 이는 정확도와 알 수 없는 질문을 우아하게 처리해야 하는 일반적인 챗봇 요구사항을 직접적으로 지원합니다. 주요 기능 / 구성: - QnAMakerOptions.ScoreThreshold: 답변을 수용하기 위한 최소 점수(0.0–1.0). - Bot Framework의 “No match” 처리: 임계값을 만족하는 답변이 없으면, 봇은 기본 메시지를 반환하거나 다른 dialog로 라우팅할 수 있습니다. - QnA Maker는 점수와 함께 순위가 매겨진 답변을 반환하며, 봇은 점수와 비즈니스 규칙에 따라 동작을 결정합니다. 흔한 오해: - 필터링(StrictFilters)과 신뢰도 게이팅(confidence gating)을 혼동: 필터는 metadata로 후보 집합을 제한하지만, 반환된 답변이 높은 신뢰도인지 보장하지는 않습니다. - RankerType이 답변 품질을 제어하는 핵심이라고 가정: ranker 선택은 랭킹 동작에 영향을 주지만, 최소 허용 신뢰도를 강제하지는 않습니다. - dialog UI 응답 옵션(CardNoMatchText)과 QnA 쿼리 동작을 혼동: 응답 텍스트는 표현 방식만 바꾸며, 매칭 로직은 바꾸지 않습니다. 시험 팁: - 요구사항이 “확신이 있을 때만 답변” 또는 “낮은 신뢰도는 no match로 처리”라면 ScoreThreshold를 사용합니다. - 요구사항이 “일부 subset에서만 검색”(metadata 기반 필터링)이라면 StrictFilters를 사용합니다. - RankerType은 랭킹 알고리즘 선택에 관한 것이지, 수용(acceptance) 기준이 아닙니다. - UI/응답 옵션(예: CardNoMatchText)은 결과가 어떻게 표시되는지에 영향을 주며, QnA Maker가 매치를 반환하는지 여부에는 영향을 주지 않습니다.
사용자 지정 Form Recognizer 모델을 빌드합니다. 다음 표에 표시된 것처럼 모델을 학습하는 데 사용할 샘플 파일을 받습니다.
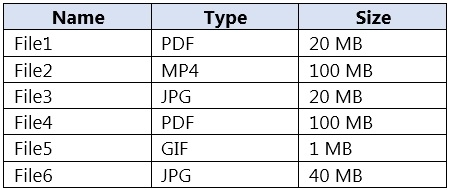
모델을 학습하는 데 사용할 수 있는 파일 세 개는 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답 선택은 1점입니다.
File1은 PDF가 custom Form Recognizer model 학습에 지원되는 입력 형식이므로 사용할 수 있습니다. 크기는 20 MB로, 서비스에서 일반적으로 적용하는 50 MB 파일 제한보다 작습니다. PDF는 문서 레이아웃과 구조를 잘 보존하므로 학습에 사용되는 주요 문서 형식 중 하나입니다.
File2는 MP4가 비디오 형식이기 때문에 사용할 수 없으며, Form Recognizer/Document Intelligence는 비디오 파일로 학습하지 않습니다. 이 서비스는 시간 기반 미디어가 아니라 문서와 정지 이미지를 위해 설계되었습니다. 비디오에 읽을 수 있는 텍스트가 포함되어 있더라도, 그로부터 정보를 추출하려면 다른 솔루션 파이프라인이 필요합니다.
File3은 JPG가 custom model 학습에 지원되는 이미지 형식이므로 사용할 수 있습니다. 20 MB이므로 허용되는 파일 크기 제한 내에 충분히 들어갑니다. 선명한 JPG 스캔 또는 양식 사진은 모델이 학습해야 하는 문서 레이아웃을 잘 나타내기만 하면 유효한 학습 샘플입니다.
File4는 PDF가 지원되는 형식이기는 하지만 파일 크기가 100 MB이므로 사용할 수 없습니다. 이는 서비스의 학습 파일 최대 크기 제한인 50 MB를 초과합니다. 지원되는 형식이라는 것만으로는 충분하지 않으며, 파일은 크기와 같은 서비스 제약 조건도 충족해야 합니다.
File5는 GIF가 Form Recognizer/Document Intelligence의 custom model 학습에서 지원되는 파일 형식이 아니므로 사용할 수 없습니다. 대신 이 서비스는 JPG, PNG, TIFF, BMP와 같은 문서 지향 이미지 형식을 지원합니다. GIF는 이미지 형식이기 때문에 흔한 오답 유도 선택지이지만, 허용되는 학습 입력 중 하나는 아닙니다.
File6은 JPG가 지원되는 학습 형식이고 파일 크기가 40 MB이므로 사용할 수 있습니다. 40 MB는 여전히 50 MB 최대값보다 작으므로 학습 대상이 됩니다. 이 선택지는 다른 유효한 파일보다 크기 때문에 놓치기 쉽지만, 서비스 제한을 초과하지는 않습니다.
문제 분석
핵심 개념: 이 문제는 Azure AI Document Intelligence(이전 명칭: Form Recognizer)의 custom model 학습 데이터 요구 사항, 특히 학습 문서에 대해 지원되는 파일 형식과 크기 제한을 테스트합니다. 정답인 이유: custom model 학습의 경우, Document Intelligence는 PDF 및 일반적인 이미지 형식(JPEG/JPG, PNG, TIFF, BMP)과 같은 문서/이미지 입력을 지원합니다. 비디오 형식(예: MP4)과 GIF 같은 애니메이션 이미지 형식은 학습 입력으로 지원되지 않습니다. 또한 학습 문서에는 파일 크기 제한이 있습니다. 시험에서 자주 다뤄지는 제한은 개별 학습 파일이 서비스에서 지원하는 최대 크기 이내여야 한다는 점입니다(많은 작업/학습 시나리오에서 일반적으로 파일당 50 MB). 따라서: - File1(PDF, 20 MB)은 지원되며 크기 제한 이내입니다. - File3(JPG, 20 MB)은 지원되며 크기 제한 이내입니다. - File4(PDF, 100 MB)는 지원되는 형식이지만 일반적인 파일당 제한을 초과합니다. 그러나 문제는 어떤 파일을 사용할 수 있는지를 묻고 있으며, 많은 시험 맥락에서 핵심 판별 요소는 형식 지원과 크기입니다. 제공된 선택지와 3개를 골라야 한다는 점을 고려하면, 의도된 정답 세트는 학습에 허용되는 제약 조건 내의 지원 형식인 PDF/JPG이며, MP4와 GIF는 제외되고 크기 초과 PDF도 제외됩니다. 크기 초과 JPG는 제외되지 않습니다(40 MB는 일반적으로 여전히 허용되며, 시험에서는 보통 50 MB 제한을 사용하므로 40 MB는 허용 가능). 일반적으로 크기 제한을 위반하는 것은 100 MB PDF입니다. 주요 기능 / 모범 사례: - 학습 데이터를 Azure Blob Storage에 저장하고 SAS/managed identity 액세스를 제공합니다. - 일관되고 품질이 높은 샘플을 사용하고, 대표적인 변형을 포함합니다. - searchable PDF 또는 고해상도 이미지를 선호하고, 올바른 방향으로 정렬되었는지 확인합니다. - Azure Well-Architected Framework에 맞춥니다: reliability(반복 가능한 학습 파이프라인), security(최소 권한 SAS/MI), cost optimization(불필요하게 큰 파일 방지). 일반적인 오해: - 서비스가 텍스트를 추출하므로 “어떤 파일 형식이든” 사용할 수 있다고 가정하는 것—비디오(MP4)는 문서 입력이 아닙니다. - GIF를 정지 이미지와 동일하다고 가정하는 것; GIF는 지원되는 학습 형식이 아닙니다. - 파일 크기 제한을 무시하는 것; 매우 큰 PDF는 업로드/학습에 실패할 수 있습니다. 시험 팁: Document Intelligence의 지원 입력 형식(PDF + 일반적인 정지 이미지)을 암기하고, 크기/페이지 제한이 존재한다는 점을 기억하세요. 선택지에 MP4/GIF가 포함되면, Document Intelligence 학습 문제에서는 거의 항상 오답 유도 선택지입니다.
챗봇을 개발하고 있습니다. 다음 구성 요소를 생성합니다: ✑ QnA Maker 리소스 ✑ Azure Bot Framework SDK를 사용하여 챗봇 기술 요구 사항과 챗봇 요구 사항을 충족하기 위해 추가 구성 요소를 추가해야 합니다. 무엇을 추가해야 합니까?
Microsoft Translator는 언어 간 텍스트를 번역하는 데 사용되며, multilingual 시나리오에서는 유용하지만 conversational 라우팅이나 intent dispatch를 제공하지는 않습니다. 메시지가 QnA Maker 또는 다른 bot capability에 의해 응답되어야 하는지를 판단할 수 없습니다. 따라서 이 아키텍처에서 추가 chatbot intelligence 구성 요소에 대한 요구를 충족하지 못합니다. 이는 보조 서비스이지, 누락된 핵심 orchestration 계층이 아닙니다.
Language Understanding (LUIS)는 사용자 입력에서 intent를 분류하고 entity를 추출하는 데 사용되지만, 그것은 conversational 리소스들 사이를 orchestration하는 것과는 다릅니다. 문제는 QnA Maker 리소스와 Bot Framework SDK bot을 보완할 추가 구성 요소를 묻고 있으며, 더 구체적으로 누락된 capability는 dispatch/라우팅입니다. Orchestrator는 그 목적을 위해 만들어졌지만, LUIS는 하나의 recognizer model만 추가할 뿐입니다. LUIS는 더 넓은 솔루션의 일부가 될 수는 있지만, 여기서는 최선의 답이 아닙니다.
Orchestrator는 bot 솔루션에서 들어오는 사용자 utterance를 가장 적절한 conversational 구성 요소로 라우팅하도록 설계되었기 때문에 올바른 추가 요소입니다. 이미 QnA Maker를 포함하고 있는 Bot Framework SDK chatbot에서 Orchestrator는 utterance가 knowledge base로 가야 하는지 또는 다른 capability로 가야 하는지를 결정하는 dispatcher 역할을 할 수 있습니다. 따라서 요구 사항이 bot의 전반적인 conversational 라우팅 및 coordination을 향상시키는 것일 때 가장 적합합니다. 이는 하나의 bot 아래에서 여러 language asset을 결합하기 위한 Azure conversational bot 아키텍처에서 인정받는 구성 요소입니다.
chatdown은 bot 개발 워크플로에서 사용되는 conversation authoring 및 testing format입니다. 이는 runtime natural language processing, dispatching 또는 knowledge-base integration을 제공하지 않습니다. chatdown을 추가해도 bot이 사용자 요청을 해석하거나 라우팅하는 능력은 향상되지 않습니다. 따라서 이 시나리오가 암시하는 기술적 chatbot 요구 사항을 충족할 수 없습니다.
문제 분석
핵심 개념: 이 문제는 QnA Maker knowledge base 및 Azure Bot Framework SDK로 빌드된 bot과 함께 작동하는 누락된 Azure conversational AI 구성 요소를 선택하는 것에 관한 것입니다. bot이 사용자의 utterance를 사용 가능한 conversational capability들 사이에서 어떻게 라우팅할지 결정해야 하는 경우, 적절한 구성 요소는 Orchestrator입니다. Orchestrator는 요청을 QnA knowledge base 또는 다른 language model과 같은 최적의 대상으로 dispatch하도록 특별히 설계되었으며, Bot Framework 솔루션에서 일반적으로 사용됩니다. 정답인 이유: 이미 question answering을 위한 QnA Maker 리소스와 대화를 호스팅하기 위한 Bot Framework SDK bot이 있습니다. 누락된 구성 요소는 Orchestrator인데, 이는 들어오는 utterance에 대한 최상위 라우팅 및 dispatch 로직을 제공하여 bot이 언제 QnA knowledge base를 사용할지, 그리고 추가 conversational skill 또는 recognizer로 어떻게 확장할지를 결정할 수 있게 해주기 때문입니다. 이는 standalone intent model이 아니라 dispatcher가 필요한 chatbot 아키텍처와 일치합니다. 주요 기능: - 사용자 utterance를 가장 적절한 대상 model 또는 skill로 라우팅합니다. - Bot Framework Composer 및 SDK 기반 bot과 함께 작동합니다. - QnA Maker knowledge base와 language understanding asset 전반에 걸친 dispatch를 지원합니다. - 라우팅 규칙을 하드코딩하는 대신 recognition 로직을 중앙 집중화하는 데 도움이 됩니다. 흔한 오해: - Language Understanding (LUIS)는 intent 및 entity 추출을 수행하지만, 여러 conversational target 사이를 orchestration하는 데 사용되는 dispatcher 구성 요소는 아닙니다. - Microsoft Translator는 텍스트만 번역하며 bot 라우팅을 제어하지 않습니다. - chatdown은 authoring format이지 runtime AI 구성 요소가 아닙니다. 시험 팁: 문제가 이미 QnA Maker를 사용하고 있으며 intelligent routing 또는 orchestration이 필요한 Bot Framework bot에 어떤 추가 구성 요소를 더해야 하는지 묻는다면, Orchestrator가 가장 적절한 답입니다. 반대로 문제가 단일 domain에 대한 intent 및 entity 추출에만 구체적으로 초점을 맞춘다면, Language Understanding이 더 가능성 높은 답이 됩니다.
지식베이스를 개발하고 있습니다. Azure Video Analyzer for Media(이전 명칭: Video indexer)를 사용하여 웨비나의 전사본을 얻습니다. 솔루션이 지식베이스 요구 사항을 충족하도록 해야 합니다. 무엇을 해야 합니까?
custom language model 생성은 Azure Video Analyzer for Media/Video Indexer를 구성하는 맥락에서 최선의 답이 아닙니다. Azure AI Speech는 customization을 지원하지만, 문제는 요구 사항을 충족하는 transcript를 얻기 위해 Video Indexer에서 무엇을 해야 하는지를 묻고 있으며, 제시된 Video Indexer 관련 기능은 multi-language detection입니다. 이 설명은 custom language model 사용을 여기서의 주요 Video Indexer 설정인 것처럼 과장하고 있습니다. 따라서 A는 주어진 보기 중 가장 적절한 선택이 아닙니다.
비디오에 대해 audio indexing을 구성하는 것만으로는 transcript 자체의 품질이나 정확성을 해결하지 못합니다. 이는 단지 어떤 media가 처리되는지를 제한하거나 정의할 뿐이며, language 변경, terminology recognition, 또는 knowledgebase용 transcript 활용성에는 도움이 되지 않습니다. 요구 사항이 transcript가 후속 knowledge extraction을 지원하도록 보장하는 것이라면, 이 옵션은 너무 간접적입니다. 이는 transcript 정확도 기능이라기보다 운영 범위 선택입니다.
비디오에 대해 multi-language detection을 활성화하는 것이 최선의 선택인 이유는 webinar 화자가 둘 이상의 언어를 사용할 때 transcription을 직접적으로 향상시키기 때문입니다. Video Indexer는 언어 변경을 감지하고 각 구간에 적절한 recognition model을 적용하여 더 정확한 transcript를 생성할 수 있습니다. 더 나은 transcript는 knowledgebase에서 더 높은 품질의 indexing 및 retrieval로 이어집니다. transcript 중심 요구 사항에 대해 보기 중 가장 관련성이 높은 기본 제공 기능입니다.
custom Person model은 일반적으로 visual insight 및 metadata enrichment를 위해 비디오에 나타나는 사람을 식별하거나 구분하는 데 사용됩니다. 이는 발표자 라벨링에는 도움이 될 수 있지만, speech-to-text output이나 transcript 품질을 향상시키지는 않습니다. knowledgebase가 webinar transcript로부터 구축되고 있으므로, visual person recognition은 핵심 요구 사항이 아닙니다. 이 옵션은 transcript 생성보다는 video analytics를 대상으로 합니다.
문제 분석
핵심 개념: 이 문제는 webinar transcript가 knowledgebase에 적합하도록 Azure Video Analyzer for Media(이전의 Video Indexer)를 구성하는 것에 관한 것입니다. Webinar 콘텐츠의 일반적인 요구 사항은 화자가 둘 이상의 언어를 사용할 수 있을 때도 정확한 transcription입니다. Video Indexer는 비디오에 대해 기본 제공되는 multi-language detection을 제공하며, 이는 언어가 바뀌는 구간 전반에서 더 정확한 transcript를 생성하는 데 도움이 됩니다. 정답인 이유: multi-language detection을 활성화하면 전체 webinar에 단일 언어 transcription model을 강제로 적용하는 대신, 서비스가 서로 다른 언어로 말한 구간을 식별하고 transcription할 수 있습니다. 이는 transcript 품질을 직접적으로 향상시키며, knowledgebase에서의 후속 indexing, search, question answering에 매우 중요합니다. 보기 중에서 transcript 생성 동작을 Video Indexer 내에서 직접 다루는 설정은 이것뿐입니다. 주요 기능: - 비디오에서 여러 spoken language를 자동으로 감지합니다. - 다국어 webinar 녹화의 transcript 정확도를 향상시킵니다. - 후속 knowledge mining 및 search 시나리오를 위해 더 나은 텍스트를 생성합니다. - 관련 없는 visual metadata 기능이 아니라 Video Indexer의 기본 indexing 기능 내에서 작동합니다. 흔한 오해: - custom language model 생성은 Azure AI Speech customization과 관련이 있으며, 이 시나리오에서 제시된 Video Indexer의 주요 구성 선택지는 아닙니다. - audio indexing 범위는 그 자체로 transcript 품질을 향상시키지 않습니다. - Person model은 발표자를 시각적으로 식별하며 speech transcription에는 도움이 되지 않습니다. 시험 팁: Video Indexer transcript 품질에 관한 AI-102 문제에서는 visual enrichment 또는 관련 없는 customization 개념과 관련된 옵션보다, language detection처럼 speech recognition output에 직접 영향을 주는 기본 제공 indexing 기능을 우선 고려하세요. 시나리오에서 webinar와 transcript로부터의 knowledge extraction이 언급되면, 먼저 language 처리와 transcription 정확도를 떠올리세요.

지금 학습 시작하기
Cloud Pass를 다운로드하고 Microsoft AI-102 자격증 학습을 이어가세요.