
Practice Test #5
50개 문제와 100분 시간 제한으로 실제 시험을 시뮬레이션하세요. AI 검증 답안과 상세 해설로 학습하세요.
AI 기반
3중 AI 검증 답안 및 해설
GPT Pro, Claude Opus, Gemini Pro가 답안과 해설을 교차 검증합니다. 선택지별 근거부터 요구사항 분해와 정답 아키텍처까지 확인하세요.
실전형 문제
Azure messaging services를 사용할 솔루션을 개발하고 있습니다. 솔루션이 publish-subscribe 모델을 사용하고 지속적인 polling의 필요성을 제거하도록 해야 합니다. 목표를 달성하는 두 가지 가능한 방법은 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답 선택은 1점의 가치가 있습니다.
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 일부입니다. 시리즈의 각 문제에는 제시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 문제 세트에는 둘 이상의 올바른 솔루션이 있을 수 있지만, 다른 문제 세트에는 올바른 솔루션이 없을 수도 있습니다. 이 섹션의 문제에 답한 후에는 해당 문제로 돌아갈 수 없습니다. 따라서 이러한 문제는 검토 화면에 표시되지 않습니다. 귀하는 사진을 관리하기 위한 software as a service (SaaS) 서비스를 개발합니다. 사용자는 사진을 web service에 업로드하고, 그러면 web service가 사진을 Azure Storage Blob storage에 저장합니다. storage account 유형은 General-purpose V2입니다. 사진이 업로드되면 이미지의 mobile-friendly 버전을 생성하고 저장하도록 처리되어야 합니다. 이미지의 mobile-friendly 버전을 생성하는 프로세스는 1분 이내에 시작되어야 합니다. 사진 처리를 시작하는 프로세스를 설계해야 합니다. 솔루션: Azure Storage account를 BlockBlobStorage storage account로 변환합니다. 이 솔루션이 목표를 충족합니까?
Shipping Logic App을 보안해야 합니다. 무엇을 사용해야 합니까?
DRAG DROP - Contoso, Ltd.는 Azure API Management (APIM)를 사용하여 고객에게 API를 제공합니다. 이 API는 JWT token으로 사용자를 인증합니다. APIM gateway에 대한 response caching을 구현해야 합니다. caching 메커니즘은 지정된 location의 데이터에 액세스하는 클라이언트의 user ID를 감지하고, 해당 user ID에 대해 response를 cache해야 합니다. 정책 파일에 다음 정책을 추가해야 합니다: ✑ 감지된 사용자 ID를 저장하기 위한 set-variable policy ✑ cache-lookup-value policy ✑ cache-store-value policy ✑ user profile 정보로 response body를 업데이트하기 위한 find-and-replace policy 정책을 어느 policy section에 추가해야 합니까? 답하려면 적절한 section을 올바른 정책에 끌어다 놓으십시오. 각 section은 한 번, 여러 번 또는 전혀 사용되지 않을 수 있습니다. 내용을 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수 있습니다. 참고: 각 정답 선택에는 1점이 부여됩니다. Select and Place:
Policy: Set-variable, Policy 섹션: ______
Policy: Cache-lookup-value, Policy section: ______
Policy: Cache-store-value, Policy 섹션: ______
Policy: Find-and-replace, Policy 섹션: ______
HOTSPOT - Contoso, Ltd.에서 근무하고 있습니다. 다음 XML markup을 사용하여 API Policy object를 정의합니다:
("bodySize"))
다음 각 문장에 대해, 문장이 참이면 Yes를 선택하세요. 그렇지 않으면 No를 선택하세요. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
XML 세그먼트는 policy의 <inbound> 섹션에 속합니다.
body size가 >256k이면 오류가 발생합니다.
요청이 http://contoso.com/api/9.2/인 경우, policy는 더 높은 버전을 유지합니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
단일 signaling server가 오디오 및 시각적 alarm의 시작과 중지를 트리거하는 hazard notification system을 만들고 있습니다. alarm을 publish하기 위해 Azure Service Bus를 구현합니다. 각 alarm controller는 transaction의 일부로 alarm signal을 수신하기 위해 Azure Service Bus를 사용합니다. audit 목적을 위해 alarm event를 기록해야 합니다. 각 transaction record에는 활성화된 alarm type에 대한 정보가 포함되어야 합니다. reply trail auditing solution을 구현해야 합니다. 어떤 두 가지 작업을 수행해야 합니까? 각 정답은 solution의 일부를 나타냅니다. 참고: 각 정답 선택에는 1점이 부여됩니다.
DRAG DROP - 귀하는 Azure Blob GPv1 Premium storage account를 사용하는 기존 애플리케이션을 유지 관리하고 있습니다. 3개월이 지난 데이터는 거의 사용되지 않습니다. 3개월 이내의 데이터는 즉시 사용할 수 있어야 합니다. 1년이 지난 데이터는 저장되어야 하지만 즉시 사용할 수 있을 필요는 없습니다. 마지막으로 수정된 지 1년이 지난 blob 데이터를 archive storage로 이동하는 lifecycle management rule을 지원하도록 account를 구성해야 합니다. 어떤 세 가지 작업을 순서대로 수행해야 합니까? 답하려면 작업 목록에서 적절한 작업을 답안 영역으로 이동하고 올바른 순서로 배열하십시오. 선택 및 배치:
참고 이미지:
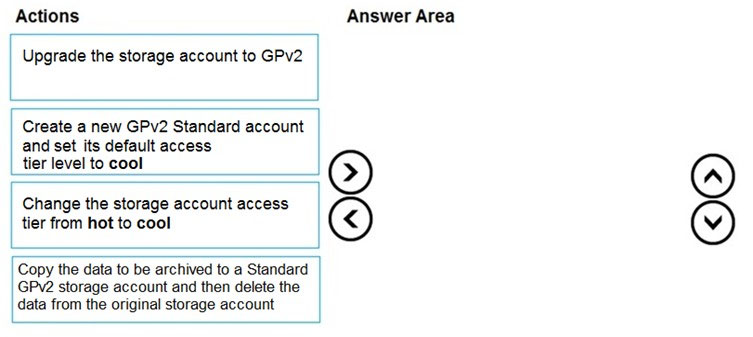
lifecycle management를 지원하고 스토리지 비용을 낮추려면 어떤 작업을 수행해야 하나요?
HOTSPOT - Azure Service Bus를 Event Grid 통합으로 구성해야 합니다. 어떤 Azure Service Bus 설정을 사용해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하세요. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
Tier ______
RBAC 역할 ______
Azure SQL Database 인스턴스에 연결하는 Azure function을 개발하고 있습니다. 이 function은 Azure Storage queue에 의해 트리거됩니다.
다음 메시지와 함께 다수의 System.InvalidOperationException 보고를 받았습니다:
Timeout expired. The timeout period elapsed prior to obtaining a connection from the pool. This may have occurred because all pooled connections were in use and max pool size was reached.
예외를 방지해야 합니다.
무엇을 해야 합니까?
HOTSPOT - 팀을 위한 개발 환경을 구성하고 있습니다. Azure Marketplace에서 최신 Visual Studio 이미지를 Azure subscription에 배포합니다. 개발 환경에는 조직 전반의 애플리케이션 개발을 지원하기 위해 여러 software development kits (SDKs) 및 third-party 구성 요소가 필요합니다. 개발 팀을 위해 배포된 virtual machine (VM)을 설치하고 사용자 지정합니다. 사용자 지정된 VM은 새 팀원의 개발 환경을 프로비저닝할 수 있도록 저장되어야 합니다. 향후 프로비저닝을 위해 사용자 지정된 VM을 저장해야 합니다. 어떤 도구 또는 서비스를 사용해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하세요. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
VM을 일반화합니다. ______
이미지를 저장합니다. ______

지금 학습 시작하기
Cloud Pass를 다운로드하고 Microsoft AZ-204 자격증 학습을 이어가세요.