Plan and Manage an Azure AI Solution출제율 23%

시험 준비 허브
Microsoft · Associate
Microsoft AI-102
Designing and Implementing a Microsoft Azure AI Solution
무료 문제 체험
문제를 직접 풀고 해설 품질을 확인하세요
정답을 고른 뒤 선택지별 근거, 핵심 학습 포인트와 관련 서비스를 바로 확인할 수 있습니다.
1
문제 1
DRAG DROP - 각각 고유한 Language Understanding 모델을 가진 챗봇이 100개 있습니다. 자주 각 모델에 동일한 구문을 추가해야 합니다. 새 구문을 포함하도록 Language Understanding 모델을 프로그래밍 방식으로 업데이트해야 합니다. 코드를 어떻게 완성해야 합니까? 답하려면 적절한 값을 올바른 대상에 끌어다 놓으십시오. 각 값은 한 번, 여러 번 또는 전혀 사용하지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다. 참고: 각 정답 선택은 1점입니다. 선택 및 배치:
파트 1:
var phraselistId = await client.Features.______
파트 2:
(appId, versionId, new ______
2
문제 2
다음 요구 사항을 충족하는 chatbot을 구축해야 합니다: ✑ chit-chat, knowledge base, 그리고 multilingual models를 지원 ✑ 사용자 메시지에 대해 sentiment analysis를 수행 ✑ 최적의 language model을 자동으로 선택 chatbot에 무엇을 통합해야 합니까?
3
문제 3
당신은 e-commerce 플랫폼을 위한 Language Understanding 모델을 구축하고 있습니다. 청구지 주소를 캡처하기 위한 entity를 구성해야 합니다. 청구지 주소에 어떤 entity type을 사용해야 합니까?
4
문제 4
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수도 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 정답이 두 개 이상 있을 수 있으며, 다른 세트에는 정답이 없을 수도 있습니다. 이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 표시되지 않습니다. Language Understanding service를 사용하여 language model을 빌드합니다. 이 language model은 FindContact라는 intent를 사용하여 연락처 목록에서 정보를 검색하는 데 사용됩니다. 대화형 전문가가 학습에 사용할 다음 phrase 목록을 제공합니다. ✑ London의 연락처를 찾아줘. ✑ Seattle에 아는 사람이 누구야? ✑ Ukraine의 연락처를 검색해줘. Language Understanding에서 phrase list를 구현해야 합니다. 솔루션: location에 대한 새 intent를 생성합니다. 이것이 목표를 충족합니까?
5
문제 5
HOTSPOT - 감정 분석 및 광학 문자 인식(OCR)을 수행하는 데 사용할 새 리소스를 만들어야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다. ✑ 단일 키와 엔드포인트를 사용하여 여러 서비스에 액세스합니다. ✑ 향후 사용할 수 있는 서비스에 대한 청구를 통합합니다. ✑ 향후 Computer Vision 사용을 지원합니다. 새 리소스를 만들기 위해 HTTP 요청을 어떻게 완료해야 합니까? 답하려면 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
6
문제 6
다음 HTTP 요청을 성공적으로 실행합니다. POST https://management.azure.com/subscriptions/18c51a87-3a69-47a8-aedc-a54745f708a1/resourceGroups/RG1/providers/ Microsoft.CognitiveServices/accounts/contoso1/regenerateKey?api-version=2017-04-18 Body{"keyName": "Key2"} 요청의 결과는 무엇입니까?
7
문제 7
HOTSPOT - 텍스트 분석에 사용될 Azure Cognitive Services 서비스의 컨테이너화된 버전을 배포할 계획입니다. 서비스의 endpoint URI로 https://contoso.cognitiveservices.azure.com 을 구성하고, Text Analytics Sentiment Analysis 컨테이너의 최신 버전을 pull합니다. Docker를 사용하여 Azure virtual machine에서 컨테이너를 실행해야 합니다. 명령을 어떻게 완성해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
파트 1:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 1 \ ______ \
파트 2:
Eula=accept \ Billing= ______ \
8
문제 8
DRAG DROP - Face API를 사용하여 샘플 이미지 기반으로 특정 인물의 사진을 찾는 사진 애플리케이션을 개발하고 있습니다. 사진을 찾기 위한 POST 요청을 생성해야 합니다. 요청을 어떻게 완성해야 합니까? 답하려면 적절한 값을 올바른 대상에 끌어다 놓으십시오. 각 값은 한 번, 여러 번 또는 전혀 사용하지 않을 수 있습니다. 콘텐츠를 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다. 참고: 각 올바른 선택은 1점입니다. 선택 및 배치:
파트 1:
POST {Endpoint}/face/v1.0/______
파트 2:
"mode": "______"
9
문제 9
HOTSPOT - Face API를 사용하는 애플리케이션을 개발합니다. person group에 여러 이미지를 추가해야 합니다. 코드를 어떻게 완성해야 합니까? 답하려면 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
파트 1:
using (______ t = File.OpenRead(imagePath))
파트 2:
await faceClient.PersonGroupPerson.______(personGroupId, personId, t);
10
문제 10
HOTSPOT - Computer Vision client library를 사용할 애플리케이션을 개발하고 있습니다. 애플리케이션에는 다음 코드가 있습니다.
public async TaskAnalyzeImage(ComputerVisionClient client, string localImage)
{
List features = new List()
{
VisualFeatureTypes.Description,
VisualFeatureTypes.Tags,
};
using (Stream imageStream = File.OpenRead(localImage))
{
try
{
ImageAnalysis results = await client.AnalyzeImageInStreamAsync(imageStream, features);
foreach (var caption in results.Description.Captions)
{
Console.WriteLine($"{caption.Text} with confidence {caption.Confidence}");
}
foreach (var tag in results.Tags)
{
Console.WriteLine($"{tag.Name} {tag.Confidence}");
}
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
}
}
다음 각 문에 대해, 문이 참이면 Yes를 선택합니다. 그렇지 않으면 No를 선택합니다. 참고: 각 정답 선택은 1점입니다. 핫 영역:
파트 1:
이 코드는 얼굴 인식을 수행합니다.
파트 2:
이 코드는 태그와 해당 신뢰도(confidence)를 나열합니다.
파트 3:
이 코드는 로컬 파일 시스템에서 파일을 읽습니다.
11
문제 11
Azure Cognitive Search에서 인덱싱을 위한 관리 포털로 사용되는 웹 앱을 배포합니다. 이 앱은 primary admin key를 사용하도록 구성되어 있습니다. 보안 검토 중에 검색 인덱스에 대한 무단 변경을 발견합니다. primary access key가 유출되었을 가능성이 있다고 의심합니다. 인덱스 관리 endpoint에 대한 무단 액세스를 방지해야 합니다. 솔루션은 다운타임을 최소화해야 합니다. 다음으로 무엇을 해야 합니까?
12
문제 12
HOTSPOT - 다음 전시물에 표시된 것처럼 사용자에게 정보를 제공하는 chatbot을 구축하고 있습니다.
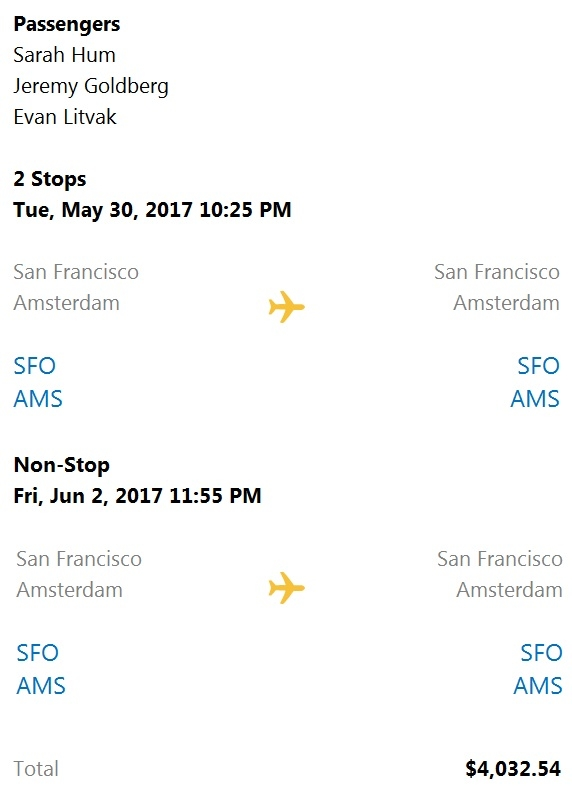
드롭다운 메뉴를 사용하여 그래픽에 제시된 정보를 기반으로 각 문장을 완성하는 답안을 선택하십시오. 참고: 각 정답 선택은 1점입니다. Hot Area:
파트 1:
챗봇이 ______을(를) 표시하고 있습니다.
파트 2:
이 카드는 ______을(를) 포함합니다.
13
문제 13
HOTSPOT - 챗봇의 설계를 검토하고 있습니다. 해당 챗봇에는 다음 조각을 포함하는 language generation 파일이 있습니다.
Greet(user)
- ${Greeting()}, ${user.name} 다음 각 진술에 대해, 진술이 참이면 Yes를 선택합니다. 그렇지 않으면 No를 선택합니다. 참고: 각 정답 선택은 1점입니다. 핫 영역:
파트 1:
${user.name}는 prompt를 사용하여 사용자 이름을 가져옵니다.
파트 2:
Greet()는 language generation template의 이름입니다.
파트 3:
${Greeting()}는 language generation 파일에 있는 템플릿을 참조하는 것입니다.
14
문제 14
DRAG DROP - Face API에 대한 호출을 개발하고 있습니다. 이 호출은 employeefaces라는 기존 목록에서 유사한 얼굴을 찾아야 합니다. employeefaces 목록에는 60,000개의 이미지가 포함되어 있습니다. HTTP 요청의 본문을 어떻게 완성해야 합니까? 답하려면 적절한 값을 올바른 대상에 끌어다 놓으십시오. 각 값은 한 번, 여러 번 또는 전혀 사용하지 않을 수 있습니다. 내용을 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다. 참고: 각 올바른 선택은 1점입니다. 선택 및 배치:
파트 1:
"______": "employeefaces",
파트 2:
"mode": "______"
15
문제 15
HOTSPOT - 텍스트 처리 솔루션을 개발하고 있습니다. 다음 메서드를 개발합니다.
static void GetKeyPhrases(TextAnalyticsClient textAnalyticsClient, string text)
{
var response = textAnalyticsClient.ExtractKeyPhrases(text);
Console.WriteLine("Key phrases:");
foreach (string keyphrase in response.Value)
{
Console.WriteLine($"\t{keyphrase}");
}
}
다음 코드를 사용하여 메서드를 호출합니다. GetKeyPhrases(textAnalyticsClient, "the cat sat on the mat"); 다음 각 문장에 대해, 문장이 참이면 Yes를 선택합니다. 그렇지 않으면 No를 선택합니다. 참고: 각 정답 선택은 1점입니다. Hot Area:
파트 1:
이 호출은 입력 문자열에서 핵심 구문을 추출하여 콘솔에 출력합니다.
파트 2:
출력에는 다음 단어들이 포함됩니다: the, cat, sat, on, and mat.
파트 3:
출력에는 핵심 구문에 대한 신뢰도 수준이 포함됩니다.
16
문제 16
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 이 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 정답이 둘 이상 있을 수 있으며, 다른 세트에는 정답이 없을 수도 있습니다. 이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 표시되지 않습니다. Language Understanding service를 사용하여 language model을 빌드합니다. 이 language model은 FindContact라는 intent를 사용하여 연락처 목록에서 정보를 검색하는 데 사용됩니다. 대화형 전문가가 학습에 사용할 다음 문구 목록을 제공합니다. ✑ London에 있는 연락처를 찾아줘. ✑ Seattle에 아는 사람이 누구야? ✑ Ukraine에 있는 연락처를 검색해줘. Language Understanding에서 phrase list를 구현해야 합니다. 솔루션: FindContact intent에 새 pattern을 만듭니다. 이것이 목표를 충족합니까?
17
문제 17
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수도 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 정답이 둘 이상 있을 수 있으며, 다른 세트에는 정답이 없을 수도 있습니다. 이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 표시되지 않습니다. Custom Vision 모델을 학습하여 꽃의 종을 식별하는 애플리케이션을 개발합니다. 새로운 꽃 종의 이미지를 받습니다. 새 이미지를 분류기에 추가해야 합니다. 솔루션: 새 이미지를 추가한 다음 Smart Labeler 도구를 사용합니다. 이것이 목표를 충족합니까?
18
문제 18
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 정답이 둘 이상일 수 있으며, 다른 질문 세트에는 정답이 없을 수도 있습니다. 이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 표시되지 않습니다. Custom Vision 모델을 학습하여 꽃의 종을 식별하는 애플리케이션을 개발합니다. 새로운 꽃 종의 이미지를 받습니다. 새 이미지를 분류기에 추가해야 합니다. 솔루션: 새 이미지와 레이블을 기존 모델에 추가합니다. 모델을 다시 학습한 다음 모델을 게시합니다. 이것이 목표를 충족합니까?
19
문제 19
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 이 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 정답이 두 개 이상 있을 수 있으며, 다른 세트에는 정답이 없을 수도 있습니다. 이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 표시되지 않습니다. Custom Vision 모델을 학습하여 꽃의 종을 식별하는 애플리케이션을 개발합니다. 새로운 꽃 종의 이미지를 받습니다. 새 이미지를 분류기에 추가해야 합니다. 솔루션: 새 모델을 만든 다음 새 이미지와 레이블을 업로드합니다. 이것이 목표를 충족합니까?
20
문제 20
HOTSPOT - 영국 영어(English (United Kingdom))로 진행되는 강의를 녹음하는 서비스를 개발하고 있습니다. translated text와 language identifier를 받는 AppendToTranscriptFile이라는 메서드가 있습니다. 참석자에게 각자의 언어로 강의 transcript를 제공하는 코드를 개발해야 합니다. 지원되는 언어는 English, French, Spanish, German입니다. 코드를 어떻게 완성해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
파트 1:
var lang = new List<string> ______
파트 2:
using var recognizer = new ______ (config, audioConfig);
시험 도메인
출제 비중을 기준으로 먼저 학습할 영역을 정하세요.
Implement Generative AI Solutions출제율 18%
Implement an Agentic Solution출제율 8%
Implement Computer Vision Solutions출제율 13%
Implement Natural Language Processing Solutions출제율 19%
Implement Knowledge Mining and Information Extraction Solutions출제율 19%
다른 Microsoft 자격증












지금 학습 시작하기
Cloud Pass를 다운로드하여 Microsoft AI-102 전체 학습을 이어가세요.