
Practice Test #3
50개 문제와 100분 시간 제한으로 실제 시험을 시뮬레이션하세요. AI 검증 답안과 상세 해설로 학습하세요.
AI 기반
3중 AI 검증 답안 및 해설
GPT Pro, Claude Opus, Gemini Pro가 답안과 해설을 교차 검증합니다. 선택지별 근거부터 요구사항 분해와 정답 아키텍처까지 확인하세요.
실전형 문제
HOTSPOT - 다음 전시물에 표시된 것처럼 사용자에게 정보를 제공하는 chatbot을 구축하고 있습니다.
드롭다운 메뉴를 사용하여 그래픽에 제시된 정보를 기반으로 각 문장을 완성하는 답안을 선택하십시오. 참고: 각 정답 선택은 1점입니다. Hot Area:
챗봇이 ______을(를) 표시하고 있습니다.
이 카드는 ______을(를) 포함합니다.
고객이 Azure Cognitive Search를 사용합니다. 고객은 서버 측 암호화를 활성화하고 Azure에 저장된 customer-managed keys (CMK)를 사용하려고 합니다. 계획된 변경의 영향은 무엇입니까? 정답은 세 가지입니다. 각 정답은 완전한 해결책을 제시합니다. 참고: 각 정답 선택은 1점입니다.
HOTSPOT - West US Azure region에서 호스팅되는 contoso1이라는 Computer Vision 리소스가 있습니다. smart cropping 기능을 사용하여 contoso1로 제품 사진의 크기를 다른 크기로 만들어야 합니다. API URL을 어떻게 완성해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
curl -H "Ocp-Apim-Subscription-Key: xxx" / -o "sample.png" -H "Content-Type: application/json" / "______" /vision/v3.1/
/vision/v3.1/______?width=100&height=100&smartCropping=true" /
DRAG DROP -
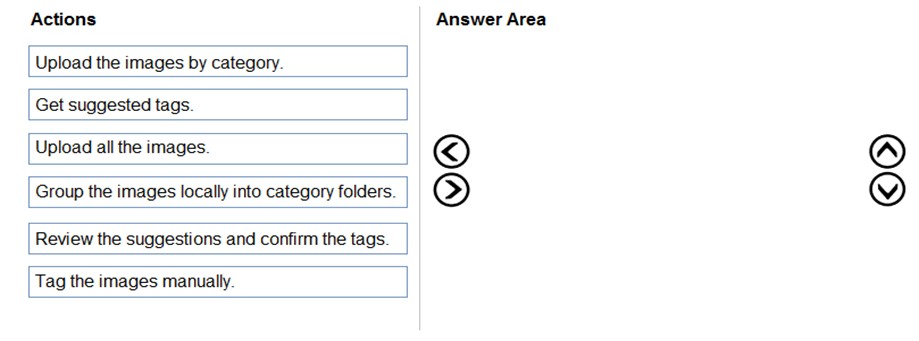
모바일 앱에서 사용되는 Custom Vision 모델을 학습합니다. 연결된 데이터가 없는 새 이미지 1,000장을 받습니다. 이미지를 사용하여 모델을 다시 학습해야 합니다. 솔루션은 모델을 다시 학습하는 데 걸리는 시간을 최소화해야 합니다. Custom Vision 포털에서 수행해야 하는 세 가지 작업은 무엇입니까? 답하려면 작업 목록에서 적절한 작업을 답변 영역으로 이동하고 올바른 순서로 배열하십시오. 선택 및 배치:
원본 DRAG DROP 이미지를 확인한 뒤, 라벨이 없는 이미지로 가장 빠르게 재학습하는 Custom Vision 포털 작업 순서를 선택하세요.
새 리소스 그룹 RG1에 QnA Maker 서비스를 프로비저닝할 계획입니다. RG1에서 AP1이라는 이름의 App Service plan을 생성합니다. QnA Maker 서비스를 프로비저닝할 때 RG1에 자동으로 생성되는 Azure 리소스 두 가지는 무엇입니까? 각 정답은 솔루션의 일부를 제시합니다. 참고: 각 정답 선택은 1점입니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 시리즈의 각 질문에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 정답이 둘 이상 있을 수 있으며, 다른 세트에는 정답이 없을 수도 있습니다. 이 섹션에서 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 표시되지 않습니다. Azure virtual machine인 vm1에서 실행되는 app1이라는 web app을 생성합니다. Vm1은 vnet1이라는 Azure virtual network에 있습니다. service1이라는 새 Azure Cognitive Search 서비스를 생성할 계획입니다. public internet을 통해 트래픽을 라우팅하지 않고 app1이 service1에 직접 연결할 수 있도록 해야 합니다. 솔루션: service1과 public endpoint를 배포하고 IP firewall rule을 구성합니다. 이것이 목표를 충족합니까?
스마트 e-commerce 프로젝트를 개발하고 있습니다. Cognitive Search 솔루션의 일부로 자동 완성을 구현해야 합니다. 어떤 세 가지 작업을 수행해야 합니까? 각 정답은 솔루션의 일부를 제시합니다. 참고: 각 정답 선택은 1점입니다.
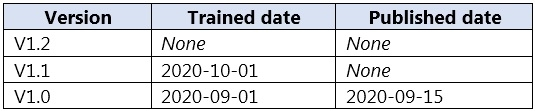
DRAG DROP - 컨테이너에 배포된 app1이라는 Language Understanding 애플리케이션을 사용할 계획입니다. App1은 lu1이라는 Language Understanding authoring resource를 사용하여 개발되었습니다. App1에는 다음 표에 표시된 버전이 있습니다.
app1의 최신 배포 가능한 버전을 사용하는 컨테이너를 만들어야 합니다. 어떤 세 가지 작업을 순서대로 수행해야 합니까? 답하려면 작업 목록에서 적절한 작업을 답 영역으로 이동하고 올바른 순서로 정렬하십시오. Select and Place:
버전이 environment variable로 설정된 컨테이너를 실행합니다.
Export as JSON 옵션을 사용하여 모델을 내보냅니다.
app1의 v1.1을 선택합니다.
컨테이너를 실행하고 모델 파일을 마운트합니다.
app1의 v1.0을 선택합니다.
Export for containers (GZIP) 옵션을 사용하여 모델을 내보냅니다.
app1의 v1.2를 선택합니다.
URL에서 액세스할 수 있는 영수증이 있습니다. Form Recognizer 및 SDK를 사용하여 영수증에서 데이터를 추출해야 합니다. 솔루션은 prebuilt model을 사용해야 합니다. 어떤 client와 method를 사용해야 합니까?
DRAG DROP - 테스트를 위해 로컬 디바이스와 온-프레미스 datacenter에서 Anomaly Detector API의 containerized 버전을 사용할 계획입니다. 다음 요구 사항을 containerized 배포가 충족하도록 해야 합니다: ✑ container를 실행하는 디바이스의 command-line history에 billing 및 API 정보가 저장되지 않도록 방지합니다. ✑ Azure role-based access control (Azure RBAC)을 사용하여 container image에 대한 액세스를 제어합니다. 어떤 네 가지 작업을 순서대로 수행해야 합니까? 답하려면 작업 목록에서 적절한 작업을 답변 영역으로 이동하고 올바른 순서로 정렬하십시오. 참고: 정답 선택지의 순서는 하나 이상이 올바를 수 있습니다. 선택한 올바른 순서에 대해서는 모두 점수를 받습니다. 선택 및 배치:
사용자 지정 Dockerfile을 생성합니다.
Anomaly Detector 컨테이너 이미지를 pull합니다.
docker run 스크립트를 배포합니다.
이미지를 Azure container registry에 푸시합니다.
이미지를 빌드합니다.
이미지를 Docker Hub에 push합니다.

지금 학습 시작하기
Cloud Pass를 다운로드하고 Microsoft AI-102 자격증 학습을 이어가세요.