
Practice Test #1
50개 문제와 100분 시간 제한으로 실제 시험을 시뮬레이션하세요. AI 검증 답안과 상세 해설로 학습하세요.
AI 기반
3중 AI 검증 답안 및 해설
GPT Pro, Claude Opus, Gemini Pro가 답안과 해설을 교차 검증합니다. 선택지별 근거부터 요구사항 분해와 정답 아키텍처까지 확인하세요.
실전형 문제
HOTSPOT - Azure Active Directory (Azure AD) 인증을 사용할 App1이라는 Azure web app을 배포할 계획입니다. App1은 회사 사용자들이 인터넷을 통해 액세스합니다. 모든 사용자는 Windows 10을 실행하고 Azure AD에 조인된 컴퓨터를 사용합니다. 사용자가 인증 프롬프트 없이 App1에 연결할 수 있고, 회사 소유 컴퓨터에서만 App1에 액세스할 수 있도록 보장하는 솔루션을 권장해야 합니다. 각 요구 사항에 대해 무엇을 권장해야 합니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:
사용자는 인증 프롬프트 없이 App1에 연결할 수 있습니다: ______
정답: A (Azure AD app registration). Azure web app (App Service)에 대해 Azure AD 인증을 활성화하고 SSO를 달성하려면, 애플리케이션이 Azure AD에 표현되어 있어야 합니다. 그 표현이 바로 OAuth2/OpenID Connect 토큰 발급에 사용되는 app registration (enterprise application/service principal)입니다. Azure AD-joined Windows 10 디바이스에서는 사용자가 일반적으로 Primary Refresh Token (PRT)을 보유하므로, 지원되는 브라우저에서 자동 토큰 획득이 가능하며, 그 결과 대화형 프롬프트 없이 App1에 액세스할 수 있습니다. 다른 선택지가 틀린 이유: - B (Managed identity)는 workload identity용입니다 (앱이 Key Vault/Storage 같은 Azure 리소스에 액세스하는 경우) 그리고 web app에 대한 최종 사용자 인증/SSO를 제공하지 않습니다. - C (Azure AD Application Proxy)는 주로 온-프레미스 앱을 Azure AD를 통해 외부에 게시하기 위한 것입니다. App1은 이미 인터넷에 노출된 Azure web app이므로, SSO를 위해 Application Proxy는 필요하지 않으며 app registration의 필요성을 대체하지도 않습니다.
사용자는 회사 소유의 컴퓨터에서만 App1에 액세스할 수 있습니다: ______
정답: A (Conditional Access policy). Conditional Access는 디바이스 상태와 같은 조건을 기반으로 cloud app에 대한 액세스를 제어하도록 설계된 Azure AD 기능입니다. 회사 소유의 컴퓨터만 App1에 액세스할 수 있도록 하려면, App1을 대상으로 하는 Conditional Access policy를 구성하여 디바이스가 규정 준수로 표시되도록 요구하고(일반적으로 Microsoft Intune 사용) 및/또는 Azure AD joined 디바이스를 요구합니다. 이렇게 하면 앱이 인터넷에서 접근 가능하더라도, 관리되는 회사 디바이스에서 sign-in이 이루어질 때만 액세스가 허용되도록 강제할 수 있습니다. 다른 선택지가 틀린 이유: - B (Administrative unit)는 사용자/디바이스의 관리 범위를 지정할 뿐이며, sign-in 제한을 강제하지 않습니다. - C (Application Gateway)는 Layer 7 reverse proxy/WAF이며, Azure AD 디바이스 규정 준수/join 상태를 평가할 수 없습니다. - D (Azure Blueprints)와 E (Azure Policy)는 Azure 리소스 배포/구성을 관리하며, 최종 사용자 인증 및 디바이스 기반 액세스 제어를 담당하지 않습니다.
Azure subscription에서 모든 새로운 Azure Resource Manager (ARM) resource deployment의 월간 보고서를 생성하기 위한 솔루션을 권장해야 합니다. 권장 사항에 무엇을 포함해야 합니까?
Azure Activity Log가 정답인 이유는 ARM deployment 작업과 resource 생성 이벤트를 포함한 모든 subscription 수준 control-plane 이벤트를 기록하기 때문입니다. 따라서 특정 월 내의 새로운 deployment를 식별하기 위한 기본 감사 소스가 됩니다. 여기에는 caller, operation name, timestamp 및 status와 같은 유용한 metadata가 포함되며, 이는 deployment 보고서에 정확히 필요한 세부 정보입니다. 시험 시나리오에서 Azure 관리 작업이나 deployment를 추적해야 하는 요구 사항이 있다면, Activity Log가 선택해야 할 주요 서비스입니다.
Azure Advisor는 비용, 보안, 안정성, 운영 우수성 및 성능 전반에 걸친 모범 사례 권장 사항에 중점을 둡니다. ARM deployment의 권한 있는 감사 추적이나 새로운 deployment의 전체 목록을 제공하지 않습니다. Advisor는 deployment로 인해 발생한 구성 문제를 강조할 수는 있지만, 규정 준수 스타일의 deployment 보고용으로 설계된 것은 아닙니다.
Azure Analysis Services는 Power BI와 같은 BI 도구에서 사용하는 tabular semantic model(SSAS Tabular와 유사)을 호스팅하기 위한 PaaS analytics 서비스입니다. 자체적으로 Azure subscription Activity Log 이벤트를 수집하거나 추적하지 않습니다. 이론적으로는 다른 곳으로 로그를 export한 후 데이터를 모델링할 수 있지만, deployment 보고서를 생성하기 위한 올바른 기본 서비스는 아닙니다.
Azure Monitor action groups는 alert rule에서 사용하는 알림 및 자동화 endpoint(email, SMS, webhook, Logic Apps 등)를 정의합니다. ARM deployment 이벤트를 수집, 저장 또는 나열하지 않습니다. Activity Log/Log Analytics에 대한 alert를 만든 후 action groups를 사용할 수는 있지만, 월간 deployment 보고서의 데이터 소스는 아닙니다.
문제 분석
핵심 개념: 새로운 Azure Resource Manager (ARM) resource deployment의 월간 보고서를 생성하려면, subscription에서 수행된 control-plane 작업을 기록하는 Azure 서비스를 사용해야 합니다. Azure Activity Log는 resource 생성, 업데이트, 삭제 및 deployment 작업과 같은 subscription 수준 이벤트를 캡처합니다. 정답인 이유: Azure Activity Log는 resource가 언제 deployment되었는지와 누가 작업을 시작했는지를 기록하므로 ARM deployment 활동에 대한 권한 있는 소스입니다. 지난 한 달 동안의 deployment 관련 작업으로 로그를 필터링하고, 해당 데이터를 월간 보고서의 기반으로 사용할 수 있습니다. 주요 기능: 1) 생성/업데이트/삭제 및 deployment 작업을 포함하여 subscription의 control-plane 이벤트를 캡처합니다. 2) timestamp, caller, operation name, status 및 대상 resource와 같은 세부 정보를 제공합니다. 3) subscription, resource group, operation type 및 time range별 필터링을 지원합니다. 4) 더 긴 보존 기간이나 고급 보고가 필요한 경우 export하거나 다른 Azure Monitor 기능과 통합할 수 있습니다. 일반적인 오해: - Azure Advisor는 deployment의 감사 추적이 아니라 권장 사항을 제공합니다. - Azure Analysis Services는 분석 모델용이지, Azure deployment 추적용이 아닙니다. - Azure Monitor action groups는 알림을 보내거나 작업을 트리거할 뿐이며, deployment 기록을 저장하지 않습니다. 시험 팁: Azure resource에 대해 "누가 무엇을 언제 했는지"를 무엇이 기록하는지 묻는 문제에서는 Azure Activity Log를 떠올리십시오. 이것은 subscription 수준 ARM 작업 감사에 대한 기본 정답입니다. data-plane 로그, 권장 사항 및 알림 메커니즘과 구분하십시오.
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 일부입니다. 시리즈의 각 문제에는 제시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 문제 세트에는 둘 이상의 올바른 솔루션이 있을 수 있지만, 다른 문제 세트에는 올바른 솔루션이 없을 수도 있습니다. 이 섹션의 문제에 답한 후에는 해당 문제로 돌아갈 수 없습니다. 따라서 이러한 문제는 검토 화면에 표시되지 않습니다. 귀사는 여러 virtual machine을 on-premises와 Azure에 배포합니다. on-premises와 Azure 간 연결을 위해 ExpressRoute가 배포되고 구성되어 있습니다. 여러 virtual machine에서 network connectivity 문제가 발생하고 있습니다. virtual machine에 대한 packet이 허용되는지 또는 거부되는지 식별하기 위해 network traffic을 분석해야 합니다. 솔루션: Azure Network Watcher를 사용하여 IP flow verify를 실행해 network traffic을 분석합니다. 이것이 목표를 충족합니까?
이 옵션은 Azure Network Watcher IP flow verify가 virtual machine으로 들어오거나 virtual machine에서 나가는 packet이 허용되는지 또는 거부되는지를 판단하도록 특별히 만들어졌기 때문에 정답입니다. 이 도구는 지정된 source, destination, port, protocol 정보를 사용하여 NIC 및 subnet 수준에 적용되는 유효한 NSG 규칙을 평가합니다. 또한 allow 또는 deny 결과를 초래한 정확한 규칙도 식별하므로 connectivity 문제 해결에 이상적입니다. 목표가 VM에 대한 packet이 허용되는지 또는 거부되는지를 분석하는 것이므로, 이 솔루션은 요구 사항을 직접적으로 충족합니다.
이 옵션은 제안된 솔루션이 제시된 목표를 충족하기 때문에 오답입니다. IP flow verify는 유효한 NSG 규칙을 기반으로 traffic이 허용되는지 또는 차단되는지를 확인하는 핵심 Azure Network Watcher 진단 기능 중 하나입니다. 비록 전체 packet inspection을 수행하거나 ExpressRoute 전반의 모든 hop을 추적하지는 않지만, 문제는 virtual machine에 대한 packet이 허용되는지 또는 거부되는지를 식별하는 것만 요구합니다. 그 목적에는 IP flow verify가 적절하고 충분한 도구입니다.
문제 분석
핵심 개념: 이 문제는 Azure Network Watcher 진단, 특히 VM으로 들어오거나 VM에서 나가는 traffic이 NSG와 같은 Azure networking 규칙에 의해 허용되는지 또는 거부되는지를 판단할 수 있는 도구에 대한 지식을 평가합니다. 정답인 이유: Azure Network Watcher의 IP flow verify는 VM으로 들어오거나 VM에서 나가는 packet이 허용되는지 또는 거부되는지를 확인하도록 설계되었습니다. 이는 VM의 network interface 또는 subnet에 적용되는 유효한 network security 규칙을 평가하고, 해당 결정과 함께 그 원인이 된 특정 규칙을 반환합니다. 이 시나리오의 요구 사항은 virtual machine에 대한 packet이 허용되는지 또는 거부되는지를 식별하는 것이며, IP flow verify는 그 질문에 직접적으로 답합니다. ExpressRoute의 존재는 Azure 측 packet filtering 분석에 대한 이 도구의 유용성을 바꾸지 않습니다. 주요 기능 / 구성: - Azure Network Watcher는 Azure 리소스를 위한 network diagnostic 및 monitoring 도구를 제공합니다. - IP flow verify는 source IP, destination IP, source port, destination port, protocol로 구성된 5-tuple 스타일 flow를 테스트합니다. - traffic이 Allowed인지 Denied인지 식별합니다. - 또한 어떤 NSG 규칙이 해당 결정을 초래했는지도 보여줍니다. - Azure network security filtering과 관련된 VM connectivity 문제를 해결하는 데 유용합니다. - 전체 end-to-end 경로 전반에 걸친 임의의 packet capture가 아니라 Azure 측의 유효한 security 규칙을 분석합니다. 일반적인 오해: - 응시자는 종종 IP flow verify를 packet capture와 혼동합니다. packet capture는 traffic을 기록하는 반면, IP flow verify는 Azure가 특정 flow를 허용할지 또는 거부할지를 평가합니다. - 일부는 ExpressRoute에 다른 diagnostic 도구가 필요하다고 가정합니다. ExpressRoute는 connectivity에 영향을 주지만, VM traffic에 대한 Azure 측 NSG 평가는 여전히 IP flow verify로 확인할 수 있습니다. - 또 다른 일반적인 실수는 문제가 packet이 허용되는지 또는 거부되는지를 구체적으로 묻고 있는데 connection troubleshoot를 선택하는 것입니다. connection troubleshoot는 reachability를 테스트하지만, 규칙 기반 allow/deny 분석을 위한 직접적인 도구는 IP flow verify입니다. 시험 팁: - 문제가 traffic이 허용되는지 또는 거부되는지를 묻는다면, IP flow verify를 떠올리십시오. - 어떤 NSG 규칙이 traffic에 영향을 주는지 묻는다면, IP flow verify가 매우 적합합니다. - 실제 packet을 캡처하라고 묻는다면, 대신 packet capture를 사용하십시오. - end-to-end connectivity를 테스트하라고 묻는다면, connection troubleshoot를 고려하십시오. - Azure 규칙 평가 도구와 traffic 기록 도구를 구분하십시오.
사용자를 위한 콘텐츠를 집계할 애플리케이션을 설계하고 있습니다. 애플리케이션에 적합한 데이터베이스 솔루션을 추천해야 합니다. 솔루션은 다음 요구 사항을 충족해야 합니다: ✑ SQL 명령을 지원해야 합니다. ✑ multi-master writes를 지원해야 합니다. ✑ 낮은 지연 시간의 읽기 작업을 보장해야 합니다. 추천에 무엇을 포함해야 합니까?
Azure Cosmos DB SQL API는 globally distributed 애플리케이션을 위해 설계되었습니다. JSON documents에 대한 SQL과 유사한 queries를 지원하고, 활성화 시 multi-region (multi-master) writes를 제공하며, 사용자와 가까운 regions에 데이터를 복제하여 낮은 지연 시간의 reads를 제공합니다. 또한 configurable consistency levels 및 conflict resolution을 지원하는데, 이는 multi-master writes를 활성화할 때 중요한 고려 사항입니다.
active geo-replication을 사용하는 Azure SQL Database는 DR 및 read scaling을 위해 다른 regions에 readable secondary replicas를 제공하지만, multi-master writes는 지원하지 않습니다. writes를 수락하는 것은 primary database뿐이며 secondaries는 read-only입니다. 사용자가 가까운 secondary에서 읽는다면 낮은 지연 시간의 reads 요구 사항은 충족할 수 있지만, multi-master write 요구 사항은 충족하지 못합니다.
Azure SQL Database Hyperscale은 매우 큰 databases와 빠른 scale에 최적화된 tier로, compute와 storage를 분리하는 architecture를 가지며 read replicas를 사용할 수 있습니다. 그러나 여전히 single-writer model을 따르며 regions 간 multi-master writes를 제공하지 않습니다. read performance 및 scale에는 도움이 될 수 있지만, multi-master 요구 사항은 충족하지 못합니다.
Azure Database for PostgreSQL은 표준 SQL을 지원하고 reads 확장을 위한 read replicas를 제공할 수 있지만, managed service는 기본 제공 기능으로 native multi-master, multi-region writes를 제공하지 않습니다. 일반적인 HA/DR 패턴은 replicas가 있는 single primary입니다. multi-master를 구현하려면 복잡한 custom replication/conflict handling이 필요하며, 이는 의도된 managed solution이 아닙니다.
문제 분석
핵심 개념: 이 문제는 SQL과 유사한 쿼리를 지원하고, multi-master (multi-region) writes를 지원하며, 일관되게 낮은 지연 시간의 읽기를 제공하는 globally distributed 데이터베이스를 선택하는지를 평가합니다. Azure에서 이러한 조합을 위해 주로 설계된 서비스는 SQL API를 사용하는 Azure Cosmos DB입니다. 정답인 이유: Azure Cosmos DB SQL API는 JSON documents에 대해 SQL과 유사한 query language를 제공하며 global distribution을 위해 구축되었습니다. “multi-region writes” 기능을 통해 multi-region writes (multi-master)를 지원하므로 여러 Azure regions에서 writes를 수락할 수 있습니다. 낮은 지연 시간의 reads를 위해 Cosmos DB는 사용자와 가까운 regions에 데이터를 복제할 수 있게 하며, automatic indexing 및 partitioning을 사용하여 읽기 성능을 예측 가능하게 유지합니다. 또한 consistency levels(예: 사용자 중심 앱을 위한 Session)를 선택하여 latency와 consistency의 균형을 맞출 수 있습니다. 주요 기능 / 구성: - SQL 지원: Cosmos DB SQL API는 JSON items에 대해 SQL과 유사한 queries(SELECT, WHERE, ORDER BY 등)를 사용합니다. - Multi-master writes: multi-region writes를 활성화하고 여러 regions를 추가합니다. Cosmos DB는 conflict detection/resolution(last-writer-wins 또는 stored procedures를 사용하는 custom conflict resolution)을 처리합니다. - 낮은 지연 시간의 reads: 사용자와 가까운 read regions를 추가합니다. Cosmos DB는 적절히 partitioning되고 provisioned된 경우 실제로 single-digit millisecond reads를 제공합니다. - Partitioning 및 throughput: 적절한 partition key를 선택하고 latency/throughput SLOs를 충족하도록 RU/s(또는 autoscale)를 provision합니다. - Well-Architected alignment: Performance Efficiency(global distribution, 예측 가능한 latency), Reliability(multi-region replication), Operational Excellence(managed service)를 향상시킵니다. 일반적인 오해: active geo-replication을 사용하는 Azure SQL Database는 read scale 및 DR을 향상시키지만 multi-master는 아닙니다. 쓰기가 가능한 것은 primary뿐입니다. Hyperscale은 scale-out storage 및 read replicas를 향상시키지만 여전히 multi-master writes를 제공하지 않습니다. Azure Database for PostgreSQL(managed Postgres)은 SQL을 지원하지만 regions 간 multi-master writes는 Azure managed offering의 표준 기본 제공 기능이 아닙니다. 일반적인 패턴은 read replicas가 있는 single-writer에 의존합니다. 시험 팁: “multi-master writes”, “낮은 지연 시간의 reads”, “global users”를 보면 Cosmos DB를 떠올리십시오. 요구 사항이 엄격한 relational semantics(joins, constraints)이고 single-writer가 허용된다면 Azure SQL이 정답인 경우가 많지만, 여기서는 multi-master가 핵심적인 차별 요소입니다.
다음 표에 표시된 Azure 리소스가 있습니다.
모든 Azure Firewall 배포에 대한 필수 규칙을 포함할 새 Azure Firewall policy를 배포해야 합니다. 새 policy는 기존 policy의 parent policy로 구성됩니다. 생성해야 하는 추가 Azure Firewall policy의 최소 개수는 얼마입니까?
US-Central-Firewall-policy는 Azure Firewall policy 유형이며 Central US에 있습니다.
예. 이 문장은 US-Central-Firewall-policy가 Central US에 있는 Azure Firewall policy라고 말합니다. 이 유형의 문제에 제공되는 리소스 테이블에서 US-Central-Firewall-policy는 Firewall Policy 리소스로 나열되어 있으며 해당 region은 Central US입니다. 이것이 중요한 이유는 Firewall Policy가 regional 리소스이며 새 parent policy(또한 Central US에 있음) 아래에서 child policy로 구성하는 객체이기 때문입니다. 이 policy가 명시된 것과 다른 region에 있었다면, 해당 policy에 Central US parent policy를 사용할 수 없습니다. 왜 아니요가 아닌가: 리소스 유형이나 region이 다르다는 어떤 표시도 없습니다. naming convention과 일반적인 테이블 항목은 이 항목에 대해 “Azure Firewall policy”와 “Central US”에 부합합니다.
US-East-Firewall-policy는 Azure Firewall policy 유형이며 East US에 있습니다.
예. US-East-Firewall-policy는 East US에 있는 Azure Firewall policy로 설명되어 있으며, 이는 이 시나리오의 일반적인 리소스 테이블과 일치합니다. parent/child 설계에서 이는 중요합니다. parent policy는 child policy와 동일한 region에 있어야 하기 때문입니다. 이 policy는 East US에 있으므로 East US parent policy가 필요합니다(이미 하나가 존재하지 않는 한, 질문에서는 존재하지 않는다고 암시합니다). 왜 아니요가 아닌가: US-East-Firewall-policy가 East US에 없거나(또는 Firewall Policy가 아니라면) 필요한 parent policies 수가 달라집니다. 이 시나리오의 의도는 여러 region에 걸친 여러 policies를 보여 주어 여러 regional parent policies가 필요함을 나타내는 것입니다.
EU-Firewall-policy는 Azure Firewall policy 유형이며 West Europe에 위치합니다.
예. EU-Firewall-policy는 Azure Firewall policy 유형이며 West Europe에 위치합니다. 이는 유럽 리소스가 West Europe에 배포되는 일반적인 구성과 일치합니다. 시험 관점에서 핵심은 West Europe이 Central US 및 East US와는 구별되는 별도의 region이라는 점입니다. Azure Firewall Policy hierarchy는 region에 종속되므로, West Europe child policy에는 West Europe parent policy가 필요합니다. 아니요가 아닌 이유: 이를 아니요로 표시하면 리소스 유형이 Firewall Policy가 아니거나 region이 West Europe이 아니라는 의미가 되며, 이는 설계 요구 사항을 유도하는 시나리오의 multi-region policy footprint와 모순됩니다.
USEastfirewall은 Azure Firewall 유형이며 Central US에 있습니다.
아니요. 이 문장은 USEastfirewall(Azure Firewall)이 Central US에 있다고 말합니다. 이 시나리오의 리소스 테이블에서 USEastfirewall은 East US에 배포된 Azure Firewall입니다(이름도 강하게 East US를 나타내며, 이러한 문제는 일반적으로 지역에 대한 주의를 테스트하기 위해 의도적인 불일치를 포함합니다). 이 구분은 중요한데, Azure Firewall(데이터 플레인)도 regional이며 동일한 region의 Firewall Policy와 연결되어야 하기 때문입니다. 그러나 추가로 필요한 parent policy의 수에 대한 질문에서는 결정 요인이 firewall 이름이 아니라 기존 firewall policies의 regions(및 이에 필요한 regional parents)입니다. 왜 예가 아닌가: 이 불일치를 받아들이면 시험에서 적용하기를 기대하는 regional-alignment 규칙을 훼손하게 됩니다.
USWestfirewall은 Azure Firewall 유형이며 East US에 있습니다.
아니요. 이 문장은 USWestfirewall(Azure Firewall)이 East US에 있다고 말합니다. 일반적인 리소스 테이블에서 USWestfirewall은 West US(또는 미국 서부 리전)에 위치하며, 이 문장은 프롬프트에 의존하지 않고 리전을 검증하는지 확인하기 위해 의도적으로 바꿔 놓은 것입니다. 아키텍처 관점에서 Azure Firewall은 보호하는 virtual network와 동일한 리전에 배포되어야 하며 동일한 리전의 Firewall Policy를 사용해야 합니다. 잘못된 리전 식별은 유효하지 않은 설계로 이어질 수 있습니다(한 리전의 firewall을 다른 리전의 policy에 연결할 수 없습니다). 왜 예가 아닌가: firewall의 이름과 시나리오의 패턴은 리전이 East US가 아님을 나타냅니다. 즉, 일치하지 않습니다.
EUFirewall는 Azure Firewall 유형이며 West Europe에 위치합니다.
예. EUFirewall는 Azure Firewall 유형이며 West Europe에 위치합니다. 이는 EU 배포에 대해 예상되는 리소스 배치와 일치합니다. 이것이 중요한 이유는 EUFirewall가 West Europe Firewall Policy(예: EU-Firewall-policy)와 연결되어야 하기 때문입니다. parent policy를 통해 필수 baseline을 도입할 때, EU-Firewall-policy가 이를 상속하고 EUFirewall가 동일한 region의 policy를 계속 사용할 수 있도록 해당 parent를 West Europe에 생성해야 합니다. 왜 아니요가 아닌가: 여기에는 불일치를 나타내는 내용이 없습니다. 이러한 시험 시나리오에서는 regional association requirement를 강조하기 위해 EU firewall와 EU policy가 일반적으로 모두 West Europe에 있습니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
HOTSPOT - 귀사는 VM1이라는 Azure virtual machine에 배포된 web service를 개발합니다. 이 web service는 API가 VM1의 real-time data에 액세스할 수 있도록 합니다. 현재 virtual machine 배포는 Deployment 그림에 나와 있습니다.
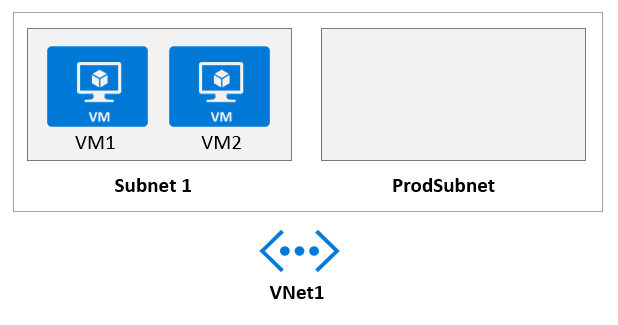
최고 기술 책임자(CTO)가 다음 이메일 메시지를 보냈습니다: "우리 개발자들이 VM1이라는 virtual machine에 web service를 배포했습니다. 테스트 결과 API는 VM1과 VM2에서 액세스할 수 있는 것으로 나타났습니다. 우리 파트너들은 Internet을 통해 API에 연결할 수 있어야 합니다. 파트너들은 자신들이 개발하는 애플리케이션에서 이 데이터를 사용할 것입니다." 귀하는 Azure API Management (APIM) 서비스를 배포합니다. 관련 API Management 구성은 API 그림에 나와 있습니다.
다음 각 문장에 대해, 문장이 참이면 Yes를 선택하십시오. 그렇지 않으면 No를 선택하십시오. 참고: 각 정답 선택에는 1점이 부여됩니다. Hot Area:

API는 인터넷을 통해 파트너에게 제공됩니다.
예. External VNet mode의 APIM은 인터넷에서 액세스할 수 있도록 설계되었으며, 동시에 VNet의 subnet에도 연결됩니다. 이 mode에서 APIM은 인바운드 클라이언트 트래픽(인터넷을 통한 파트너)을 위해 public IP/public gateway endpoint를 유지하고, private backend에 도달하기 위해 VNet integration을 사용합니다. 이는 파트너가 인터넷을 통해 연결해야 한다는 CTO 요구 사항과 일치합니다. APIM이 Internal로 구성되었다면, VNet 내부에서만(또는 VPN/ExpressRoute와 같은 private connectivity를 통해서만) 도달할 수 있으며, public internet의 파트너는 추가적인 네트워크 설계 없이는 이에 도달할 수 없습니다.
APIM 인스턴스는 VM1의 real-time data에 액세스할 수 있습니다.
예. APIM 인스턴스는 External mode로 VNet1 (ProdSubnet)에 injected되어 있으므로, 해당 VNet에 대한 network connectivity를 가지며 동일한 VNet 내의 다른 subnet들(예: VM1이 있는 Subnet1)로 라우팅할 수 있습니다. 이는 기본 VNet routing이 적용되고 차단하는 NSG/UDR이 없다고 가정한 경우입니다. 제시된 구성에서 VM1과 VM2는 Subnet1에 있고 APIM은 ProdSubnet에 있으며, 둘 다 VNet1 내에 있으므로 APIM은 private IP/DNS name을 사용하여 VM1의 backend API를 호출할 수 있습니다. 이것이 VNet integration을 사용하는 주요 이유 중 하나입니다: backend는 private하게 유지하면서도 외부 소비자에게는 관리되는 API surface를 계속 노출할 수 있습니다.
파트너 액세스를 위해 VPN gateway가 필요합니다.
아니요. 이 설계에서는 파트너가 public internet을 통해 연결하도록 의도되어 있고 APIM이 public endpoint를 제공하는 External mode로 구성되어 있으므로, 파트너 액세스를 위해 VPN gateway가 필요하지 않습니다. VPN gateway(site-to-site 또는 point-to-site)는 일반적으로 파트너가 private endpoint(예: Internal mode의 APIM)에 액세스해야 하거나, public internet 노출을 피하고 private connectivity를 사용하려는 경우에 필요합니다. 여기서는 요구 사항에서 파트너를 위한 internet access를 명시적으로 stated하고 있으며, APIM 구성은 VPN/ExpressRoute 없이도 이를 직접 지원합니다.
여러 Azure cloud services를 포함하고 트랜잭션의 서로 다른 구성 요소를 처리할 sales application을 개발하고 있습니다. 서로 다른 cloud services가 customer orders, billing, payment, inventory, shipping을 처리합니다. XML messages를 사용하여 cloud services가 트랜잭션 정보를 비동기적으로 통신할 수 있도록 하는 솔루션을 권장해야 합니다. 권장 사항에 무엇을 포함해야 합니까?
Azure Notification Hubs는 mobile devices(iOS/Android) 및 browsers에 messages를 보내기 위한 push notification service입니다. 이는 사용자에게 fan-out notifications를 보내는 데 최적화되어 있으며, 안정적인 service-to-service transactional messaging용이 아닙니다. order/billing/payment workflow integration에 필요한 dead-lettering, sessions, enterprise delivery semantics를 갖춘 queues/topics 같은 핵심 broker 기능이 부족합니다.
Azure Data Lake (Azure Data Lake Storage Gen2)는 big data analytics storage(Hadoop/Spark)를 위해 설계되었으며, batch 및 analytical workloads를 위한 대량의 structured/unstructured data를 저장합니다. XML files를 저장할 수는 있지만 messaging system이 아니며, microservices를 위한 message locks, retries, subscriptions, guaranteed delivery patterns와 같은 비동기 broker 기능을 제공하지 않습니다.
Azure Service Bus는 queues 및 topics/subscriptions를 사용한 내구성 있는 비동기 messaging을 제공하므로 order processing, billing, inventory, shipping과 같은 분산된 트랜잭션 구성 요소를 조정하는 데 이상적입니다. 이는 reliable delivery patterns, dead-lettering, ordered processing을 위한 sessions, duplicate detection을 지원합니다. 또한 payload-agnostic이므로 XML messages를 message body로 전달하면서 services 간의 느슨하게 결합되고 복원력 있는 통신을 가능하게 합니다.
Azure Blob Storage는 unstructured data(files, documents, logs)를 위한 object storage입니다. XML documents를 저장하고 services가 변경 사항을 polling하도록 할 수는 있지만, 이는 비효율적이며 messaging guarantees, consumer coordination, built-in retry/dead-letter patterns가 부족합니다. Blob Storage는 transactional workflows를 위한 message broker로 의도된 것이 아니라 주로 storage용이며, 비동기 integration용이 아닙니다.
문제 분석
핵심 개념: 이 문제는 Azure에서 분산된 application 구성 요소(microservices) 간의 비동기 messaging과 느슨하게 결합된 통신을 테스트합니다. 핵심 요구 사항은 여러 cloud services(orders, billing, payment, inventory, shipping)가 XML messages를 사용하여 트랜잭션 정보를 비동기적으로 교환해야 한다는 것입니다. 정답인 이유: Azure Service Bus는 서비스 간의 안정적인 비동기 통신을 위해 설계된 Azure의 enterprise message broker입니다. 이는 message 기반 integration patterns(queues 및 topics/subscriptions)을 지원하여 producers와 consumers를 분리하고, 각 트랜잭션 구성 요소가 독립적으로 그리고 자체 속도에 맞춰 messages를 처리할 수 있게 합니다. XML payloads는 단순히 message bodies일 뿐이며, Service Bus는 payload-agnostic이므로 XML을 문제없이 전송할 수 있습니다. 이는 Azure Well-Architected Framework 원칙인 reliability(내구성 있는 messaging), operational excellence(표준 integration), performance efficiency(buffering 및 load leveling)와 일치합니다. 주요 기능 및 best practices: - point-to-point workflows를 위한 queues(예: billing service가 소비하는 “BillingQueue”). - publish/subscribe fan-out을 위한 topics/subscriptions(예: inventory, shipping, billing에 대한 subscriptions를 가진 “OrderPlacedTopic”). - Peek-Lock, message settlement, retry handling을 통한 at-least-once delivery. - poison messages 및 troubleshooting을 위한 dead-letter queues (DLQ). - 트랜잭션/customer별 FIFO 및 message ordering을 위한 sessions. - 중복 처리를 줄이기 위한 duplicate detection. - Azure AD/RBAC 및 Shared Access Signatures (SAS)를 통한 security, 그리고 network isolation을 위한 private endpoints. 흔한 오해: 일부는 microservices에 사용된다는 이유로 Service Fabric을 선택할 수 있지만, 이는 hosting/orchestration platform이지 messaging broker가 아닙니다. Notification Hubs는 mobile push notifications용이지 service-to-service 트랜잭션 처리용이 아닙니다. Traffic Manager는 DNS 기반 load balancing/failover용이지 messaging용이 아닙니다. 시험 팁: “비동기적으로 통신”, “services 분리”, “reliable messaging”, “queues/topics”, “enterprise integration”과 같은 표현이 보이면 Azure Service Bus를 떠올리십시오. 시나리오가 대규모 event streaming/telemetry를 강조하면 Event Hubs를 고려하고, 경량 event routing을 강조하면 Event Grid를 고려하십시오. 여기서는 트랜잭션 구성 요소와 안정적인 처리가 핵심이므로 Service Bus가 강하게 시사됩니다.
다음 요구 사항을 충족하는 고가용성 Azure SQL database를 설계해야 합니다: ✑ database의 replica 간 failover는 데이터 손실 없이 발생해야 합니다. ✑ zone outage가 발생하는 경우에도 database는 계속 사용 가능해야 합니다. ✑ 비용은 최소화되어야 합니다. 어떤 deployment 옵션을 사용해야 합니까?
Azure SQL Database Serverless는 General Purpose 내의 compute tier로, auto-scale 및 auto-pause를 통해 간헐적 사용의 비용을 줄입니다. 이는 replica 간 데이터 손실 없는 failover를 보장하도록 설계되지 않았으며, zone 복원력을 갖춘 synchronous replica를 본질적으로 제공하지도 않습니다. 이는 가변적 workload에 대한 비용 최적화를 다루며, RPO=0 및 zone-outage survivability와 같은 엄격한 HA 요구 사항을 위한 것이 아닙니다.
Azure SQL Managed Instance Business Critical은 여러 replica와 synchronous replication을 사용하는 Always On availability group 아키텍처를 기반으로 하며, 이를 통해 RPO 0(데이터 손실 없음)으로 automatic failover가 가능합니다. Zone redundancy(지원되는 경우)를 사용하면 replica가 Availability Zones에 걸쳐 배치될 수 있어 zone outage 동안에도 database를 계속 사용할 수 있습니다. 주어진 옵션 중 두 가지 reliability 요구 사항을 모두 가장 잘 충족합니다.
Azure SQL Database Basic은 작고 요구 사항이 낮은 workload를 위한 것이며, 데이터 손실 없는 failover에 필요한 multi-replica synchronous 아키텍처를 제공하지 않습니다. 또한 zone outage 동안에도 계속 사용 가능해야 하는 고급 HA/zone redundancy 기능도 지원하지 않습니다. 비용은 최소화하지만 reliability 요구 사항을 충족하지 못합니다.
Azure SQL Database Standard는 일반적인 workload를 위한 하위 service tier이며, Business Critical과 같은 synchronous multi-replica 고가용성 아키텍처를 제공하지 않습니다. 따라서 요구 사항이 데이터 손실 없는 replica 간 failover를 명시적으로 요구하는 경우 올바른 선택이 아닙니다. 또한 mission-critical database workload에 기대되는 수준의 zone-resilient availability도 제공하지 않습니다. 비용은 더 저렴하지만, 명시된 복원력 요구 사항을 충족하지 못합니다.
문제 분석
핵심 개념: 이 문제는 Azure SQL의 고가용성 및 복원력 선택, 특히 데이터 손실 없음(synchronous replication)과 zone outage 복원력을 달성하면서 비용을 최소화하는 방법을 테스트합니다. Azure SQL에서 이러한 요구 사항은 여러 replica와 automatic failover를 사용하는 HA 아키텍처에 매핑됩니다. 정답인 이유: Azure SQL Managed Instance (MI) Business Critical은 region 내에서 여러 replica와 synchronous replication을 사용하는 Always On availability group 아키텍처를 사용합니다. 이를 통해 transaction은 synchronous replica에 안전하게 기록된 후에만 commit되므로 RPO 0(데이터 손실 없음)으로 automatic failover가 가능합니다. Business Critical은 또한 zone redundancy(지원되는 region에서)를 지원하므로 replica를 Availability Zones 전체에 분산할 수 있어 zone outage 동안에도 database를 계속 사용할 수 있습니다. 나열된 옵션 중에서 “데이터 손실 없는 replica 간 failover”와 “zone outage 중에도 사용 가능”에 가장 명확하게 부합하는 것은 이것뿐입니다. 주요 기능 / 구성: - 여러 replica 간 synchronous replication(RPO 0) 및 automatic failover. - 기본 제공 HA; clustering/AG를 직접 관리할 필요가 없음. - 전체 zone 장애를 견디기 위한 zone redundancy 옵션(지원되는 경우). - Azure Well-Architected Framework의 reliability pillar와 일치: redundancy, fault isolation(zones), automated failover. 일반적인 오해: - “Standard” 또는 “Premium” Azure SQL Database tier도 HA를 제공할 수 있지만, 이 문제는 replica 간 데이터 손실 없는 failover와 zone outage 복원력을 명시적으로 강조합니다. 이러한 요구 사항은 zone 분산을 갖춘 synchronous multi-replica 아키텍처를 강하게 시사하며, 모든 tier/offerings가 Business Critical과 같은 방식으로 이를 보장하는 것은 아닙니다. - “Serverless”는 엄격한 HA/zone-outage 요구 사항이 아니라 간헐적 workload에 대한 auto-pause/auto-scale을 통한 비용 최적화에 중점을 둡니다. 시험 팁: - RPO 0은 일반적으로 synchronous replication을 의미합니다. - Zone outage 복원력은 단일 datacenter 내의 local redundancy만이 아니라 zone-redundant deployment(replica를 AZ 전체에 배치)를 필요로 합니다. - 옵션에 “Business Critical”이 포함되어 있으면 여러 replica, synchronous commit, 그리고 가장 강력한 in-region HA 특성과 연관 지으십시오. 문제에서 cross-region DR도 요구했다면 active geo-replication 또는 auto-failover groups(대개 asynchronous, RPO > 0)를 찾아야 합니다.
다음 작업을 수행하는 Service1이라는 .NET web service가 있습니다: ✑ 로컬 파일 시스템에 임시 파일을 읽고 씁니다. ✑ Application event log에 씁니다. Azure에서 Service1을 호스팅하기 위한 솔루션을 권장해야 합니다. 이 솔루션은 다음 요구 사항을 충족해야 합니다: ✑ 유지 관리 오버헤드를 최소화합니다. ✑ 비용을 최소화합니다. 권장 사항에 무엇을 포함해야 합니까?
Azure App Service web app은 유지 관리를 최소화하는 관리형 PaaS 제품이지만, 고객 애플리케이션에 Windows Application event log에 대한 직접 액세스를 제공하지 않습니다. App Service는 임시 로컬 스토리지를 제공하지만, 이는 두 가지 기술 요구 사항 중 하나만 충족합니다. event log 쓰기를 App Service diagnostics 또는 Application Insights로 대체하려면 애플리케이션 동작을 변경해야 하며, 문제에서는 이를 허용하지 않습니다. 따라서 App Service는 더 저렴하고 관리가 더 쉽더라도 명시된 요구 사항을 완전히 충족할 수 없습니다.
Azure virtual machine scale set은 guest Windows 운영 체제에 대한 전체 제어를 제공하므로 애플리케이션이 로컬 파일 시스템에 임시 파일을 쓰고 Windows Application event log에 직접 항목을 쓸 수 있습니다. 이는 애플리케이션 설계를 변경하지 않고도 명시된 두 가지 동작을 모두 기본적으로 지원하는 목록 내 유일한 선택지입니다. VM scale set은 PaaS 서비스보다 더 많은 관리가 필요하지만, 자동 확장과 중앙 집중식 인스턴스 관리를 여전히 제공하므로 사용 가능한 선택지 중 가장 적합합니다. 요구 사항은 작성된 그대로 충족되어야 하므로, App Service에 비해 유지 관리가 더 많더라도 VM scale set이 올바른 권장 사항입니다.
App Service Environment는 여전히 Azure App Service 기반이므로 Windows Application event log에 대한 직접 액세스와 관련해 동일한 플랫폼 제한이 있습니다. 이는 격리, 네트워킹 제어 및 전용 용량을 제공하지만, Event Viewer에 쓰기 위한 guest OS 수준 제어는 제공하지 않습니다. 또한 ASE는 다른 선택지보다 훨씬 더 비싸며 비용을 최소화해야 한다는 요구 사항과 직접적으로 충돌합니다. 기술적 적합성과 비용 목표를 모두 충족하지 못하므로 올바른 권장 사항이 아닙니다.
Azure Functions app은 Windows OS 기능에 의존하는 기존 web service를 호스팅하기 위한 것이 아니라 event-driven 실행 패턴을 위한 serverless 컴퓨팅 옵션입니다. Functions는 제한적인 방식으로 임시 로컬 스토리지를 사용할 수 있지만, 애플리케이션 쓰기를 위해 Windows Application event log를 노출하지는 않습니다. App Service와 마찬가지로 대신 Application Insights를 사용하는 것은 명시적 요구 사항을 충족하는 것이 아니라 재설계에 해당합니다. 따라서 Functions는 적절한 워크로드에 대해 운영 오버헤드와 비용을 줄일 수 있더라도 요구 사항을 충족하지 못합니다.
문제 분석
핵심 개념: 이 문제는 특정 OS 수준 동작을 지원하면서 유지 관리와 비용의 균형을 맞출 수 있는 Azure 호스팅 모델을 선택하는 것에 관한 것입니다. 핵심 기술 요구 사항은 .NET web service가 로컬 파일 시스템에 임시 파일을 쓰고 Windows Application event log에 쓴다는 점입니다. 이러한 기능은 기본 Windows 운영 체제에 대한 액세스가 필요한 호스트 수준 기능입니다. 정답인 이유: Azure virtual machine scale set은 로컬 파일 시스템과 Windows Application event log를 포함하여 전체 Windows OS 액세스를 제공하는 유일한 선택지입니다. VM scale set은 IaaS이므로 PaaS 제품보다 더 많은 유지 관리가 필요하지만, 명시된 기술 요구 사항을 실제로 충족할 수 있는 선택지 중에서는 여전히 비용이 가장 적게 들고 운영 부담도 가장 적습니다. App Service와 Functions는 고객 애플리케이션에 Windows Application event log를 노출하지 않으며, ASE도 여전히 App Service 기반이므로 동일한 제한이 있으면서 비용은 훨씬 더 많이 듭니다. 주요 기능: - VM scale set은 Windows Server 인스턴스에 대한 전체 관리 제어를 제공합니다. - 애플리케이션은 온-프레미스에서와 마찬가지로 로컬 디스크와 Windows Application event log에 쓸 수 있습니다. - scale set은 개별 VM과 비교해 탄력성과 중앙 집중식 관리를 추가로 제공하므로 IaaS 모델 내에서 운영 부담을 어느 정도 줄이는 데 도움이 됩니다. 일반적인 오해: - App Service는 임시 로컬 스토리지를 지원하지만, 그렇다고 해서 Windows Application event log에 쓰기를 지원한다는 의미는 아닙니다. - ASE는 OS 액세스를 위한 다른 컴퓨팅 모델이 아닙니다. 이는 격리된 App Service 배포이며 여전히 직접적인 event log 액세스를 제공하지 않습니다. - Azure Functions는 serverless이며 일부 워크로드에서는 비용 효율적이지만, Windows Application event log에 써야 하는 요구 사항은 충족하지 못합니다. 시험 팁: 요구 사항에 Event Viewer, Windows services, registry 액세스 또는 직접적인 머신 수준 로깅과 같은 Windows OS 기능이 명시적으로 언급되면, 문제에서 애플리케이션 재설계를 명시적으로 허용하지 않는 한 IaaS를 우선 고려하십시오. 아키텍처 시험에서는 문제 문구가 애플리케이션 동작을 수정할 수 있다고 말하지 않는 한, 명시된 요구 사항을 cloud-native 대안으로 대체할 수 있다고 가정하지 마십시오.
PII(개인 식별 정보)를 저장할 Azure SQL database를 배포할 계획입니다. 권한이 있는 사용자만 PII를 볼 수 있도록 해야 합니다. 솔루션에 무엇을 포함해야 합니까?
Dynamic Data Masking (DDM)은 원본 데이터를 볼 권한이 없는 사용자에 대해 쿼리 결과의 민감한 column 값을 가립니다. UNMASK 권한 또는 이에 상응하는 관리 access가 부여된 사용자와 같은 권한 있는 사용자는 실제 값을 볼 수 있습니다. 이는 권한이 있는 사용자만 PII를 볼 수 있어야 한다는 요구 사항을 직접적으로 충족합니다. DDM은 쿼리 시점에 동작하며 기본 저장 데이터를 수정하지 않으므로, application logic을 변경하지 않고 민감한 필드를 보호하는 데 매우 적합합니다.
Azure의 role-based access control (RBAC)은 management plane을 통해 Azure 리소스(subscription, resource group, SQL server resource)에 대한 access를 제어합니다. 이것만으로는 사용자가 Azure SQL Database 내부에서 어떤 데이터를 쿼리할 수 있는지를 제한하지 않습니다. data-plane 권한은 Azure RBAC만이 아니라 SQL login/user, database role, 그리고 DDM/RLS와 같은 기능으로 처리됩니다.
Data Discovery & Classification은 Azure SQL에서 민감한 데이터 column(예: PII)을 검색, 레이블 지정, 추적하는 데 도움을 줍니다. 이는 거버넌스, 보고, 그리고 권장 사항 유도(예: Microsoft Defender for SQL에서)를 지원하지만, 권한이 있는 사용자만 데이터를 볼 수 있도록 강제하지는 않습니다. 이는 access control 메커니즘이 아니라 보완적인 거버넌스 기능입니다.
Transparent Data Encryption (TDE)은 database, log, backup을 저장 시점에 암호화하여 파일이나 backup에 대한 오프라인 access로부터 보호합니다. 그러나 database를 쿼리할 수 있는 사용자가 결과에서 PII를 보는 것을 막지는 않습니다. TDE는 저장 중 암호화 요구 사항을 해결하며, 권한 있는 사용자와 비권한 사용자의 선택적 가시성을 해결하지는 않습니다.
문제 분석
핵심 개념: 이 문제는 Azure SQL Database 기능 중 쿼리 결과에서 PII와 같은 민감한 데이터의 노출을 제한하여, 명시적인 권한이 있는 사용자만 실제 값을 볼 수 있게 하는 기능이 무엇인지 묻습니다. 정답인 이유: Dynamic Data Masking (DDM)은 데이터를 쿼리하는 사용자 중 마스킹되지 않은 값을 볼 권한이 없는 사용자에게 민감한 column 값을 마스킹합니다. UNMASK 권한 또는 이에 상응하는 높은 수준의 관리 권한과 같은 적절한 권한이 부여된 사용자는 실제 데이터를 볼 수 있습니다. 이는 권한이 있는 사용자만 PII를 볼 수 있고 다른 사용자는 마스킹된 결과를 받도록 해야 한다는 요구 사항과 정확히 일치합니다. 주요 기능 / 사용 방식: DDM은 column 수준에서 구성되며 default, email, random, partial string masking과 같은 masking 함수를 지원합니다. 이는 쿼리 시점에 적용되므로 저장된 데이터 자체는 변경되지 않습니다. 따라서 application 변경 없이 application, report, 지원 시나리오에서 PII의 우발적인 노출을 줄이는 데 유용합니다. 흔한 오해: Azure RBAC는 종종 database 수준의 데이터 보호와 혼동되지만, 주로 SQL 쿼리 결과 내부 데이터의 선택적 가시성이 아니라 Azure 리소스에 대한 management-plane access를 제어합니다. TDE도 또 다른 흔한 오답 유도 선택지인데, 이는 저장 중인 데이터를 보호할 뿐 사용자가 database를 성공적으로 쿼리한 후 무엇을 보는지는 보호하지 않습니다. Data Discovery & Classification은 민감한 데이터를 식별하고 레이블을 지정하지만, masking 또는 access restriction을 강제하지는 않습니다. 시험 팁: 일부 사용자에게는 민감한 값을 숨기면서도 table 쿼리는 허용해야 하는 요구 사항이라면 Dynamic Data Masking을 떠올리십시오. database 파일과 backup의 암호화가 요구 사항이라면 TDE를 떠올리십시오. 거버넌스를 위해 민감한 column을 식별하는 것이 요구 사항이라면 Data Discovery & Classification을 떠올리십시오. Azure 리소스 관리가 요구 사항이라면 RBAC를 떠올리십시오.

지금 학습 시작하기
Cloud Pass를 다운로드하고 Microsoft AZ-305 자격증 학습을 이어가세요.