
Practice Test #3
50개 문제와 100분 시간 제한으로 실제 시험을 시뮬레이션하세요. AI 검증 답안과 상세 해설로 학습하세요.
AI 기반
3중 AI 검증 답안 및 해설
GPT Pro, Claude Opus, Gemini Pro가 답안과 해설을 교차 검증합니다. 선택지별 근거부터 요구사항 분해와 정답 아키텍처까지 확인하세요.
실전형 문제
사용자 계약을 저장해야 합니다. 계약이 완료된 후 어디에 저장해야 합니까?
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 일부입니다. 시리즈의 각 문제에는 제시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 문제 세트에는 둘 이상의 올바른 솔루션이 있을 수 있지만, 다른 문제 세트에는 올바른 솔루션이 없을 수도 있습니다. 이 섹션의 문제에 답한 후에는 해당 문제로 돌아갈 수 없습니다. 따라서 이러한 문제는 검토 화면에 표시되지 않습니다. 귀하는 사진을 관리하기 위한 software as a service (SaaS) 서비스를 개발합니다. 사용자는 사진을 web service에 업로드하고, 그러면 web service가 사진을 Azure Storage Blob storage에 저장합니다. storage account 유형은 General-purpose V2입니다. 사진이 업로드되면, 이미지의 mobile-friendly 버전을 생성하고 저장하도록 처리되어야 합니다. 이미지의 mobile-friendly 버전을 생성하는 프로세스는 1분 이내에 시작되어야 합니다. 사진 처리를 시작하는 프로세스를 설계해야 합니다. 솔루션: Blob storage events에서 사진 처리를 트리거합니다. 이 솔루션이 목표를 충족합니까?
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 일부입니다. 시리즈의 각 문제에는 제시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 문제 세트에는 정답이 둘 이상 있을 수 있고, 다른 문제 세트에는 정답이 없을 수도 있습니다. 이 섹션의 문제에 답한 후에는 해당 문제로 돌아갈 수 없습니다. 따라서 이러한 문제는 검토 화면에 표시되지 않습니다. 귀하는 전 세계에 위치한 2,000개의 매장에서 point-of-sale (POS) 디바이스 데이터를 수집하기 위한 Azure 솔루션을 개발하고 있습니다. 단일 디바이스는 24시간마다 2 megabytes (MB)의 데이터를 생성할 수 있습니다. 각 매장 위치에는 데이터를 전송하는 디바이스가 1개에서 5개까지 있습니다. 디바이스 데이터는 Azure Blob storage에 저장해야 합니다. 디바이스 데이터는 디바이스 식별자를 기준으로 상관관계가 지정되어야 합니다. 향후 추가 매장이 개점할 것으로 예상됩니다. 디바이스 데이터를 수신하기 위한 솔루션을 구현해야 합니다. 솔루션: Azure Service Bus를 프로비저닝합니다. correlation filter를 사용하여 디바이스 데이터를 수신하도록 topic을 구성합니다. 이 솔루션이 목표를 충족합니까?
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 일부입니다. 시리즈의 각 문제에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 문제 세트에는 둘 이상의 올바른 솔루션이 있을 수 있지만, 다른 문제 세트에는 올바른 솔루션이 없을 수도 있습니다. 이 섹션의 문제에 답한 후에는 해당 문제로 돌아갈 수 없습니다. 따라서 이러한 문제는 검토 화면에 표시되지 않습니다. 귀하는 Azure 솔루션을 개발합니다. Azure Resource Manager에서 특정 resource group에 대한 virtual machine (VM) 액세스 권한을 부여해야 합니다. Azure Resource Manager access token을 획득해야 합니다. 솔루션: X.509 certificate를 사용하여 VM을 Azure Resource Manager에 인증합니다. 이 솔루션이 목표를 충족합니까?
귀하는 microservice architecture를 사용하는 e-commerce 솔루션을 개발하고 있습니다. 솔루션의 여러 부분 간에 transactional message를 통신하기 위한 communication backplane을 설계해야 합니다. 메시지는 first-in-first-out (FIFO) 순서로 전달되어야 합니다. 무엇을 사용해야 합니까?
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
HOTSPOT - App Service on Linux에 web app을 배포할 계획입니다. App Service plan을 만듭니다. web app이 포함된 custom Docker image를 만들어 Azure Container Registry에 push합니다. container 내부에서 생성되는 console logs에 실시간으로 액세스해야 합니다. Azure CLI 명령을 어떻게 완성해야 합니까? 답하려면 답안 영역에서 적절한 옵션을 선택하세요. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
az webapp log ______ --name Contosoweb --resource-group ContosoDevRG
______ filesystem
az ______ log ______ --name ContosoWeb --resource-group ContosoDevRG
az webapp log ______ --name ContosoWeb --resource-group ContosoDevRG
DRAG DROP - Azure Blob storage를 사용하기 위한 애플리케이션을 개발하고 있습니다. Azure Blob storage가 change feeds를 포함하도록 구성했습니다. 스토리지 계정의 복사본을 다른 region에 만들어야 합니다. 데이터는 현재 스토리지 계정에서 새 스토리지 계정으로 스토리지 서버 간에 직접 복사되어야 합니다. 다른 region에 스토리지 계정의 복사본을 만들고 데이터를 복사해야 합니다. 어떤 순서로 작업을 수행해야 합니까? 답하려면 작업 목록의 모든 작업을 답 영역으로 이동하고 올바른 순서로 정렬하세요. 선택 후 배치:
참고 이미지:
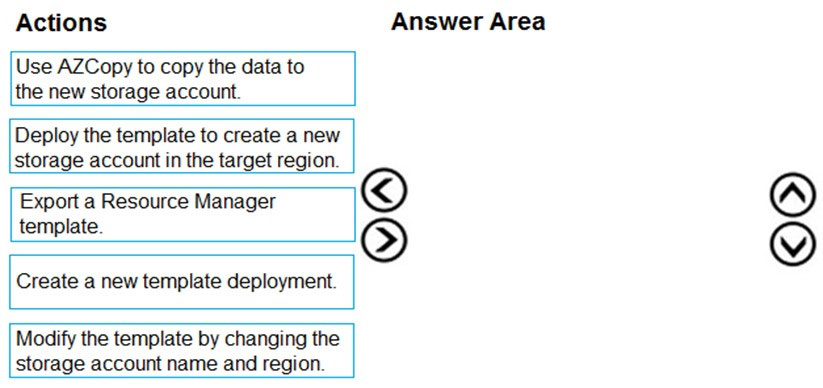
다른 지역에 storage account를 다시 만들고 데이터를 복사하려면 어떤 순서가 맞나요?
DRAG DROP - 당신은 microservices 솔루션을 개발하고 있습니다. 이 솔루션을 multinode Azure Kubernetes Service (AKS) cluster에 배포할 계획입니다. 다음 기능이 포함된 솔루션을 배포해야 합니다: ✑ reverse proxy 기능 ✑ 구성 가능한 트래픽 라우팅 ✑ 사용자 지정 인증서를 사용한 TLS 종료 어떤 구성 요소를 사용해야 합니까? 답하려면 적절한 구성 요소를 올바른 요구 사항에 끌어다 놓으세요. 각 구성 요소는 한 번, 여러 번 또는 전혀 사용되지 않을 수 있습니다. 내용을 보려면 창 사이의 분할 막대를 끌거나 스크롤해야 할 수도 있습니다. 참고: 각 정답 선택에는 1점이 부여됩니다. 선택 및 배치:
솔루션을 배포합니다.
클러스터 및 외부 IP addressing을 확인합니다.
여러 microservices로 라우팅되는 단일 public IP endpoint를 구현합니다.
당신은 웹사이트를 개발합니다. 웹사이트를 Azure에서 호스팅할 계획입니다. 웹사이트가 게시된 후 높은 트래픽을 경험할 것으로 예상합니다. 비용을 최소화하면서도 웹사이트가 계속 사용 가능하고 응답성을 유지하도록 해야 합니다. 웹사이트를 배포해야 합니다. 어떻게 해야 합니까?
클라이언트에게 Azure API Management 관리형 웹 서비스를 제공합니다. 백엔드 웹 서비스는 HTTP Strict Transport Security (HSTS)를 구현합니다. 백엔드 서비스에 대한 모든 요청에는 유효한 HTTP authorization header가 포함되어야 합니다. 인증 정책을 사용하여 Azure API Management 인스턴스를 구성해야 합니다. 사용할 수 있는 두 가지 정책은 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답 선택에는 1점이 부여됩니다.

지금 학습 시작하기
Cloud Pass를 다운로드하고 Microsoft AZ-204 자격증 학습을 이어가세요.