
Practice Test #1
50개 문제와 100분 시간 제한으로 실제 시험을 시뮬레이션하세요. AI 검증 답안과 상세 해설로 학습하세요.
AI 기반
3중 AI 검증 답안 및 해설
GPT Pro, Claude Opus, Gemini Pro가 답안과 해설을 교차 검증합니다. 선택지별 근거부터 요구사항 분해와 정답 아키텍처까지 확인하세요.
실전형 문제
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 일부입니다. 시리즈의 각 문제에는 제시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 문제 세트에는 둘 이상의 올바른 솔루션이 있을 수 있지만, 다른 문제 세트에는 올바른 솔루션이 없을 수도 있습니다. 이 섹션의 문제에 답한 후에는 해당 문제로 돌아갈 수 없습니다. 따라서 이러한 문제는 검토 화면에 표시되지 않습니다. 귀하는 Azure Storage blob 데이터를 처리하기 위한 HTTP 트리거 Azure Function app을 개발합니다. 이 app은 blob의 output binding을 사용하여 트리거됩니다. 이 app은 4분 후에도 계속 timeout됩니다. 이 app은 blob 데이터를 처리해야 합니다. app이 timeout되지 않고 blob 데이터를 처리하도록 해야 합니다. 솔루션: Durable Function async pattern을 사용하여 blob 데이터를 처리합니다. 이 솔루션이 목표를 충족합니까?
HOTSPOT - 음식 배달 비용을 결제하는 데 사용되는 web service가 있습니다. 이 web service는 데이터 저장소로 Azure Cosmos DB를 사용합니다. 사용자가 tip 금액을 설정할 수 있도록 하는 새 기능을 추가할 계획입니다. 새 기능에서는 Cosmos DB의 document에 tip이라는 속성이 반드시 존재하고 숫자 값을 포함해야 합니다. web service를 사용하는 기존 website와 mobile app이 많이 있으며, 이들은 한동안 tip 속성을 설정하도록 업데이트되지 않을 것입니다. trigger를 어떻게 완성해야 합니까? 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
var r = ______
if (______) {
r.______
DRAG DROP - 귀하는 주문을 처리하기 위해 Azure Function을 사용하는 software as a service (SaaS) 회사의 개발자입니다. 현재 Azure Function은 Azure Storage queue에 의해 트리거되는 Azure Function app에서 실행됩니다. 귀하는 Kubernetes-based Event Driven Autoscaling (KEDA)을 사용하여 Azure Function을 Kubernetes로 마이그레이션할 준비를 하고 있습니다. Azure Function에 대해 Kubernetes Custom Resource Definitions (CRD)을 구성해야 합니다. 어떤 CRD를 구성해야 합니까? 답하려면 적절한 CRD 유형을 올바른 위치로 끌어다 놓으십시오. 각 CRD 유형은 한 번, 여러 번 또는 전혀 사용되지 않을 수 있습니다. 내용을 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다. 참고: 각 정답 선택에는 1점이 부여됩니다. 선택하여 배치:
Azure Function 코드는 어떤 CRD 유형에 속합니까?
Polling interval은 어떤 CRD type에 속합니까?
Azure Storage connection string은 어떤 CRD type에 속합니까?
DRAG DROP - 데이터 저장소로 Azure Cosmos DB를 사용하는 웹사이트의 새 페이지를 개발하고 있습니다. 이 기능은 다음 형식의 문서를 사용합니다:
{
"name": "John",
"city": "Seattle"
}
새 페이지의 데이터를 특정 순서로 표시해야 합니다. 페이지에 대해 다음 쿼리를 만듭니다:
SELECT*
FROM People p
ORDER BY p.name, p.city DESC
쿼리를 지원하도록 Cosmos DB 정책을 구성해야 합니다. 정책을 어떻게 구성해야 합니까? 답하려면 적절한 JSON 세그먼트를 올바른 위치로 끌어다 놓으세요. 각 JSON 세그먼트는 한 번, 여러 번 또는 전혀 사용되지 않을 수 있습니다. 내용을 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다. 참고: 각 정답 선택에는 1점이 부여됩니다. 선택하여 배치하세요:
참고 이미지:
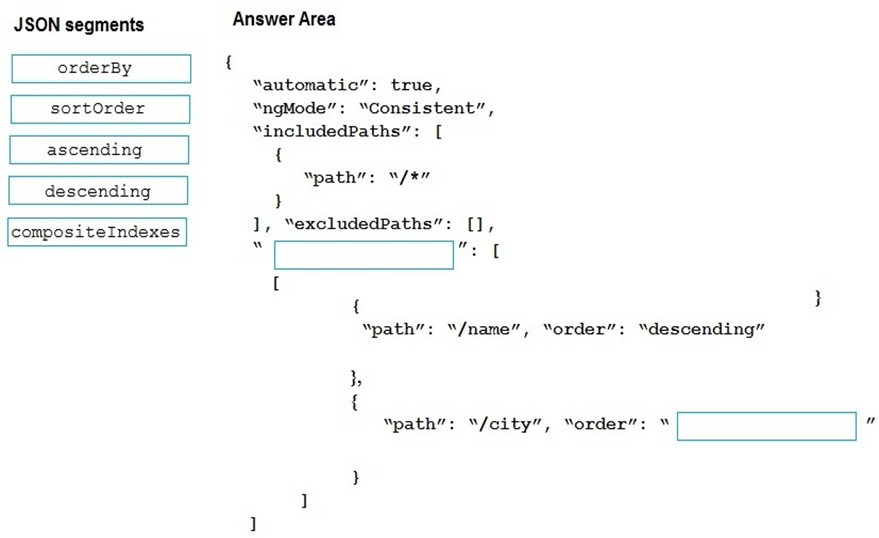
이 ORDER BY 쿼리를 지원하려면 Cosmos DB indexing policy를 어떻게 구성해야 하나요?
HOTSPOT - 항공사를 위한 티켓 예약 시스템을 개발하고 있습니다. 애플리케이션의 스토리지 솔루션은 다음 요구 사항을 충족해야 합니다: ✑ 최소 99.99% 가용성을 보장하고 낮은 지연 시간을 제공해야 합니다. ✑ 지역화된 네트워크 중단 또는 기타 예기치 않은 장애가 발생하더라도 예약을 수락해야 합니다. ✑ 초과 예약 또는 동일한 좌석을 여러 여행자에게 판매하는 일을 최소화하기 위해 예약이 제출된 정확한 순서대로 예약을 처리해야 합니다. ✑ 최대 5초 허용 범위 내에서 동시 및 순서가 뒤바뀐 예약을 허용해야 합니다. Azure South-Central US region에 airlineResourceGroup이라는 리소스 그룹을 프로비저닝합니다. 앱을 지원하기 위해 SQL API Cosmos DB account를 프로비저닝해야 합니다. Azure CLI 명령을 어떻게 완성해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
consistencyLevel = ______
az cosmosdb create \ --name $name \ ______ \ --resource-group $resourceGroupName \ --max-interval 5 \
--locations ______ \ --default-consistency-level = $consistencylevel
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
HOTSPOT - Azure Storage Queues를 사용하는 애플리케이션을 개발하고 있습니다. 다음 코드가 있습니다:
CloudStorageAccount storageAccount = CloudStorageAccount.Parse
(CloudConfigurationManager.GetSetting("StorageConnectionString"));
CloudQueueClient queueClient = storageAccount.CreateCloudQueueClient();
CloudQueue queue = queueClient.GetQueueReference("appqueue");
await queue.CreateIfNotExistsAsync();
CloudQueueMessage peekedMessage = await queue.PeekMessageAsync();
if (peekedMessage != null)
{
Console.WriteLine("peek한 메시지는 다음과 같습니다: {0}", peekedMessage.AsString);
}
CloudQueueMessage message = await queue.GetMessageAsync();
다음 각 문장에 대해, 문장이 참이면 Yes를 선택하세요. 그렇지 않으면 No를 선택하세요. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
이 코드는 queue의 lock duration을 구성합니다.
코드가 실행된 후에도 마지막으로 읽은 메시지는 queue에 남아 있습니다.
코드가 실행된 후에도 storage queue는 storage account에 남아 있습니다.
데이터 저장을 위해 Azure Blob storage를 사용하는 웹사이트를 구축하고 있습니다. 모든 blob을 30일 후 archive tier로 이동하도록 Azure Blob storage lifecycle을 구성합니다. 고객이 30일이 지난 데이터 조회에 대한 service-level agreement (SLA)를 요청했습니다. 데이터 복구에 대한 최소 SLA를 문서화해야 합니다. 어떤 SLA를 사용해야 합니까?
ASP.NET 웹 앱을 개발하여 Azure App Service에 배포합니다. 앱을 모니터링하기 위해 Application Insights telemetry를 사용합니다. 전 세계 여러 지점에서 정기적인 간격으로 앱이 사용 가능하고 응답성이 있는지 확인하기 위해 앱을 테스트해야 합니다. 앱이 응답하지 않으면 지원 담당자에게 경고를 보내야 합니다. 웹 앱에 대한 테스트를 구성해야 합니다. 어떤 두 가지 테스트 유형을 사용할 수 있습니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답 선택에는 1점이 부여됩니다.
HOTSPOT - 귀하는 Azure Web App으로 실행될 software as a service (SaaS) ASP.NET Core web service를 구현하고 있습니다. 이 web service는 저장소로 on-premises SQL Server database를 사용합니다. 또한 이 web service에는 data update를 처리하는 WebJob이 포함됩니다. 네 명의 고객이 이 web service를 사용합니다. ✑ WebJob의 각 instance는 단일 고객의 data를 처리하며 singleton instance로 실행되어야 합니다. ✑ 각 deployment는 production data를 제공하기 전에 deployment slot을 사용하여 테스트되어야 합니다. ✑ Azure 비용은 최소화되어야 합니다. ✑ Azure resource는 isolated network에 위치해야 합니다. Web App에 대한 App Service plan을 구성해야 합니다. App Service plan을 어떻게 구성해야 합니까? 답하려면, 답안 영역에서 적절한 설정을 선택하십시오. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
VM 인스턴스 수 ______
가격 책정 tier ______
귀하는 Azure FrontDoor를 사용하는 ASP.NET Core 웹사이트를 개발하고 있습니다. 이 웹사이트는 연구원들을 위해 사용자 지정 weather data sets를 구축하는 데 사용됩니다. Data sets는 사용자가 Comma Separated Value (CSV) 파일로 다운로드합니다. 데이터는 10시간마다 새로 고쳐집니다. 특정 파일은 Response Header 값에 따라 FrontDoor cache에서 제거되어야 합니다. Front Door cache에서 개별 asset를 제거해야 합니다. 어떤 유형의 cache purge를 사용해야 합니까?

지금 학습 시작하기
Cloud Pass를 다운로드하고 Microsoft AZ-204 자격증 학습을 이어가세요.