
Describe Artificial Intelligence Workloads and Considerations출제율 19%
무료 문제 체험
문제를 직접 풀고 해설 품질을 확인하세요
정답을 고른 뒤 선택지별 근거, 핵심 학습 포인트와 관련 서비스를 바로 확인할 수 있습니다.
1
문제 1
DRAG DROP - 머신 러닝 유형을 적절한 시나리오와 매칭하세요. 답하려면 왼쪽 열에서 적절한 머신 러닝 유형을 오른쪽의 해당 시나리오로 끌어다 놓으세요. 각 머신 러닝 유형은 한 번만 사용할 수도, 여러 번 사용할 수도, 또는 전혀 사용하지 않을 수도 있습니다. 참고: 각 정답 선택은 1점입니다. 선택 및 배치:
파트 1:
공항의 적설량을 기반으로 항공편이 몇 분 늦게 도착할지 예측한다. ______
“몇 분 늦는지”를 예측하는 것은 연속적인 숫자 값(분)을 예측하는 것입니다. 이는 regression 문제의 결정적 특징입니다. 즉, 모델이 입력 특징(예: 적설량, 공항, 계절, 과거 지연 패턴)과 숫자형 타깃 간의 관계를 학습합니다. 왜 classification이 아닌가? 출력이 “정시 / 지연” 또는 “0–15분, 16–30분, 31분 이상 지연”과 같은 범주라면 classification이 적용됩니다. 이는 연속적인 숫자가 아니라 이산적인 class입니다. 왜 클러스터링이 아닌가? 클러스터링은 라벨이 있는 타깃 없이 그룹을 발견하는 데 사용됩니다. 여기서는 타깃 변수(지연 분)가 명확히 존재하고 이를 직접 예측하려는 것이므로 supervised regression이 적절합니다.
파트 2:
마케팅 부서를 지원하기 위해 고객을 서로 다른 그룹으로 세분화합니다. ______
마케팅을 위한 고객 세분화는 전형적인 클러스터링 시나리오입니다. 일반적으로 고객의 속성과 행동(구매 빈도, 평균 주문 금액, 제품 카테고리, 웹사이트 활동, 인구통계) 데이터는 있지만, “Segment A, Segment B”와 같은 레이블은 이미 존재하지 않습니다. 클러스터링 알고리즘은 같은 클러스터 내의 고객들이 다른 클러스터의 고객들보다 서로 더 유사하도록 고객을 그룹화합니다. 왜 분류가 아닌가? 분류는 과거 데이터에 미리 정의된 세그먼트 레이블이 필요합니다(예: 각 고객의 세그먼트를 이미 알고 있고, 신규 고객에 대해 이를 예측하려는 경우). 여기서는 그런 전제가 암시되지 않습니다. 왜 회귀가 아닌가? 회귀는 숫자 값(예: lifetime value)을 예측합니다. 세분화는 그룹화에 관한 것이지, 연속적인 숫자를 예측하는 것이 아닙니다.
파트 3:
학생이 대학교 과정을 완료할지 여부를 예측하시오. ______
학생이 과정을 완료할지 여부를 예측하는 것은 예/아니오 결과이므로, 이진 분류 문제입니다. 모델은 출석, 과제 제출, 성적, 참여도 지표, 이전 수강 이력과 같은 특징을 사용하여 두 개의 이산 클래스(“완료” 또는 “미완료”) 중 하나를 예측합니다. 왜 회귀가 아닌가? 회귀는 “최종 성적 백분율” 또는 “완료까지 남은 주 수”처럼 연속적인 값을 예측할 때 사용됩니다. 예/아니오를 1/0으로 인코딩하더라도, 원하는 출력이 범주이기 때문에 근본적인 과제는 여전히 분류입니다. 왜 클러스터링이 아닌가? 클러스터링은 행동 패턴에 따라 학생들을 그룹화할 수는 있지만, 추가적인 해석 없이 완료 여부라는 라벨이 있는 질문에 직접 답하지는 못합니다.
2
문제 2
HOTSPOT - 문장을 완성하려면 답안 영역에서 적절한 옵션을 선택하세요. 핫 영역:
파트 1:
대출이 상환될지 여부를 예측하는 은행 시스템은 기계 학습의 ______ 유형의 예입니다.
정답: A (classification). 대출이 상환될지 여부를 예측하는 것은 지도 학습 문제이며, 목표는 “상환됨” vs “상환되지 않음”(default)과 같은 이산적인 레이블입니다. 이것이 classification의 정의입니다. 즉, 과거의 레이블이 있는 예시(결과가 알려진 과거 대출)로부터 학습하여 새로운 사례에 대해 범주를 예측합니다. 왜 regression (B)가 아닌가: Regression은 출력이 연속적인 수치 값일 때 사용됩니다. 예를 들어 정확한 대출 손실 금액, 이자율, 또는 고객 생애 가치(customer lifetime value)를 예측하는 경우입니다. 신용 모델이 확률(숫자)을 출력할 수도 있지만, 설명된 핵심 과제—“대출이 상환될지 여부”—는 범주형 판단입니다. 왜 클러스터링 (C)가 아닌가: 클러스터링은 비지도 학습으로, 알려진 레이블 없이 유사성에 따라 데이터 포인트를 그룹화합니다(예: 상환 결과가 없을 때 고객을 위험 그룹으로 세분화). 여기서는 은행이 명확한 결과 예측을 원하므로, 레이블이 있는 학습 데이터와 classification이 필요합니다.
3
문제 3
분류(classification)의 사용 사례는 무엇입니까?
이는 분류가 아니라 회귀입니다. 결과는 “커피를 몇 컵 마시는지”로, 숫자 값(연속 값 또는 카운트 값)입니다. 회귀 모델은 수요 예측이나 소비량 추정처럼 숫자를 예측합니다. 입력 특징(수면 시간)을 사용해 예측하더라도, 예측 값은 범주/레이블이 아닙니다.
이는 군집화(비지도 학습)를 설명합니다. 학습 중에 미리 정의된 레이블(예: “red-themed,” “blue-themed”)이 제공된다고 말하지 않고, 비슷한 색상에 따라 이미지를 분석하고 그룹화하는 작업입니다. 군집화는 데이터에서 자연스러운 그룹을 찾습니다. 분류는 “sunset” vs “forest”처럼 예측할 레이블된 범주가 필요합니다.
이는 이진 분류 사용 사례입니다. 예측 결과는 범주형입니다: 누군가가 자전거를 이용해 통근하는지 여부(Yes/No). 주어진 입력 특징은 집에서 직장까지의 거리이며, 모델은 레이블된 예시로부터 학습합니다. 이는 Azure Machine Learning의 분류 작업과 일치하며 precision/recall 및 AUC 같은 지표로 평가됩니다.
이는 회귀입니다. 예측 타깃은 경주를 달리는 데 “몇 분이 걸릴지”로, 연속적인 숫자 값(시간)입니다. 과거 레이스 기록 시간을 특징으로 사용해 미래 시간을 예측하는 것은 전형적인 회귀 시나리오입니다. 분류라면 대신 “30분 이내로 완주할지: Yes/No” 같은 범주를 예측합니다.
문제 분석
핵심 개념: 이 문제는 분류를 회귀(regression) 및 군집화(클러스터링)와 구분하는 능력을 평가합니다. 머신 러닝에서 분류는 이산적인 범주/레이블(예: Yes/No, Fraud/Not Fraud, Cat/Dog)을 예측합니다. 회귀는 연속적인 숫자 값(예: 시간, 가격, 수량)을 예측합니다. 군집화는 사전에 정의된 레이블 없이 유사성에 따라 항목을 그룹화합니다. 정답인 이유: 옵션 C는 거리를 기반으로 누군가가 자전거를 이용해 출근하는지 여부를 예측하라고 합니다. 목표 결과는 범주형(자전거 이용: Yes/No)입니다. 이는 전형적인 이진 분류 문제입니다. 모델은 레이블이 있는 학습 데이터(입력 특징인 거리—그리고 가능하다면 다른 특징들—가 자전거 이용 여부라는 알려진 레이블과 짝지어진 예시)로부터 결정 경계를 학습합니다. 주요 특징 및 모범 사례: 분류에서는 일반적으로 다음을 수행합니다: - 범주형 타깃을 가진 레이블된 데이터를 사용합니다. - 과적합을 방지하기 위해 데이터를 training/validation/test 세트로 분할합니다. - accuracy, precision, recall, F1-score, AUC(특히 클래스 불균형이 있을 때)와 같은 분류 지표로 평가합니다. - 특징 엔지니어링(예: 거리 구간 binning)과 클래스 불균형 처리(resampling 또는 class weights)를 고려합니다. Azure에서는 이는 Azure Machine Learning 분류 작업(AutoML 또는 custom training)에 해당하며, 작업 유형으로 “Classification”을 선택합니다. 흔한 오해: 많은 학습자가 “예측”을 분류와 혼동합니다. 핵심은 무엇을 예측하느냐입니다: 숫자(회귀) vs 범주(분류). 옵션 A와 D는 예측이지만 숫자 값을 출력하므로 회귀입니다. 옵션 B는 유사성에 따라 그룹화하는 것으로, 분류가 아니라 군집화(비지도 학습)입니다. 시험 팁: AI-900에서는 타깃 변수의 유형을 빠르게 식별하세요: - Yes/No 또는 이름이 있는 범주 => 분류. - 숫자 양/시간 => 회귀. - 레이블 없이 “유사한 항목을 그룹화” => 군집화. 또한 “whether”(종종 분류)와 “how many/how much/how long”(종종 회귀) 같은 표현에도 주의하세요.
4
문제 4
다음 달에 판매될 기프트 카드의 수를 예측하려면 어떤 유형의 머신 러닝을 사용해야 합니까?
Classification은 “판매가 높음/중간/낮음인가?” 또는 “목표 달성 여부: yes/no?”처럼 범주형 레이블을 예측하는 supervised learning입니다. 정확한 숫자 수량을 예측하지는 않습니다. 문제를 class(구간)로 변환할 수도 있지만, 질문은 판매된 기프트 카드의 ‘수’를 묻고 있으며 이는 숫자 예측이므로 classification은 여기서 적합하지 않습니다.
Regression은 units sold, revenue, demand와 같은 숫자 값을 예측하는 supervised learning입니다. 다음 달에 판매될 기프트 카드 수를 예측하는 것은 전형적인 regression/forecasting 시나리오입니다. 과거 판매 데이터와 관련 feature(계절성, 프로모션, 휴일)를 기반으로 학습하고 숫자 추정치를 출력합니다. 이는 문제 설명과 직접적으로 일치합니다.
클러스터링은 레이블된 결과가 없을 때 유사한 항목이나 고객을 그룹화하는 unsupervised learning입니다. 예를 들어 구매 행동에 따라 고객을 세그먼트화할 수는 있지만, 다음 달 기프트 카드 판매 수량을 직접 예측하지는 않습니다. 이 문제는 숫자 값을 forecasting하는 것이므로 클러스터링은 적절하지 않습니다.
문제 분석
핵심 개념: 이 문제는 올바른 머신 러닝 작업 유형을 선택하는 능력을 평가합니다. “다음 달에 판매될 기프트 카드의 수”를 예측하는 것은 숫자 값에 대한 예측이며, 이는 supervised learning—특히 regression에 해당합니다. 정답인 이유: Regression은 목표(레이블)가 연속적인 숫자 값(또는 숫자로 취급되는 count)일 때 사용합니다. 예를 들어 판매 금액, 수요, 온도, 판매된 품목 수 등이 이에 해당합니다. 여기서 레이블은 “다음 달에 판매된 기프트 카드 수”로, 숫자 결과입니다. 과거 데이터(이전 달들의 기프트 카드 판매량)와 관련 feature(계절성, 프로모션, 휴일, 매장 유동 인구, 경제 지표 등)를 사용해 모델을 학습시킵니다. 모델은 feature와 숫자 레이블 간의 관계를 학습한 뒤, 다음 달에 대한 예측 숫자를 출력합니다. Azure에서의 주요 특징 / 수행 방법: Azure Machine Learning에서는 일반적으로 이를 regression 문제(또는 time-series forecasting으로, 종종 regression 스타일 접근으로 구현됨)로 다룹니다. 수행 절차는 다음과 같습니다. - 레이블이 포함된 학습 데이터 준비: feature + 과거 판매량(레이블) - 데이터를 train/validation/test 세트로 분할 - regression 알고리즘 학습(예: linear regression, decision trees/boosting, 또는 regression/forecasting용 AutoML) - MAE, RMSE, R-squared 같은 regression metric으로 평가 Azure Well-Architected Framework 관점에서는 reliability(드리프트 모니터링, 주기적 재학습), cost optimization(컴퓨팅 적정 규모 산정, AutoML 효율적 사용), operational excellence(반복 가능한 학습/배포를 위한 MLOps pipeline)를 보장해야 합니다. 흔한 오해: - “sold”라는 표현 때문에 classification이 그럴듯해 보일 수 있지만, classification은 이산적인 class(예: “높음/중간/낮음 수요”)를 예측하며 정확한 숫자를 예측하지는 않습니다. - 클러스터링은 unsupervised이며 레이블된 목표 없이 유사한 레코드를 그룹화합니다. 다음 달 판매 수량을 직접 예측하지는 않습니다. 시험 팁: 출력이 숫자(가격, 수요, 수량, 매출)라면 regression을 떠올리세요. 출력이 범주(spam/ham, yes/no, 위험 수준)라면 classification을 떠올리세요. 레이블이 없고 데이터를 그룹화한다면 클러스터링을 떠올리세요.
5
문제 5
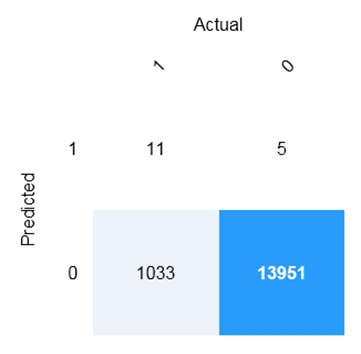
HOTSPOT - 분류를 사용하여 이벤트를 예측하는 모델을 개발하고 있습니다. 다음 전시에서와 같이 테스트 데이터로 점수화된 모델의 혼동 행렬이 있습니다.
드롭다운 메뉴를 사용하여 그래픽에 제시된 정보를 기반으로 각 문장을 완성하는 정답 선택지를 선택하십시오. 참고: 각 정답 선택은 1점입니다. 핫 영역:
파트 1:
정확하게 예측된 양성은 ______개입니다.
“정확하게 예측된 양성”은 True Positives (TP)를 의미합니다. 즉, 모델이 class 1로 예측했고 실제 class도 1인 경우입니다. 혼동 행렬(confusion matrix)에서는 Predicted = 1(행)과 Actual = 1(열)이 만나는 지점, 즉 왼쪽 위 셀입니다. 해당 위치에 표시된 값은 11이므로, 정확하게 예측된 양성은 11개입니다. 다른 선택지가 틀린 이유: - 5는 False Positives (1로 예측, 실제 0)입니다. - 1,033은 False Negatives (0으로 예측, 실제 1)입니다. - 13,951는 True Negatives (0으로 예측, 실제 0)입니다.
파트 2:
______개의 false negative가 있습니다.
False Negative(FN)는 모델이 negative class(0)로 예측했지만 실제 class는 positive(1)인 경우입니다. 이는 놓친 positive를 의미하며, fraud detection이나 medical screening 같은 시나리오에서 종종 매우 중요합니다. confusion matrix에서 FN은 Predicted = 0(행) 및 Actual = 1(열)에 위치하며, 이는 왼쪽 아래 셀입니다. 해당 셀의 값은 1,033이므로 false negative는 1,033개입니다. 다른 선택지가 틀린 이유: - 11은 True Positive(predicted 1, actual 1)입니다. - 5는 False Positive(predicted 1, actual 0)입니다. - 13,951은 True Negative(predicted 0, actual 0)입니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
6
문제 6
HOTSPOT - 문장을 완성하려면 답변 영역에서 적절한 옵션을 선택하세요. 핫 영역:
파트 1:
모델의 예측에 영향을 미치는 데이터 값은 ______라고 합니다.
정답: B. features. Features는 모델이 패턴을 학습하고 예측을 수행하기 위해 사용하는 입력 데이터 값(열)입니다. 예를 들어, 주택 가격 모델에서 면적, 침실 수, 위치는 예측된 가격에 영향을 미치므로 features입니다. 다른 선택지가 틀린 이유: - A. 종속 변수: 대부분의 ML 용어에서 종속 변수는 예측하려는 목표/출력(종종 label과 동의어)을 의미하며, 예측에 영향을 주는 입력이 아닙니다. - C. 식별자: 식별자(예: CustomerID)는 레코드를 고유하게 식별하지만, 일반화 가능한 패턴을 나타내지 않기 때문에 보통 예측 입력으로 사용하지 않아야 합니다. 또한 데이터 누수(data leakage)를 유발할 수 있습니다. - D. labels: Label은 지도 학습에서 학습에 사용되는 알려진 결과/목표 값(예: “price” 또는 “spam/not spam”)이며, 예측에 영향을 미치는 입력 값이 아닙니다.
7
문제 7
(2개 선택)computer vision을 사용하여 수행할 수 있는 두 가지 작업은 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답 선택은 1점입니다.
주가 예측은 일반적으로 time-series 데이터(과거 가격, 지표, 거시 신호)를 사용하는 머신 러닝 forecasting/regression 작업입니다. 이는 이미지를 해석할 필요가 없습니다. Azure에서는 Azure AI Vision보다는 Azure Machine Learning 또는 기타 ML 접근 방식에 더 부합합니다. “AI” 전반과 혼동될 수 있지만, computer vision은 아닙니다.
이미지에서 브랜드를 감지하는 것은 computer vision 기능입니다. 시스템은 픽셀을 분석하여 알려진 로고/브랜드를 식별하며, 종종 브랜드 이름과 bounding box 위치를 반환합니다. Azure AI Vision에서 brand detection은 image analysis 기능의 일부이며, 미디어 모니터링, 컴플라이언스, 마케팅 분석에 일반적으로 사용됩니다.
색상 구성표(dominant colors, accent color, background/foreground colors)를 감지하는 것은 이미지 콘텐츠에서 직접 시각적 속성을 도출하기 때문에 computer vision 작업입니다. Azure AI Vision image analysis는 응답의 일부로 색상 정보를 반환할 수 있습니다. 이는 디자인 컴플라이언스, 카탈로깅, 접근성 관련 시나리오에 유용합니다.
언어 간 텍스트 번역은 NLP 워크로드이며, 일반적으로 Azure AI Translator로 처리합니다. computer vision은 OCR을 통해 이미지에서 텍스트를 추출할 수 있지만, 언어를 번역하는 행위 자체는 vision 작업이 아닙니다. 핵심 구분: 번역은 시각적 이해가 아니라 텍스트/언어를 대상으로 합니다.
핵심 구를 추출하는 것은 텍스트 본문에서 중요한 용어를 식별하는 NLP 작업(text analytics)입니다. Azure에서는 Azure AI Language(Text Analytics 기능)로 제공됩니다. “AI 관련”으로 보일 수 있지만 이미지나 비디오를 분석하지 않으므로 computer vision이 아닙니다.
문제 분석
핵심 개념: 이 문제는 전형적인 Computer Vision 워크로드를 식별하는 능력을 평가합니다. AI-900에서 “computer vision”은 시각적 콘텐츠(이미지/비디오)를 해석하여 객체, 속성, 텍스트 또는 기타 시각적 특징을 식별하는 AI를 의미합니다. Azure에서 이러한 기능은 일반적으로 Azure AI Vision(이전 Cognitive Services의 일부)을 통해 제공되며, image analysis, object detection, tagging, brand detection 등이 포함됩니다. 정답이 맞는 이유: B(이미지에서 브랜드를 감지)는 대표적인 computer vision 작업입니다. Brand detection은 이미지에 존재하는 알려진 로고/브랜드를 식별합니다(예: Microsoft 또는 Coca-Cola 로고 감지). 이는 Azure AI Vision의 image analysis 기능에 내장된 기능입니다. C(이미지에서 색상 구성표를 감지) 또한 computer vision 작업입니다. Image analysis는 지배적인 색상, 강조 색상, 이미지가 흑백인지 여부를 반환할 수 있습니다. 이는 픽셀에서 시각적 속성을 추출하는 것으로, computer vision 범주에 해당합니다. 주요 기능 및 모범 사례: Computer vision 솔루션에는 일반적으로 다음이 포함됩니다. - Image analysis (tags, categories, objects, brands, colors, captions) - OCR (이미지에서 인쇄/필기 텍스트 추출) - Spatial understanding (감지된 objects/brands에 대한 bounding boxes) Azure Well-Architected Framework 관점에서 고려할 사항: - Reliability: 재시도/백오프를 통해 일시적 장애 및 rate limits를 처리합니다. - Security: 전송 중(HTTPS) 및 저장 시 이미지를 보호하고, managed identities 및 least privilege를 사용합니다. - Cost optimization: 가능한 경우 요청을 batch 처리하고 적절한 pricing tiers를 선택합니다. 흔한 오해: 옵션 D와 E는 언어 작업(번역 및 key phrase extraction)으로, computer vision이 아니라 NLP에 속합니다. 옵션 A(주가 예측)는 vision 워크로드가 아니라 time-series forecasting/regression의 머신 러닝 시나리오입니다. 시험 팁: 입력이 이미지/비디오이고 출력이 시각적 속성(objects, brands, colors, 이미지 내 텍스트)이라면 computer vision입니다. 입력이 텍스트이고 출력이 언어 이해(번역, 감정, key phrases)라면 NLP입니다. 입력이 숫자/time-series이고 출력이 예측이라면 머신 러닝 forecasting/regression입니다.
8
문제 8
HOTSPOT - 다음 각 문장에 대해 문장이 참이면 Yes를 선택합니다. 그렇지 않으면 No를 선택합니다. 참고: 각 정답 선택은 1점입니다. 핫 영역:
파트 1:
과거 데이터를 기반으로 주택 가격을 예측하는 것은 이상 탐지의 예이다.
과거 데이터를 기반으로 주택 가격을 예측하는 것은 이상 탐지가 아니다. 핵심 문구는 “과거 데이터를 기반으로 … 예측”이며, 이는 시계열 예측(time-series forecasting) 문제를 의미한다. 즉, 과거 값(그리고 금리, 재고, 계절성 같은 외부 변수도 가능)을 사용해 미래 가격을 예측한다. 목표는 드문 일탈을 식별하는 것이 아니라, 기대되는 미래 값을 추정하는 것이다. 반면 이상 탐지(anomaly detection)는 정상 패턴에서 벗어나는 비정상적인 주택 가격이나 거래를 찾는 데 초점을 둔다(예: 유사 매물 대비 지나치게 높은 매매가로, 데이터 오류나 사기 가능성을 시사). AI-900에서 예측과 이상 탐지는 서로 다른 워크로드 유형이다. 예측은 무엇이 일어날지를 예측하고, 이상 탐지는 정상 동작 대비 무엇이 비정상인지 표시한다. 따라서 정답은 아니오이다.
파트 2:
일반적인 패턴에서 벗어나는 편차를 찾아 의심스러운 sign-in을 식별하는 것은 anomaly detection의 예입니다.
일반적인 패턴에서 벗어나는 편차를 찾아 의심스러운 sign-in을 식별하는 것은 전형적인 anomaly detection 시나리오입니다. 목표는 정상적인 사용자 행동의 baseline에 비추어, 드물거나 비정상적인 이벤트—예: 비정형적인 위치에서의 login, impossible travel(짧은 시간 내에 멀리 떨어진 두 곳에서 sign-in), 비정상적인 device fingerprint, 비정상적인 login 시간, failed attempt의 급증—를 탐지하는 것입니다. 이는 anomaly detection의 정의(대다수와 유의미하게 다른 관측치를 찾는 것)와 직접적으로 일치합니다. anomaly는 계정 탈취나 악성 활동을 나타낼 수 있기 때문에 cybersecurity 및 fraud detection에서 자주 사용됩니다. 이는 주로 forecasting(미래의 수치 값을 예측)이나, 이미 “suspicious” 대 “normal”로 라벨링된 예시가 있는 경우가 아니라면 표준 classification에 해당하지 않습니다. classification을 사용하더라도, 프롬프트의 핵심 개념인 “일반적인 패턴에서의 편차”는 anomaly detection에 해당합니다. 따라서 정답은 예입니다.
파트 3:
환자의 병력을 기반으로 환자가 당뇨병이 발병할지 여부를 예측하는 것은 anomaly detection의 예입니다.
환자의 병력을 기반으로 환자가 당뇨병이 발병할지 여부를 예측하는 것은 anomaly detection이 아니라 classification입니다. 출력은 이산적인 레이블(예: “당뇨병 발병: 예/아니요”)이며, 모델은 결과가 알려진 과거 환자 기록으로 학습됩니다. 이는 supervised learning 작업입니다. anomaly detection은 목표가 비정상적인 환자 측정값이나 정상 집단에서 벗어나는 드문 패턴을 식별하는 것이라면 더 적절합니다(예: 진단되지 않은 상태를 시사할 수 있는 비정상적인 검사 결과를 탐지). 하지만 문제는 특정 결과(당뇨병 발병)를 예측하는 것에 대해 명시적으로 묻고 있으며, 이는 전형적인 binary classification 사용 사례입니다. AI-900에서 기억할 점: classification은 범주를 예측하고, regression은 숫자를 예측하며, forecasting은 시간 기반의 미래 값을 예측하고, anomaly detection은 드문 일탈을 표시합니다. 이 시나리오는 결과 예측(예/아니요)이므로 정답은 아니요입니다.
9
문제 9
머신 러닝 진행을 위해, 학습과 평가를 위해 데이터를 어떻게 분할해야 합니까?
오답입니다. supervised model을 학습하려면 알고리즘이 매핑을 학습하고 loss/error 신호를 계산할 수 있도록 features와 labels가 모두 필요합니다. 평가 또한 예측을 ground truth와 비교하고 metrics(accuracy, RMSE 등)를 계산하기 위해 labels가 필요합니다. 학습에는 features만, 평가에는 labels만 분리하면 입력과 타깃의 row 단위 관계가 깨지며 유효한 분할 전략이 아닙니다.
정답입니다. 표준 접근 방식은 데이터셋을 rows(예시) 기준으로 무작위 분할하여 training set과 evaluation set을 만드는 것입니다. 각 set에는 해당 rows의 features와 labels가 모두 포함됩니다. 이를 통해 모델은 training 예시로부터 학습하고, 보지 못한 예시에서 평가되어 일반화 성능을 추정할 수 있습니다. 무작위화(분류의 경우 종종 stratified)는 bias를 줄이고 대표성을 개선하는 데 도움이 됩니다.
오답입니다. labels만으로는 supervised model을 학습할 수 없습니다. 모델이 label을 예측하는 방법을 학습하려면 입력 features가 필요합니다. 또한 labels 없이 features만으로 평가하면 비교할 ground truth가 없어 성능 metrics를 계산할 수 없습니다. 이 선택지는 features(입력)와 labels(타깃)의 역할을 오해한 것입니다.
오답입니다. columns로 분할한다는 것은 features를 다른 features로부터(또는 label column을) 분리하는 것으로, 문제 정의를 바꾸며 일반적으로 학습/평가를 무효화합니다. 목표는 입력 공간의 일부를 제거하는 것이 아니라 새로운 예시에 대한 일반화를 테스트하는 것입니다. column 분할은 (예: feature ablation studies) 같은 특수한 시나리오에서만 사용되며 표준 평가가 아닙니다.
문제 분석
핵심 개념: 이 문제는 보지 못한 데이터에 대해 모델이 얼마나 잘 일반화하는지 측정하기 위해 학습용 데이터셋과 평가(검증/test) 데이터셋을 분리해서 만드는 기본 머신 러닝 원리를 평가합니다. supervised learning에서는 각 row(예시)가 features(입력)와 label(타깃)을 포함합니다. 분할은 그 관계를 유지해야 합니다. 정답이 맞는 이유: 데이터셋을 rows 기준으로 무작위로 나누어 training set과 evaluation set을 만들어야 합니다. 각 분할에는 해당 rows의 features와 labels가 모두 포함됩니다. 모델은 training rows에서 패턴을 학습하고, evaluation rows에서 모델의 예측을 실제 labels와 비교하여 성능을 평가합니다. 무작위 row 분할은 selection bias를 줄이고 evaluation set이 training과 동일한 기본 분포를 대표하도록 돕습니다. 주요 특징 / best practices: 일반적인 분할 비율은 70/30 또는 80/20이며, 데이터셋이 작다면 k-fold cross-validation을 사용할 수 있습니다. classification의 경우 두 set에서 class 비율을 유사하게 유지하기 위해 stratified split을 선호하는 경우가 많습니다. data leakage를 피하기 위해 데이터로부터 학습하는 preprocessing 단계(예: normalization 파라미터, imputation 값, feature selection)는 training set에서만 fit하고 이후 evaluation에 적용해야 합니다. time-series 시나리오에서는 보통 무작위로 섞지 않고 temporal order를 존중하기 위해 시간 기준으로 분할합니다. 흔한 오해: 자주 하는 실수는 “학습에는 features, 평가는 labels” (또는 그 반대)라고 생각하는 것입니다. labels는 학습 시(손실 계산)에도 필요하고 평가 시(지표 계산)에도 필요합니다. 또 다른 오해는 columns로 분할하는 것인데, 이는 features의 의미를 깨뜨리고 필수 입력을 제거할 수 있어 유효하지 않은 평가를 초래합니다. 시험 팁: AI-900에서는 다음을 기억하세요: supervised learning은 row마다 features + labels를 함께 사용합니다. training set과 evaluation set은 features(columns)가 아니라 예시(rows)를 분할하여 만듭니다. features와 labels를 분리하라는 뉘앙스의 문구를 주의하세요—이는 학습 후 inference/prediction에 대한 질문이 아닌 이상 거의 항상 틀립니다.
10
문제 10
DRAG DROP - 기술 지원 티켓팅 시스템에 Text Analytics API 기능을 적용할 계획입니다. Text Analytics API 기능을 적절한 자연어 처리 시나리오에 매칭하십시오. 답하려면 왼쪽 열의 적절한 기능을 오른쪽의 해당 시나리오로 끌어다 놓으십시오. 각 기능은 한 번, 여러 번 또는 전혀 사용하지 않을 수 있습니다. 참고: 각 정답 선택은 1점입니다. 선택 및 배치:
파트 1:
______ 지원 티켓에 포함된 텍스트를 기반으로 고객이 얼마나 화가 났는지 이해합니다.
Sentiment analysis가 정답인 기능입니다. 이 시나리오는 고객이 얼마나 화가 났는지 이해하는 것이 명시적으로 목적이며, 이는 의견/감정 분류 문제이기 때문입니다. Azure AI Language sentiment analysis는 텍스트를 평가하여 sentiment 레이블(예: negative/neutral/positive)과 종종 confidence score를 반환하며, 티켓에서 가장 negative한 부분을 정확히 찾기 위해 sentence-level sentiment도 제공할 수 있습니다. 다른 선택지가 틀린 이유: - Entity recognition은 구조화된 항목(예: 날짜, 이름, 제품)을 추출하지만 감정을 측정하지는 않습니다. - Key phrase extraction은 중요한 용어/주제(예: “login failure”, “billing issue”)를 식별하지만 고객이 어떻게 느끼는지는 알 수 없습니다. - Language detection은 텍스트의 언어만 식별하며 sentiment를 평가하지 않습니다. 티켓팅 시스템에서 sentiment는 일반적으로 우선순위 지정/에스컬레이션 규칙(예: 매우 negative한 티켓을 시니어 지원으로 라우팅)에 사용됩니다.
파트 2:
______ 지원 티켓에서 중요한 정보를 요약합니다.
Key phrase extraction은 지원 티켓에서 중요한 정보를 요약하는 데 가장 적합합니다. 이 기능은 텍스트의 주요 주제를 나타내는 가장 관련성 높은 단어와 구를 추출합니다(예: “VPN connection”, “authentication error”, “password reset”). 이는 태깅, 검색 인덱싱, 라우팅, 분석 대시보드에 적합한 가벼운 “요약”을 효과적으로 만들어 줍니다. 다른 선택지가 틀린 이유: - Sentiment analysis는 핵심 기술 콘텐츠가 아니라 감정적 톤을 요약합니다. - Entity recognition은 특정 엔터티 유형(날짜, 조직, 제품)을 추출하지만, 더 넓은 주제 구를 놓칠 수 있으며 일반적인 요약을 목적으로 하지 않습니다. - Language detection은 언어만 식별하며 콘텐츠 요약을 제공하지 않습니다. AI-900에서 Text Analytics 맥락의 “중요한 정보 요약”은 일반적으로 추상적 요약(abstractive summarization)(이는 다른 기능임)보다는 key phrase extraction에 해당합니다.
파트 3:
______ 지원 티켓에서 핵심 날짜를 추출합니다.
지원 티켓에서 핵심 날짜를 추출하는 데는 Entity recognition이 정답입니다. 날짜는 Named Entity Recognition (NER)이 감지하고 구조화된 형태로 반환할 수 있는 표준 엔터티 유형이기 때문입니다. 예를 들어 “January 15, 2026”, “last Friday”, “10/12/2025” 같은 값을 날짜/시간 엔터티로 식별하여 티켓 필드를 채우고, 인시던트를 상관 분석하거나, SLA를 검증할 수 있습니다. 다른 선택지가 틀린 이유: - Key phrase extraction은 날짜처럼 보이는 구문을 표면적으로 드러낼 수는 있지만, 날짜를 엔터티로 신뢰성 있게 분류하고 구조화하도록 설계된 기능은 아닙니다. - Sentiment analysis는 어조를 평가하며 날짜 같은 사실 항목을 추출하지 않습니다. - Language detection은 티켓의 언어만 판별합니다. 실무에서는 Entity recognition을 사용해 비정형 티켓 텍스트에서 다양한 구조화 필드(날짜, 제품명, 위치, 사람)를 추출하여 자동화와 리포팅을 지원합니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
11
문제 11
한 회사는 고객에게 전화 및 이메일 지원을 제공하기 위해 고객 서비스 상담원 팀을 고용하고 있습니다. 회사는 일반적인 고객 문의에 대해 자동화된 답변을 제공하기 위해 웹채팅 bot을 개발합니다. 웹채팅 bot 솔루션을 구축한 결과로 회사가 기대해야 하는 비즈니스 이점은 무엇입니까?
응답이 빨라져 고객 만족도가 향상되거나 이탈이 줄어드는 경우 간접적으로 매출이 증가할 수는 있습니다. 그러나 이 시나리오는 리드 생성, 추천, 또는 upsell workflow가 아니라 일반적인 지원 문의에 대한 자동화된 답변에 초점을 맞추고 있습니다. AI-900에서는 매출 성장보다는 운영 효율성이라는, 더 직접적이고 예측 가능한 지원 chatbot의 이점을 선택해야 합니다.
일반적인 질문에 답변하는 웹채팅 bot은 “contact deflection”을 제공하며, 이는 일상적인 이슈가 사람 상담원에게 도달하는 빈도가 줄어든다는 의미입니다. 그 결과 전화/이메일 처리량이 감소하고, 대기열이 짧아지며, 상담원이 복잡한 사례를 처리할 수 있도록 여유가 생깁니다. 이는 고객 지원 시나리오에서 conversational AI/NLP 솔루션과 직접적으로 연결되는 가장 명확하고 즉각적인 비즈니스 이점이며, chatbot 도입의 주요 동기로 흔히 언급됩니다.
제품 신뢰성 향상은 제품의 안정성, 결함 감소, 더 높은 uptime을 의미하며, 일반적으로 더 나은 엔지니어링 관행, 모니터링, 중복성, 테스트를 통해 달성됩니다. 지원 chatbot은 지원 경험을 개선할 수는 있지만, 제품의 근본적인 신뢰성 특성을 직접적으로 바꾸지는 않습니다. 따라서 이 시나리오에서 기대되는 주요 비즈니스 이점이 아닙니다.
문제 분석
핵심 개념: 웹채팅 bot은 Natural Language Processing (NLP) 영역의 AI workload입니다. Azure 시험 컨텍스트(AI-900)에서는 이는 Azure AI Bot Service 및 Azure AI Language(또는 통합된 language understanding 기능)와 같은 conversational AI 솔루션에 해당하며, 사용자 텍스트를 해석하고, intent를 라우팅하며, 자동화된 응답을 제공할 수 있습니다. 정답인 이유: 일반적인 고객 질문에 답변하도록 웹채팅 bot을 배포할 때 가장 직접적이고 기대되는 비즈니스 이점은 사람 고객 서비스 상담원의 업무 부담을 줄이는 것입니다. bot은 24/7로 대량의 반복적인 “Tier 0/Tier 1” 문의(영업시간, 비밀번호 재설정, 주문 상태, 기본 troubleshooting)를 처리할 수 있어 상담원이 처리해야 하는 전화/이메일 건수를 줄입니다. 이는 일반적으로 운영 효율성을 개선하고, 대기 시간을 줄이며, 상담원이 공감, 판단, 또는 전문 시스템 접근이 필요한 복잡하거나 민감한 사례에 집중할 수 있게 합니다. 주요 기능 및 모범 사례: Chatbot은 일반적으로 intent recognition과 entity extraction을 사용해 고객이 원하는 바를 이해하고, 사전 정의된 답변 또는 knowledge base retrieval을 제공합니다. 좋은 구현에는 confidence가 낮을 때 사람 상담원으로 escalation/handoff하는 기능, 새로운 FAQ를 식별하기 위한 logging 및 analytics, 그리고 대화 transcript를 통한 지속적 개선이 포함됩니다. Azure Well-Architected 관점에서 이는 Cost Optimization(일상 문의의 deflection), Operational Excellence(표준화된 응답), Reliability(적절히 설계될 경우 일관된 가용성)를 지원합니다. 흔한 오해: “매출 증가”는 간접적으로(더 나은 응답성) 발생할 수 있지만, FAQ 스타일의 지원 bot에서 1차적으로 보장되는 이점은 아닙니다. “제품 신뢰성 향상”은 제품 자체의 엔지니어링 품질과 uptime에 관련되며, bot이 본질적으로 제품을 더 신뢰성 있게 만들지는 않습니다. 시험 팁: AI-900에서는 시나리오를 workload 유형에 매핑하세요: chatbot = NLP/conversational AI. 그런 다음 가장 즉각적이고 측정 가능한 비즈니스 결과를 선택하세요: contact deflection 및 상담원 업무 부담 감소. bot이 일반적인 문의에 답변한다고 설명되면, 매출 성장이나 제품 엔지니어링 결과보다는 효율성과 지원 확장성 측면의 이점을 기대하는 것이 맞습니다.
12
문제 12
HOTSPOT - 문장을 완성하려면 답변 영역에서 적절한 옵션을 선택하세요. 핫 영역:
파트 1:
AI 시스템에 제공되는 비정상적이거나 누락된 값을 처리하는 것은 책임 있는 AI를 위한 Microsoft ______ 원칙과 관련된 고려 사항입니다.
정답: C (신뢰성 및 안전). “비정상적이거나 누락된 값의 처리”는 불완전하거나 예상치 못한 입력을 만났을 때 AI 시스템이 얼마나 견고하고 신뢰할 수 있는지에 대한 핵심 사항입니다. Microsoft의 책임 있는 AI 원칙에서 신뢰성 및 안전은 AI 시스템이 정상 조건에서 일관되게 동작하고 비정상 조건(예: null 값, 이상치, 손상된 레코드, 예상치 못한 형식)에서는 우아하게 성능이 저하되도록 보장하는 데 초점을 둡니다. 또한 시스템이 불확실하거나 실패하는 상황에서 유해한 결과를 방지하는 것도 포함합니다. 다른 선택지가 틀린 이유: - A (포용성)는 다양한 능력과 배경을 가진 사람들을 지원하고 포함하도록 시스템을 설계하는 것(접근성, 공정한 사용자 경험)에 관한 것이며, 입력 이상/누락 처리에 관한 것이 아닙니다. - B (개인정보 보호 및 보안)는 민감한 데이터 보호, 접근 제어, 암호화, 데이터 유출 또는 적대적 공격에 대한 저항과 관련됩니다. - D (투명성)은 설명 가능성과 시스템이 어떻게 동작하는지, 한계가 무엇인지, 언제 신뢰할 수 없을 수 있는지를 전달하는 것에 관한 것입니다. 관련은 있지만, 누락/비정상 값 처리를 위한 핵심 원칙은 아닙니다. 실무에서는 신뢰성/안전이 검증, 폴백 로직, 모니터링, 엣지 케이스 테스트를 통해 다뤄집니다.
13
문제 13
DRAG DROP - 책임 있는 AI를 위한 Microsoft의 지침 원칙을 해당 설명과 일치시키세요. 답하려면 왼쪽 열에서 적절한 원칙을 오른쪽의 설명으로 끌어다 놓으세요. 각 원칙은 한 번만, 여러 번, 또는 전혀 사용하지 않을 수 있습니다. 참고: 각 정답 선택은 1점입니다. 선택 및 배치:
파트 1:
AI 시스템이 원래 설계된 대로 작동하고, 예상치 못한 조건에 대응하며, 유해한 조작에 저항하도록 보장합니다.
정답: E (Reliability and safety). 이 설명은 AI 시스템이 의도된 설계와 일관되게 동작하고, 예기치 않은 조건을 처리하며, 유해한 조작에 저항해야 함을 강조합니다. 이는 전형적인 reliability/safety 우려 사항입니다: robustness, fault tolerance, adversarial inputs에 대한 resilience, 그리고 edge cases에서의 안전한 운영. 다른 선택지가 틀린 이유: - A (Accountability)는 누가 책임을 지는지와 oversight 및 governance를 보장하는 것에 관한 것이며, 모델의 기술적/운영적 robustness에 관한 것이 아닙니다. - B (Fairness)는 집단 간 차별적 결과를 피하는 데 초점을 둡니다. - C (Inclusiveness)는 접근성과 다양한 능력 및 요구를 가진 사람들에게 솔루션이 작동하도록 보장하는 데 초점을 둡니다. - D (Privacy and security)는 데이터를 보호하고 데이터 사용을 통제하는 데 초점을 두며, 주로 모델의 robustness와 안전한 동작에 관한 것은 아닙니다.
파트 2:
AI 시스템이 내린 결정이 인간에 의해 재정의될 수 있도록 보장하는 프로세스를 구현하는 것.
정답: A (Accountability). 핵심 문구는 AI 결정이 “인간에 의해 재정의될 수 있다”는 점입니다. 이는 human-in-the-loop governance로, 적절한 감독, escalation path, 그리고 자동화된 결정이 부정확하거나 부적절할 때 사람이 개입할 수 있는 능력을 보장하는 것을 의미합니다. Accountability는 또한 결과에 대한 명확한 책임 소재와 auditing 및 remediation을 위한 프로세스를 포함합니다. 다른 선택지가 틀린 이유: - E (Reliability and safety)는 시스템이 안전하고 견고하게 동작하는 것에 관한 것이지만, 인간이 재정의할 수 있어야 한다는 명시적 요구사항은 accountability 및 governance에 더 직접적으로 해당합니다. - D (Privacy and security)는 데이터 보호와 consent에 관한 것이지, 결정 재정의에 관한 것이 아닙니다. - B (Fairness)는 bias와 공정한 결과에 관한 것입니다. - C (Inclusiveness)는 접근성과 다양한 사용자를 고려한 설계에 관한 것입니다.
파트 3:
소비자에게 자신의 데이터 수집, 사용, 저장에 대한 정보와 통제권을 제공한다.
정답: D (프라이버시 및 보안). 이 설명은 소비자에게 자신의 데이터가 어떻게 수집, 사용, 저장되는지에 대한 정보와 통제권을 제공하는 것에 명시적으로 초점을 둡니다. 이는 프라이버시 원칙(투명성, 동의, 데이터 최소화, 적절한 보존)과 보안 원칙(저장/전송 중 데이터 보호, 접근 제어)에 직접적으로 부합합니다. 다른 선택지가 틀린 이유: - A (책임성)는 AI 결과에 대한 감독과 책임에 관한 것이지, 개인 데이터에 대한 사용자 통제권에 관한 것이 아닙니다. - E (신뢰성 및 안전)는 견고하고 안전한 시스템 동작에 관한 것입니다. - B (공정성)는 편향된 결과를 피하는 것에 관한 것입니다. - C (포용성)는 다양한 요구를 가진 사람들이 사용할 수 있고 혜택을 받을 수 있도록 솔루션을 보장하는 것에 관한 것이지, 데이터 거버넌스에 관한 것이 아닙니다.
14
문제 14
(2개 선택)Computer Vision 서비스를 사용하여 수행할 수 있는 두 가지 작업은 무엇입니까? 각 정답은 완전한 솔루션을 제시합니다. 참고: 각 정답 선택은 1점입니다.
오답입니다. 사용자 지정 이미지 분류 모델을 학습시키는 작업은 일반적으로 Azure AI Custom Vision에서 수행하며, 이는 레이블이 지정된 이미지를 사용해 사용자 지정 분류기와 객체 감지기를 구축하고 학습하도록 설계되었습니다. Computer Vision 서비스는 자체 분류 모델을 학습시키기보다는 사전 구축 분석(태그, 캡션, OCR 등)에 초점을 둡니다. AI-900에서는 “사용자 지정 학습”이라는 단서가 Custom Vision을 가리키는 핵심 힌트입니다.
정답입니다. Computer Vision은 이미지에서 얼굴을 찾아 위치를 지정하고 bounding box를 반환하여 얼굴을 감지할 수 있습니다(그리고 API/버전 및 정책 제약에 따라 때로는 관련 특성도 포함). 이는 신원 인식이 아닌 얼굴 감지입니다. AI-900에서는 “얼굴 감지”를 Computer Vision 기능으로 보고, 사람 식별/검증은 Face 서비스와 연관되며 추가 거버넌스 요구 사항이 있다고 이해하면 됩니다.
정답입니다. 손글씨 텍스트 인식은 Computer Vision OCR(종종 Read 기능으로 지칭됨)을 통해 지원됩니다. 이미지와 문서에서 인쇄 및 손글씨 텍스트를 모두 추출할 수 있으며, 텍스트와 함께 위치 정보를 반환합니다. 이는 메모, 양식, 스캔 서류를 디지털화하는 일반적인 워크로드이며, AI-900에서 Computer Vision 기능의 표준 예시입니다.
오답입니다. 언어 간 텍스트 번역은 Azure AI Translator(NLP 서비스)가 수행합니다. Computer Vision은 OCR을 사용해 이미지에서 텍스트를 추출할 수는 있지만, 이를 번역하지는 않습니다. 일반적인 솔루션은 2단계 파이프라인입니다: Computer Vision(OCR)로 텍스트를 읽고, 그다음 Translator로 추출된 텍스트를 대상 언어로 번역합니다.
문제 분석
핵심 개념: 이 문제는 Azure AI Vision(AI-900에서 일반적으로 Computer Vision 서비스로 지칭됨)으로 무엇을 할 수 있는지 평가합니다. Computer Vision은 이미지 분석 및 객체, 태그, 캡션, OCR 텍스트, 얼굴 관련 감지(기능 가용성과 Responsible AI 제약에 따라 다름)와 같은 정보를 추출하기 위한 사전 구축 모델을 제공합니다. 정답이 맞는 이유: B(이미지에서 얼굴을 감지)는 Computer Vision에서 지원하는 기능입니다. 이 서비스는 얼굴의 존재와 위치를 감지할 수 있으며(예: bounding box 반환), 시험 맥락에서 “얼굴 감지”는 “사람을 식별/검증”하는 것과 구분되며, 후자는 더 엄격한 액세스 요구 사항이 있는 Azure Face(별도의 기능/서비스 영역)에서 처리됩니다. C(손글씨 텍스트 인식) 또한 Optical Character Recognition(OCR)을 통한 Computer Vision의 핵심 기능입니다. Azure AI Vision Read/OCR은 이미지와 문서에서 인쇄 및 손글씨 텍스트를 추출하여 인식된 텍스트와 레이아웃/좌표를 반환할 수 있습니다. 주요 기능 및 모범 사례: - OCR/Read는 인쇄 및 손글씨 텍스트를 모두 지원하며, 양식, 영수증, 메모, 스캔 문서의 디지털화에 흔히 사용됩니다. - 얼굴 감지는 기하학적 정보(bounding box/landmark)를 반환하지만, 본질적으로 신원 인식을 수행하지는 않습니다. - Azure Well-Architected 관점에서, 관리형 AI 서비스를 사용하면 운영 부담을 줄일 수 있으며(Operational Excellence), Responsible AI 및 개인정보 보호 요구 사항(Security)을 준수할 수 있습니다. 흔한 오해: A는 “이미지 분류”가 비전 작업이므로 그럴듯해 보이지만, 사용자 지정 이미지 분류 모델 학습은 사전 구축 Computer Vision 서비스가 아니라 Azure AI Custom Vision(별도 서비스)에서 수행합니다. D는 OCR이 텍스트를 추출하므로 그럴듯해 보이지만, 언어 간 텍스트 번역은 Azure AI Translator가 수행하는 NLP 작업입니다. 일반적인 패턴은 Computer Vision OCR로 텍스트를 추출한 다음 Translator로 번역하는 것입니다. 시험 팁: - 구분을 기억하세요: 사전 구축 이미지 분석/OCR/얼굴 감지 = Computer Vision; 분류/감지를 위한 사용자 지정 학습 = Custom Vision. - 번역은 비전 기능이 아니라 Translator에서 처리합니다. - 표현에 주의하세요: “얼굴 감지”(가능) vs “사람 인식/식별”(AI-900 관점에서 Computer Vision 아님).
15
문제 15
HOTSPOT - 문장을 완성하려면 답안 영역에서 적절한 옵션을 선택하세요. 핫 영역:
파트 1:
자연어 처리는 ______에 사용할 수 있습니다
정답: A. 이메일 메시지를 업무 관련 또는 개인용으로 분류하는 것은 text classification이라고 하는 대표적인 NLP 작업입니다. 입력은 비정형 텍스트(이메일 제목/본문)이며, 모델 또는 서비스가 언어적 특징(단어, 구, 의미)을 기반으로 레이블/범주를 결정합니다. Azure에서는 Azure AI Language(text classification) 또는 custom text classification과 같은 NLP 기능에 해당합니다. 다른 선택지가 틀린 이유: B(향후 자동차 대여 건수 예측)는 과거 수치 데이터(time series)에 대한 forecasting/regression으로, NLP가 아니라 머신 러닝 워크로드입니다. C(어떤 웹사이트 방문자가 거래를 수행할지 예측)는 일반적으로 clickstream/session 속성과 고객 특성을 사용하는 이진 분류 ML 문제이며, 언어 이해가 필요하지 않습니다. D(극도로 높은 온도가 감지될 때 공장 프로세스 중지)는 sensor/IoT 임계값 또는 anomaly detection 시나리오로, 사람의 언어 처리보다는 telemetry와 운영 규칙을 다룹니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
16
문제 16
Microsoft 뉴스 기사에서 텍스트를 처리하기 위해 natural language processing을 사용합니다. 다음 전시에서 표시된 출력을 받습니다.

어떤 유형의 natural languages processing이 수행되었습니까?
Entity recognition (Named Entity Recognition)은 텍스트에서 현실 세계의 entities에 대한 언급을 식별하고 Person, Organization, Location, DateTime, Quantity와 같은 유형으로 분류합니다. 전시에는 [Organization], [DateTime], [Quantity-Number] 같은 명시적 레이블이 붙은 추출 용어가 표시되며, 이는 Azure AI Language/Text Analytics에서 NER의 대표적인 출력 형태입니다.
Key phrase extraction은 문서의 주요 논점을(예: “distance learning”, “remote learning environments”) 보통 레이블 없이 구 목록 형태로 반환합니다. 일반적으로 Organization, DateTime, Quantity 같은 의미론적 categories를 할당하지 않습니다. 전시에는 typed label이 포함되어 있으므로, 단순 key phrases를 넘어 entity recognition을 나타냅니다.
Sentiment analysis는 텍스트가 positive, negative, neutral, mixed sentiment 중 무엇을 표현하는지 판단하며 종종 confidence scores를 제공합니다. 출력은 문서 또는 문장별 sentiment 레이블과 숫자 점수 형태이지, PersonType, Organization, DateTime으로 분류된 감지 용어 목록이 아닙니다. 전시는 감정이나 의견이 아니라 entities 식별에 관한 것입니다.
Translation은 텍스트를 한 언어에서 다른 언어로 변환합니다(예: English에서 Spanish). 전시는 동일한 English 콘텐츠에 entity types가 주석으로 표시된 것이지, 다른 언어로 번역된 것이 아닙니다. bilingual 출력이나 target-language 텍스트가 없으므로, 여기서 시연된 NLP 기법은 translation이 아닙니다.
문제 분석
핵심 개념: 이 문제는 Azure AI Language(그리고 과거의 Text Analytics)에서 제공되는 NLP 기능인 Named Entity Recognition (NER)을 테스트합니다. NER은 비정형 텍스트에서 “entities”를 식별하고 Person, Organization, Location, DateTime, Quantity, Skill과 같은 사전 정의된 유형으로 분류합니다. 정답이 맞는 이유: 전시에서는 왼쪽에 원본 뉴스 문단이 있고, 오른쪽에는 "now [DateTime]", "students [PersonType]", "Microsoft [Organization]", "175 [Quantity-Number]", "183,000 [Quantity-Number]"처럼 범주가 붙은 추출 용어가 표시됩니다. 이는 entity recognition이 수행하는 작업과 정확히 일치합니다. 즉, 현실 세계의 개념에 대한 언급을 감지하고 의미론적 레이블을 할당합니다. Organization, DateTime, Location, Quantity 같은 typed label의 존재가 핵심 단서입니다. 주요 기능: Azure AI Language에서 entity recognition은 다음을 반환할 수 있습니다: - Entity text spans(문서에서 발견된 단어/구) - Entity categories 및 subcategories(예: Quantity-Number) - Confidence scores - 텍스트 내 offsets/positions(앱에서 하이라이트에 유용) 일반적인 사용 사례로는 인덱싱/검색 보강, 컴플라이언스 및 redaction 워크플로, 고객 지원 분석, Azure AI Search를 활용한 knowledge mining이 있습니다. 흔한 오해: Key phrase extraction도 중요한 용어를 추출하지만, 일반적으로 Organization 또는 DateTime 같은 의미론적 유형으로 레이블을 붙이지는 않습니다. Sentiment analysis는 polarity(positive/negative/neutral)와 confidence scores를 출력하며 entity 목록을 출력하지 않습니다. Translation은 언어 간 텍스트를 변환하는 것이며, 전시에는 언어 변환을 나타내는 내용이 없습니다. 시험 팁: AI-900에서는 출력 형식의 단서를 확인하세요: - Person/Location/Organization/DateTime/Quantity 같은 categories가 보이면 entity recognition입니다. - 유형 없이 “중요한 구”의 짧은 목록만 보이면 key phrase extraction입니다. - sentiment 레이블과 점수가 보이면 sentiment analysis입니다. - 다른 언어로 된 텍스트가 보이면 translation입니다. 또한 이러한 기능은 NLP 워크로드(Azure AI Language)에 속하며, 후속 분석 및 검색을 위해 비정형 텍스트를 구조화하는 데 흔히 사용된다는 점을 기억하세요.
17
문제 17
HOTSPOT - 문장을 완성하려면 답안 영역에서 적절한 옵션을 선택하세요. 핫 영역:
파트 1:
Azure Machine Learning designer에서 다른 사용자가 사용할 수 있도록 실시간 inference pipeline을 서비스로 배포하려면, 모델을 ______에 배포해야 합니다.
정답: B. Azure Container Instances. Azure Machine Learning Designer에서 다른 사용자가 호출할 수 있는(일반적으로 REST endpoint를 통해) 실시간 inference pipeline을 배포하려면, web service를 호스팅하는 compute target에 배포합니다. Azure Container Instances (ACI)는 실시간 endpoint를 위한 표준적이고 가장 간단한 관리형 옵션으로, 개발, 테스트, 그리고 낮음~중간 수준 트래픽의 프로덕션 시나리오에서 흔히 사용됩니다. 인프라 관리가 최소화되며, AI-900 수준 콘텐츠에서 기본 실시간 배포 대상으로 자주 언급됩니다. 다른 선택지가 틀린 이유: A. 로컬 web service는 로컬 테스트/디버깅용이며, 광범위한 사용을 목적으로 하는 cloud-hosted 서비스가 아닙니다. C. AKS도 실시간 호스팅 옵션으로 유효하지만, 일반적으로 대규모 프로덕션(고가용성, autoscaling, 고급 네트워킹)을 위해 선택됩니다. 문제에서 그러한 요구사항을 나타내지 않으므로 ACI가 가장 적절합니다. D. Azure ML compute는 주로 training 및 batch processing에 사용되며, 배포된 실시간 web service endpoint의 일반적인 호스팅 대상이 아닙니다.
18
문제 18
귀사는 병 재활용 기계를 구축하려고 합니다. 재활용 기계는 올바른 형태의 병을 자동으로 식별하고 다른 모든 물품은 거부해야 합니다. 회사는 어떤 유형의 AI 워크로드를 사용해야 합니까?
anomaly detection은 기준선과 비교해 드물거나 비정상적인 패턴을 식별하는 데 초점을 맞추며, 일반적으로 센서 telemetry, 로그 또는 트랜잭션과 같은 수치 데이터에서 사용됩니다. 제조에서 “정상”이 무엇인지 대부분 알고 있을 때 defect detection에 사용할 수도 있습니다. 그러나 이 문제의 핵심 요구사항은 이미지에서 병 형태를 시각적으로 식별하는 것이므로, computer vision 분류/감지가 더 적합합니다.
conversational AI는 자연어를 사용한 상호작용 경험(예: 챗봇, 음성 봇)을 위해 설계되었습니다. 여기에는 의도 인식, 대화 관리, 응답 생성(예: Azure Bot Service)이 포함됩니다. 재활용 기계가 병 형태를 식별하는 것은 대화 또는 대화형 문제(dialog)가 아니므로, conversational AI는 설명된 워크로드에 적합하지 않습니다.
computer vision이 정답인 이유는 기계가 물품이 올바른 병 형태와 일치하는지 시각적으로 인식하고 다른 물품을 거부해야 하기 때문입니다. 이는 image classification 및/또는 object detection에 해당합니다. Azure에서는 사전 구축 기능을 위해 Azure AI Vision을 사용하거나, 다양한 조명과 방향에서의 특정 병 형태로 모델을 학습시키기 위해 Custom Vision을 사용하여 정확한 자동 수락/거부를 구현할 수 있습니다.
natural language processing (NLP)은 텍스트 또는 speech-to-text 시나리오에서 인간 언어를 이해하고 생성하는 작업(감성 분석, 엔터티 추출, 번역, 요약 등)을 다룹니다. 재활용 기계의 입력은 텍스트나 음성 언어가 아니라 물품의 물리적 외형(형태)이므로, NLP는 적절한 AI 워크로드가 아닙니다.
문제 분석
핵심 개념: 이 시나리오는 computer vision 워크로드입니다. 즉, 이미지/비디오를 사용하여 시각적 특성(형태, 크기, 윤곽선)에 기반해 물리적 객체를 감지, 분류 또는 검증하는 것입니다. Azure AI 용어로는 Azure AI Vision(이미지 분석) 및 Custom Vision(항목을 분류하거나 객체를 감지하도록 모델 학습)과 같은 서비스에 해당합니다. 정답인 이유: “올바른 형태의 병을 식별하고 다른 모든 물품은 거부”해야 하는 재활용 기계는 물품을 시각적으로 검사해야 합니다. 핵심 요구사항은 객체의 형태를 인식하고 허용된 클래스(올바른 병)와 일치하는지 여부를 판단하는 것입니다. 이는 전형적인 image classification(이것이 허용된 병 유형인가?) 및/또는 object detection(병이 어디에 있으며 어떤 유형인가?)에 해당하며, 둘 다 computer vision 작업입니다. 주요 기능 / 일반적인 구현 방식: - Image classification: 허용되는 병 vs. 병이 아닌/기타 물품의 라벨링된 이미지로 모델을 학습합니다. 모델은 각 클래스에 대한 확률을 출력합니다. - Object detection: 물품이 서로 다른 위치/방향으로 나타나는 경우, detection이 객체를 찾고 분류할 수 있습니다. - Custom Vision: 일반적인 라벨이 아니라 도메인 특화 인식(귀사의 병 형태)이 필요할 때 자주 사용됩니다. - 운영 고려사항: 조명, 각도, 가림(occlusions), 병 변형을 아우르는 충분한 학습 데이터를 사용하고, 테스트 세트로 검증하며, drift(새로운 병 디자인)를 모니터링합니다. edge/실시간 요구가 있으면 지연 시간을 줄이기 위해 edge 디바이스(예: Azure IoT Edge)에 배포합니다. 흔한 오해: “다른 모든 물품을 거부”가 “이상치(outliers) 탐지”처럼 보일 수 있어 anomaly detection이 그럴듯하게 들릴 수 있습니다. 그러나 anomaly detection은 일반적으로 수치/시계열 데이터(센서 판독값, 트랜잭션)에서 비정상 패턴을 찾거나, 정상 예시는 많고 비정상 예시는 적은 경우의 “defect detection”에 사용됩니다. 여기서 주요 신호는 시각적 형태 인식이므로 computer vision이 적합합니다. 시험 팁: 입력이 이미지/비디오(카메라)이고 목표가 객체, 형태, 이미지 내 텍스트, 장면을 인식하는 것이라면 computer vision을 선택하십시오. NLP는 텍스트/언어, conversational AI는 챗봇/음성 비서, anomaly detection은 메트릭 또는 센서/telemetry 스트림의 이상치 탐지에 사용합니다. (Well-Architected 연계: reliability와 performance를 위해 낮은 지연 시간과 복원력을 고려한 edge inference를 검토하고, security를 위해 카메라 피드와 모델 엔드포인트를 보호하며, cost optimization을 위해 컴퓨팅을 적정 규모로 맞추고 필요할 때만 재학습을 수행하십시오.)
19
문제 19
HOTSPOT - 문장을 완성하려면 답변 영역에서 적절한 옵션을 선택하세요. 핫 영역:
파트 1:
자신의 이미지를 사용하여 객체 감지 모델을 학습시키기 위해 ______ 서비스를 사용할 수 있습니다.
정답: B. Custom Vision. Azure AI Custom Vision은 사용자가 보유한 이미지를 사용해 사용자 지정 computer vision 모델을 학습시키도록 특별히 설계되었습니다. 객체 감지의 경우, 이미지를 업로드하고 객체 주위에 bounding box를 그린 다음 레이블을 지정하고, 새 이미지 내에서 객체를 위치 지정하고 분류할 수 있는 모델을 학습합니다. 이는 “자신의 이미지를 사용하여 객체 감지 모델을 학습”한다는 요구 사항과 정확히 일치합니다. 다른 선택지가 틀린 이유: - A. Computer Vision (Azure AI Vision)은 사전 구축된 모델(예: tagging, OCR, 일반 감지)을 제공하지만, AI-900 맥락에서 사용자가 레이블링한 데이터셋으로 사용자 지정 객체 감지기를 학습하는 주요 서비스는 아닙니다. - C. Form Recognizer (Azure AI Document Intelligence)는 OCR + 레이아웃/필드 추출을 사용하여 문서(양식, 인보이스, 영수증)에서 구조화된 데이터를 추출하기 위한 것이며, 이미지에서의 일반적인 객체 감지 용도가 아닙니다. - D. Video Indexer는 비디오/오디오에서 인사이트(전사, 얼굴, 키워드, 장면)를 추출하기 위한 것이지, 사용자의 정지 이미지를 기반으로 객체 감지 모델을 학습하는 서비스가 아닙니다.
20
문제 20
HOTSPOT - 다음 각 진술에 대해, 진술이 참이면 Yes를 선택합니다. 그렇지 않으면 No를 선택합니다. 참고: 각 정답 선택은 1점입니다. 핫 영역:
파트 1:
Labeling은 학습 데이터를 알려진 값으로 태깅하는 과정입니다.
예. Labeling은 각 학습 예제를 올바른 알려진 값(“ground truth”)과 연관시키는 과정입니다. Supervised learning에서 이러한 label은 모델이 예측하도록 학습하는 대상입니다. 예를 들어, 이미지를 “cat” 또는 “dog”로 태깅하거나, 이메일을 “spam” 또는 “not spam”으로 표시하거나, “house price”와 같은 regression을 위한 숫자 target 값을 할당하는 것입니다. Labeling은 사람이 수동으로 수행할 수도 있고, 규칙이나 기존 시스템이 ground truth를 제공하는 경우 programmatically 수행할 수도 있으며, assisted labeling tools를 통해 수행할 수도 있습니다. Label이 없으면 일반적으로 unsupervised learning(클러스터링, dimensionality reduction) 또는 self-supervised 접근으로 넘어가며, 이는 다른 문제 유형입니다. 따라서 이 문장은 labeling을 학습 데이터를 알려진 값으로 태깅하는 것으로 올바르게 설명합니다.
파트 2:
모델을 학습하는 데 사용한 동일한 데이터를 사용하여 모델을 평가해야 합니다.
아니요. 모델을 학습하는 데 사용한 동일한 데이터를 사용하여 모델을 평가해서는 안 됩니다. 이는 일반화 성능을 측정하지 못하기 때문입니다. 학습 성능은 실제 환경 성능보다 더 좋아 보이는 경우가 많으며, 특히 모델이 과적합(노이즈를 학습하거나 예시를 암기)하는 경우 그렇습니다. 올바른 평가는 학습 중에 모델이 보지 못한 별도의 test dataset(또는 validation dataset)을 사용합니다. 일반적인 접근 방식에는 train/test split, train/validation/test split, 그리고 cross-validation이 포함됩니다. 이는 모델이 새로운 데이터에서 어떻게 동작할지 추정하는 데 도움이 되며, 모델 선택과 hyperparameter tuning에 대해 더 나은 의사결정을 지원합니다. 학습 데이터를 평가에 사용하면 개발 단계에서는 정확해 보이지만 production에서는 실패하는 모델을 배포하게 될 수 있습니다.
파트 3:
Accuracy는 항상 모델의 성능을 측정하는 데 사용되는 주요 지표이다.
아니오. Accuracy가 항상 주요 지표인 것은 아니다. 최적의 지표는 작업의 특성과 서로 다른 오류 유형이 초래하는 결과에 따라 달라진다. 불균형 분류(예: 사기 탐지)에서는, 모델이 다수 클래스를 항상 예측하기만 해도 높은 Accuracy를 달성할 수 있지만 소수 클래스를 완전히 놓칠 수 있다. 이런 경우 recall(sensitivity), precision, F1-score, PR-AUC가 더 유용한 경우가 많다. false positive의 비용이 큰 경우(정상 거래를 사기로 표시)에는 precision이 더 중요할 수 있고, false negative의 비용이 큰 경우(사기를 놓침)에는 recall이 우선될 수 있다. 회귀 문제에서는 Accuracy가 표준 지표가 아니며, MAE나 RMSE 같은 지표를 사용한다. 따라서 Accuracy는 모델 성능의 보편적인 주요 측정값이 아니다.
시험 도메인
출제 비중을 기준으로 먼저 학습할 영역을 정하세요.
Describe Fundamental Principles of Machine Learning on Azure출제율 19%
Describe Features of Computer Vision Workloads on Azure출제율 19%
Describe Features of Natural Language Processing (NLP) Workloads on Azure출제율 19%
Describe Features of Generative AI Workloads on Azure출제율 24%
다른 Microsoft 자격증












지금 학습 시작하기
Cloud Pass를 다운로드하여 Microsoft AI-900 전체 학습을 이어가세요.