
Practice Test #2
50개 문제와 100분 시간 제한으로 실제 시험을 시뮬레이션하세요. AI 검증 답안과 상세 해설로 학습하세요.
AI 기반
3중 AI 검증 답안 및 해설
GPT Pro, Claude Opus, Gemini Pro가 답안과 해설을 교차 검증합니다. 선택지별 근거부터 요구사항 분해와 정답 아키텍처까지 확인하세요.
실전형 문제
온-프레미스 네트워크에 Share1이라는 이름의 SMB 공유가 있습니다. 다음 리소스를 포함하는 Azure 구독이 있습니다: ✑ webapp1이라는 웹 앱 ✑ VNET1이라는 가상 네트워크 webapp1이 Share1에 연결할 수 있도록 해야 합니다. 무엇을 배포해야 합니까?
참고: 이 질문은 동일한 시나리오를 제시하는 일련의 질문 중 일부입니다. 이 시리즈의 각 질문에는 명시된 목표를 충족할 수도 있는 고유한 솔루션이 포함되어 있습니다. 일부 질문 세트에는 정답이 둘 이상 있을 수 있으며, 다른 세트에는 정답이 없을 수도 있습니다. 이 섹션의 질문에 답한 후에는 해당 질문으로 돌아갈 수 없습니다. 따라서 이러한 질문은 검토 화면에 표시되지 않습니다. Subscription1이라는 Azure 구독이 있습니다. Subscription1에는 RG1이라는 리소스 그룹이 포함되어 있습니다. RG1에는 templates를 사용하여 배포된 리소스가 포함되어 있습니다. RG1에서 리소스가 생성된 날짜와 시간을 확인해야 합니다. 솔루션: Subscriptions 블레이드에서 구독을 선택한 다음 Programmatic deployment를 클릭합니다. 이것이 목표를 충족합니까?
가능한 한 빠르게 5개의 인스턴스를 포함하는 Azure virtual machine scale set을 배포해야 합니다. 무엇을 해야 합니까?
회사에는 세 개의 사무실이 있습니다. 사무실은 Miami, Los Angeles, New York에 위치해 있습니다. 각 사무실에는 datacenter가 있습니다. East US 및 West US Azure region에 리소스가 포함된 Azure subscription이 있습니다. 각 region에는 virtual network가 있습니다. virtual network는 peered되어 있습니다. datacenter를 subscription에 연결해야 합니다. 솔루션은 datacenter 간 network latency를 최소화해야 합니다. 무엇을 생성해야 합니까?
webapp1이라는 Azure web app이 있습니다. VNET1이라는 virtual network과 MySQL database를 호스팅하는 VM1이라는 Azure virtual machine이 있습니다. VM1은 VNET1에 연결됩니다. webapp1이 VM1에서 호스팅되는 데이터에 액세스할 수 있도록 해야 합니다. 무엇을 해야 합니까?
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
HOTSPOT - Subscription1이라는 Azure 구독이 있으며, 다음 표에 표시된 리소스를 포함합니다:
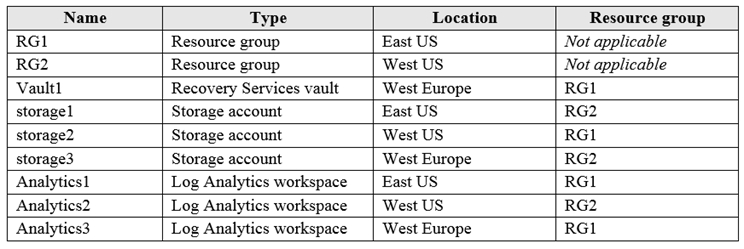
Vault1에 대해 Azure Backup reports를 구성할 계획입니다. AzureBackupReports 로그에 대한 Diagnostics settings를 구성하고 있습니다. Vault1의 Azure Backup reports에 사용할 수 있는 storage accounts와 Log Analytics workspaces는 무엇입니까? 답하려면, 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
Storage accounts: ______
Log Analytics workspaces: ______
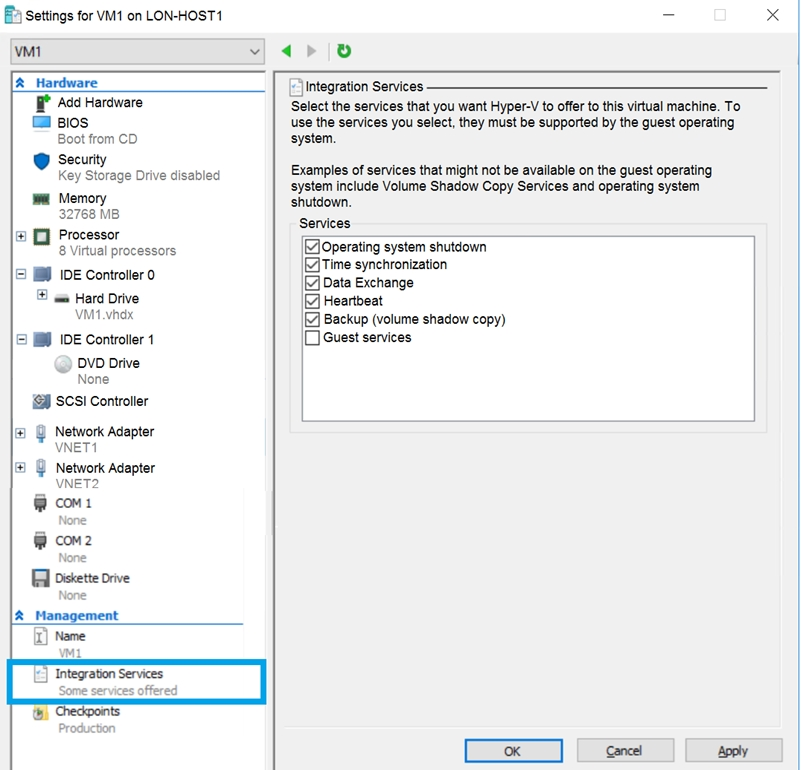
Azure 구독이 있습니다. 온-프레미스 가상 머신 VM1이 있습니다. VM1의 설정은 전시(Exhibit)에 표시되어 있습니다. (Exhibit 탭을 클릭하세요.)
VM1에 연결된 디스크를 Azure 가상 머신의 템플릿으로 사용할 수 있도록 해야 합니다. VM1에서 무엇을 수정해야 합니까?
그림의 설정 중 VM 디스크를 Azure VM 템플릿으로 사용할 수 있도록 활성화해야 하는 항목은 무엇인가요?
HOTSPOT - Scale1이라는 이름의 virtual machine scale set을 만듭니다. Scale1은 다음 전시에서와 같이 구성됩니다.
드롭다운 메뉴를 사용하여 그래픽에 제시된 정보를 기반으로 각 문장을 완성하는 답안을 선택하십시오. 참고: 각 정답 선택은 1점입니다. Hot Area:
그림:
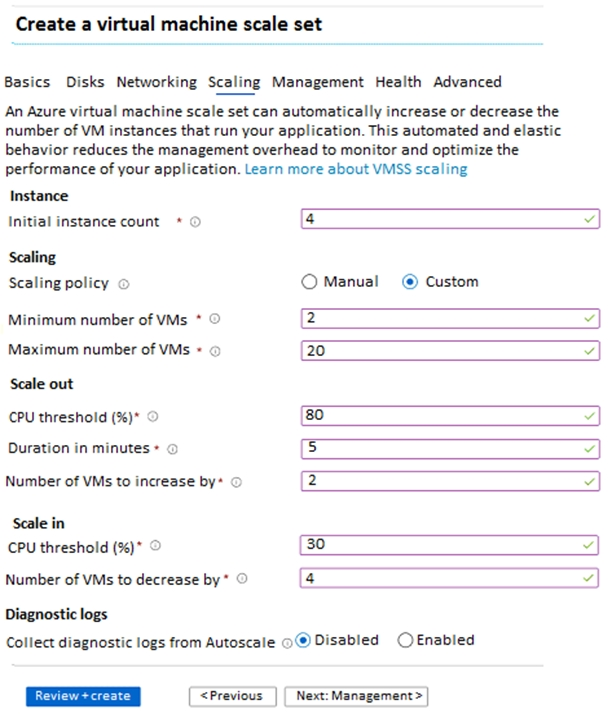
Scale1이 배포된 후 6분 동안 85%로 사용된다면, Scale1은 ______로 실행되고 있을 것입니다.
Scale1이 배포된 후 처음 6분 동안 25%로 사용되고, 그 다음 6분 동안 50%로 사용된다면, Scale1은 ______로 실행 중일 것입니다.
HOTSPOT - Azure 지역 East US 2에 Azure Storage account를 생성할 계획입니다. 다음 요구 사항을 충족하는 storage account를 생성해야 합니다. ✑ 동기적으로 복제합니다. ✑ 해당 지역에서 단일 data center에 장애가 발생하더라도 가용성을 유지합니다. storage account를 어떻게 구성해야 합니까? 답하려면 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. Hot Area:
복제: ______
계정 유형: ______
HOTSPOT - 다음 표에 표시된 엔드포인트가 있는 Azure File sync group이 있습니다.
Endpoint3에 대해 Cloud tiering이 활성화되어 있습니다. Endpoint1에 File1이라는 파일을 추가하고 Endpoint2에 File2라는 파일을 추가합니다. 파일을 추가한 후 24시간 이내에 File1과 File2를 사용할 수 있는 엔드포인트는 어디입니까? 답하려면 답안 영역에서 적절한 옵션을 선택하십시오. 참고: 각 정답 선택은 1점입니다. Hot Area:
Endpoint1은 Cloud endpoint입니다.
Endpoint2는 Server endpoint입니다.
Endpoint3는 Server endpoint입니다.
File1: ______
파일2: ______
다른 모의고사
Practice Test #1
Practice Test #3
Practice Test #4
Practice Test #5
Practice Test #6
Practice Test #7
Practice Test #8
Practice Test #9

지금 학습 시작하기
Cloud Pass를 다운로드하고 Microsoft AZ-104 자격증 학습을 이어가세요.