
Manage a security operations environment출제율 25%
무료 문제 체험
문제를 직접 풀고 해설 품질을 확인하세요
정답을 고른 뒤 선택지별 근거, 핵심 학습 포인트와 관련 서비스를 바로 확인할 수 있습니다.
1
문제 1
여러 서버가 WWN zoning을 사용하여 Fibre Channel (FC) fabrics를 통해 Storage Center에 연결되어 있습니다. 엔지니어가 최근 서버의 FC HB를 교체했습니다. 이 서버는 더 이상 Storage Center에 연결할 수 없습니다. 문제의 원인은 무엇입니까?
가능성이 낮습니다. “Fault Domains”는 표준 Fibre Channel zoning construct가 아니며, FC fabric을 통한 Storage Center connectivity는 주로 fabric zoning과 storage-side host/initiator mappings에 의해 제어됩니다. array가 initiators를 추적하더라도, 문제는 WWN zoning을 강조하고 있으므로 HBA 교체 직후의 즉각적인 실패 원인은 일반적으로 새 WWPN이 zoning되지 않았기 때문입니다.
WWN zoning에서는 틀렸습니다. zone을 새 switch port로 업데이트하는 것은 port-based zoning(물리적 switch port 기준)에 해당합니다. WWN zoning에서는 동일한 WWPN이 유지되는 한 다른 switch port로 이동해도 zoning 변경이 필요하지 않습니다. 여기서는 HBA가 교체되어 WWPN이 변경된 것이지, 단순히 port만 바뀐 것이 아닙니다.
관련이 없습니다. “Virtual Port mode”는 HBA 교체 후 FC connectivity를 복구하기 위한 일반적인 요구 사항이 아니며, fabric의 근본적인 access control 문제를 해결하지도 않습니다. 설명된 문제는 storage controller port virtualization 설정이 아니라 WWPN 기반 zoning membership과 일치합니다.
정답입니다. FC HBA를 교체하면 HBA port의 WWN/WWPN이 변경됩니다. 이 환경은 WWN zoning을 사용하므로, zone membership에는 여전히 이전 WWPN이 포함되어 있고 새 initiator는 storage targets를 볼 수 없게 차단됩니다. 서버의 zone을 업데이트하여 새 HBA WWN을 포함하고(zoneset 활성화 포함) access를 복구할 수 있습니다.
문제 분석
핵심 개념: 이 문제는 WWN zoning을 사용하는 Fibre Channel SAN access control을 테스트합니다. FC fabrics에서 zoning은 어떤 initiator(서버 HBA ports)가 어떤 target(storage array front-end ports)과 통신할 수 있는지를 결정합니다. 가장 일반적이고 권장되는 방식은 initiator port WWPN/WWN을 기반으로 한 “single initiator zoning”입니다. 정답이 맞는 이유: 엔지니어가 서버의 FC HBA를 교체하면 HBA의 port WWN (WWPN)이 변경됩니다. fabric zoning이 이전 HBA WWPN을 사용하여 구성되어 있었다면, 새 HBA port는 zone set의 멤버가 아닙니다. 그 결과 switch는 새 initiator가 storage targets를 볼 수 있도록 허용하지 않으므로, 서버는 Storage Center에 log in할 수 없고 LUNs를 검색할 수도 없습니다. zone을 업데이트하여 새 HBA의 WWN을 포함하면 connectivity가 복구됩니다. 주요 특징 / best practices: WWN zoning은 switch port 이동 후에도 유지되기 때문에 port-based zoning보다 선호됩니다. 그러나 HBA 교체 시에는 WWPN이 변경되므로 유지되지 않습니다. best practice는 initiator WWPN을 문서화하고, 일관된 naming을 사용하며, vendor guidance에 따라 single-initiator/single-target(또는 single-initiator/multiple-target) zoning을 구현하는 것입니다. hardware 변경 후에는 다음을 검증해야 합니다: (1) HBA WWPN, (2) zoning membership 및 active zoneset, (3) fabric login (FLOGI/PLOGI), (4) storage-side host/initiator registration. 일반적인 오해: 문제가 switch port(port zoning) 또는 storage “fault domain” 설정이라고 생각하기 쉽습니다. 하지만 문제에서 WWN zoning을 사용한다고 명시했으므로, 이는 HBA 교체 후 WWPN 불일치를 직접 가리킵니다. 시험 팁: 문제에서 WWN zoning과 HBA 교체가 언급되면, WWPN이 변경되었고 zoning을 업데이트해야 한다고 가정하십시오. port zoning과 cable/port 이동이 언급되면, 그때는 port 기준으로 zone을 업데이트합니다. 또한 storage arrays는 host/initiator objects도 업데이트해야 하는 경우가 많지만, WWN zoning에서 가장 즉각적인 fabric-level blocker는 zone에 WWPN이 누락된 것입니다. 참고: 이것은 SC-200으로 표시되어 있지만, 이 시나리오는 Microsoft Sentinel/Defender operations보다는 SAN networking/storage administration에 관한 것입니다. infrastructure connectivity troubleshooting 항목으로 접근하십시오.
2
문제 2
한 엔지니어가 10분마다 하나의 replay가 수행되는 replay profile을 생성했습니다. 만료 시간은 1주로 설정되어 있습니다. 엔지니어는 replay 간의 10분 간격을 변경하지 않고 공간 활용도를 개선해야 합니다. 요구 사항을 충족하기 위해 엔지니어가 취해야 할 단계는 무엇입니까?
만료 시간을 줄이면 보존되는 replay 수가 줄어들기 때문에 스토리지가 감소합니다. 그러나 이는 보존 기간(1주에서 더 짧은 기간으로)을 변경하는 것이며, 조사에 부정적인 영향을 줄 수 있고 암묵적인 보존 요구 사항을 위반할 수 있습니다. 문제는 10분 간격을 변경하지 않고 공간 활용도를 개선하는 데 초점을 두고 있으므로, 가장 적절한 선택은 보존 기간 축소가 아니라 최적화 기능입니다.
replay가 active replay로 coalesce되도록 허용하는 것은 스토리지 최적화 방식입니다. 이는 10분 replay 주기를 유지하면서 replay 데이터를 통합하므로 별도의 replay artifact를 많이 저장할 필요가 없습니다. 따라서 필요한 간격을 유지하면서 공간 활용도를 개선할 수 있고, 일반적으로 조사 가치를 유지하므로 수집 빈도를 희생하지 않는 cost optimization과도 부합합니다.
minimum allowed replay interval을 15분으로 설정하는 것은 10분 간격을 유지해야 한다는 요구 사항과 직접 충돌합니다. replay 수를 줄여 스토리지를 절약할 수는 있지만, 수집 주기를 변경하므로 명시된 제약 조건을 충족하지 못합니다.
간격을 24시간으로 변경하면 replay 수와 스토리지 사용량이 크게 줄어들지만, 10분 간격을 유지해야 한다는 명시적 요구 사항을 위반합니다. 또한 조사 세분성도 크게 떨어지므로 주어진 제약 조건에서는 허용 가능한 해결책이 아닙니다.
문제 분석
핵심 개념: 이 문제는 Microsoft Defender for Endpoint (MDE) Live Response의 “replay” 기능과 replay profile이 스토리지 소비에 어떤 영향을 미치는지에 관한 것입니다. replay profile은 replay가 얼마나 자주 캡처되는지(여기서는 10분마다)와 얼마나 오래 보존되는지(만료 시간 1주)를 정의합니다. 스토리지 활용도는 주로 보존되는 replay artifact의 수와 여러 replay를 통합할 수 있는지 여부에 의해 결정됩니다. 정답인 이유: “Allow Replays to coalesce into active Replay”를 선택하면 10분 캡처 간격을 변경하지 않고도 공간 활용도를 개선할 수 있습니다. coalescing은 많은 개별 replay 인스턴스를 유지하는 대신 replay 데이터를 활성 replay로 병합/롤업하여 스토리지 오버헤드를 줄이도록 설계되었습니다. 여전히 동일한 주기(10분마다)로 수집하지만, 백엔드에서 데이터를 통합할 수 있으므로 별도로 저장되는 replay 객체 수와 관련 메타데이터 오버헤드가 줄어듭니다. 주요 기능 및 모범 사례: - Replay interval은 캡처 빈도를 제어하므로, 이를 변경하면 요구 사항을 위반하게 됩니다. - Expiration time은 보존 기간을 제어하므로, 이를 줄이면 공간은 절약되지만 보존 요구 사항이 변경됩니다(그리고 조사 요구 사항이나 정책과 충돌할 수 있습니다). - Coalescing은 캡처 주기를 유지하면서 스토리지 사용량을 줄이는 공간 최적화 기능입니다. Azure Well-Architected Framework 관점(Cost Optimization 및 Operational Excellence)에서 coalescing은 보안 가시성을 줄이거나 운영 요구 사항을 변경하지 않고 리소스 소비를 최적화하므로 선호되는 방법입니다. 일반적인 오해: 흔한 함정은 “만료 시간을 줄입니다”를 선택하는 것입니다. 이는 분명히 스토리지를 줄여주기 때문입니다. 그러나 문제는 보존 기간을 변경하라고 하지 않았고, 10분 간격을 유지하면서 공간 활용도를 개선하라고 했습니다. 시험 시나리오에서 “공간 활용도”는 종종 보존을 약화시키거나 수집 설정을 변경하는 대신 기본 제공 최적화 기능을 사용하는 것을 의미합니다. 시험 팁: - 요구 사항에 “간격을 변경하지 않고”라고 되어 있으면, 간격을 변경하는 모든 옵션(C, D)을 제거합니다. - 보존 기간 변경이 명시적으로 허용되지 않았다면, 문제에서 보존 기간을 수정할 수 있다고 하지 않는 한 expiration time을 줄이는 선택은 피합니다. - 수집 동작을 유지하면서 스토리지를 줄여주는 coalescing/deduplication/aggregation 같은 플랫폼 기능을 찾으십시오.
3
문제 3
(2개 선택)Storage Center Update Utility를 사용하여 Storage Center OS를 성공적으로 업데이트하려면 다음 작업 중 어떤 두 가지가 필요합니까? (두 개를 선택하세요.)
필수는 아닙니다. Storage Center Update Utility 사용은 일반적으로 Storage Center settings의 단순한 “enable utility” checkbox에 의해 제한되지 않습니다. 일부 제품에는 feature toggle이 있지만, SCOS 업데이트 workflow는 일반적으로 GUI checkbox보다 올바른 connectivity, credential, 검증된 upgrade path에 의존합니다. 이 옵션은 admin tool에서 “enable feature” 단계가 흔하기 때문에 그럴듯한 distractor입니다.
필수입니다. SCOS pre-upgrade check는 업데이트를 적용하기 전에 system health, compatibility, prerequisite를 검증합니다. SupportAssist(또는 이를 통해 가능한 support workflow)를 사용하는 것은 일반적으로 upgrade path가 지원되는지 확인하고 알려진 문제를 조기에 식별하는 과정의 일부입니다. 이는 업그레이드 실패를 줄이고 통제된 change management를 위한 모범 사례에 부합합니다.
필수입니다. Live Volume replication은 replication session이 끊기거나, resync되거나, failover behavior를 유발할 수 있기 때문에 controller/OS 업데이트 중 민감할 수 있습니다. 업데이트 전에 replication을 일시 중지하면 data consistency를 유지하고 업그레이드 후 replication 관련 conflict 또는 과도한 resynchronization을 방지하는 데 도움이 됩니다. 이는 storage upgrade runbook에서 일반적인 prerequisite입니다.
필수도 아니고 일반적으로도 틀렸습니다. SupportAssist를 비활성화하는 것은 일반적으로 update utility가 Storage Center와 통신하는 데 필요하지 않습니다. 오히려 SupportAssist는 supportability와 diagnostics를 향상시킵니다. 통신 문제는 일반적으로 support tooling을 비활성화하는 것이 아니라 network/proxy/firewall configuration, 올바른 port, credential로 해결합니다.
필수는 아닙니다. Storage Center Update Utility를 사용하기 위해 특별한 license를 적용하는 것은 일반적으로 SCOS 업데이트의 prerequisite가 아닙니다. licensing은 고급 기능(replication, Live Volume 등)에 적용될 수 있지만, system software를 업데이트하는 기능은 일반적으로 추가 license가 아니라 표준 플랫폼 유지 관리 및 support entitlement의 일부입니다.
문제 분석
핵심 개념: 이 문제는 vendor update utility(Storage Center Update Utility for Dell EMC SC Series/SCOS)를 사용하여 플랫폼 업데이트를 안전하게 수행하는 것에 관한 것입니다. SC-200으로 표시되어 있지만 Azure/Microsoft Sentinel 시나리오는 아니며, change management, pre-upgrade validation, replication/availability 고려 사항에 초점을 맞춘 인프라 운영 문제입니다. 정답인 이유: B가 필요한 이유는 SCOS pre-upgrade check가 OS 업데이트를 적용하기 전에 readiness(상태, firmware compatibility, configuration state, 알려진 blocker)를 검증하는 표준 prerequisite이기 때문입니다. 많은 환경에서 이는 SupportAssist(또는 이에 상응하는 support channel tooling)를 통해 시작되거나 검증되므로 Dell이 upgrade path를 확인하고 업데이트 실패나 data availability 위험을 초래할 수 있는 문제를 식별할 수 있습니다. C가 필요한 이유는 Live Volume replication이 시스템 전반에 걸쳐 추가적인 상태와 조정을 수반하기 때문입니다. SCOS 업데이트 중에는 replication link와 Live Volume 관계가 영향을 받을 수 있습니다(planned failover behavior, link interruption, 또는 resync requirement). replication을 일시 중지/중단하는 것은 replication conflict를 방지하고, split-brain condition의 위험을 줄이며, 업데이트 프로세스가 replication 관련 lock 또는 resynchronization storm 없이 진행될 수 있도록 하기 위한 일반적으로 필요한 단계입니다. 주요 기능 / 모범 사례: Pre-upgrade check는 운영 우수성과 reliability 원칙(Azure Well-Architected Framework와 유사함)에 부합합니다: prerequisite를 검증하고, blast radius를 줄이며, rollback planning을 보장합니다. replication pause는 reliability에 부합합니다: data consistency를 보호하고 의도하지 않은 failover/resync를 방지합니다. 일반적인 오해: 옵션 A, D, E는 “활성화” 단계처럼 들리지만, update utility는 일반적으로 OS 업데이트를 수행하기 위해 특별한 checkbox, SupportAssist 비활성화 또는 추가 license를 요구하지 않습니다. SupportAssist를 비활성화하면 일반적으로 도움이 되기보다 supportability가 저하됩니다. 시험 팁: 업데이트/업그레이드 문제에서는 반복적으로 나타나는 두 가지 요구 사항을 찾으세요: (1) pre-check/health validation 및 (2) consistency 유지를 위해 data movement/replication을 안정화하는 작업(pause/suspend). 옵션이 support tooling을 비활성화하라고 제안한다면, 문서화된 network/proxy 제약으로 인해 명시적으로 요구되지 않는 한 일반적으로 위험 신호입니다.
4
문제 4
(3개 선택)스토리지 관리자가 처음으로 두 Storage Centers 간 replication을 설정하고 있으며, 두 시스템이 통신할 수 있도록 적절한 zoning을 결정해야 합니다. 두 Storage Centers 모두 Virtual Port mode를 사용하고 있습니다. 각 fabric에 설정해야 하는 올바른 세 가지 zone은 무엇입니까? (세 개를 선택하십시오.)
오답입니다. 이 옵션은 system B의 physical WWPN과 system A의 virtual WWPN 사이에 cross-zone을 생성하지만, 이는 이 replication 설정에 필요한 표준 zone 중 하나가 아닙니다. 문서화된 요구 사항은 비대칭 cross-zone이 아니라 physical-to-physical, virtual-to-virtual, 그리고 결합 physical-and-virtual zoning에 기반합니다. 이 zone만으로는 Virtual Port mode replication에 기대되는 완전하거나 올바른 connectivity model을 제공하지 못합니다.
정답입니다. 이 zone은 두 Storage Centers의 모든 physical WWPN을 포함하며, Virtual Port mode가 활성화된 경우에도 physical port가 replication communication model에 계속 참여하므로 필요합니다. array는 적절한 peer discovery와 path 설정을 위해 physical port 가시성이 필요합니다. physical WWPN을 제외하면 문서화된 Virtual Port replication 설정에 필요한 zoning이 불완전해집니다.
정답입니다. 이 zone은 두 시스템의 모든 virtual WWPN을 포함하며, Virtual Port mode가 통신을 위해 virtual ID를 제시하므로 필수적입니다. Replication session과 peer interaction은 이러한 virtual WWPN이 fabric 전반에서 login할 수 있어야 합니다. 이 zone이 없으면 array는 replication에 필요한 virtual port connectivity를 확보할 수 없습니다.
정답입니다. 이 zone은 두 시스템의 physical WWPN과 virtual WWPN을 모두 포함하며, Virtual Port mode에서 초기 replication 구성에 필요한 zoning 집합의 일부입니다. 이는 설정 및 운영 중 필요할 때 array가 사용하는 전체 ID 집합이 보이도록 보장합니다. 일반적인 host zoning에서는 과도할 수 있지만, 이 문제는 적절한 vendor별 replication zone을 묻고 있으므로 여기서는 적절합니다.
오답입니다. 이는 option A의 반대 형태로, system A의 physical WWPN을 system B의 virtual WWPN에 zoning합니다. physical-to-virtual 통신이 필요하다고 가정하면 그럴듯하게 들릴 수 있지만, 이 시나리오에서 요구되는 표준 3-zone 패턴의 일부는 아닙니다. 이 문제는 vendor별 zoning 레이아웃을 인식하는지를 테스트하며, 정답 집합으로 이러한 cross-zone을 사용하지 않습니다.
문제 분석
핵심 개념: 이 문제는 두 array가 모두 Virtual Port mode로 구성되었을 때 Dell Storage Center replication을 위한 Fibre Channel zoning을 테스트합니다. 이 mode에서는 physical WWPN과 virtual WWPN이 모두 array 간 통신에 관련되며, Dell 가이드는 peer array가 fabric 전반에서 replication connectivity를 검색하고 유지할 수 있도록 특정 zone을 요구합니다. 올바른 구성에는 두 시스템의 모든 virtual WWPN을 위한 zone, 두 시스템의 모든 physical WWPN을 위한 zone, 그리고 두 시스템의 physical 및 virtual WWPN을 모두 포함하는 zone이 포함됩니다. 정답인 이유: Option C는 Virtual Port mode가 통신 시 제시되는 ID로 virtual WWPN을 사용하므로 필요하며, 따라서 array는 서로의 virtual port를 볼 수 있어야 합니다. Option B도 필요합니다. 기본 physical port 역시 connectivity model에 참여하며, 적절한 peer communication과 failover 동작을 위해 함께 zoning되어야 하기 때문입니다. Option D는 처음 replication 설정 시 Virtual Port mode에 필요한 zoning pattern을 완성하는 physical-and-virtual 결합 zone입니다. 주요 특징: - Virtual Port mode는 physical WWPN과 virtual WWPN ID를 모두 도입합니다. - Replication zoning은 두 ID 유형을 모두 사용하는 통신을 고려해야 합니다. - 복원력 있는 dual-fabric 운영을 위해 각 fabric에 적절한 zoning을 생성해야 합니다. - 목표는 두 Storage Centers 간 기능적인 peer discovery와 안정적인 replication pathing입니다. 일반적인 오해: 흔한 실수는 Virtual Port mode에서는 virtual WWPN만 중요하다고 가정하여 virtual-to-virtual 또는 physical-to-virtual cross-zone만 선택하는 것입니다. 또 다른 오해는 이것을 최소 권한 host zoning 문제로 보는 것입니다. 이는 array-to-array replication zoning이며, Dell의 요구 패턴은 단순한 host target zoning보다 더 광범위합니다. physical-to-virtual cross-zone만으로는 문서화된 요구 구성을 충족하지 못합니다. 시험 팁: Storage Center replication 문제에서 Virtual Port mode가 언급되면 physical WWPN과 virtual WWPN이 모두 관련된다는 점을 기억하십시오. virtual connectivity, physical connectivity, 그리고 결합 zoning 요구 사항을 명시적으로 모두 포함하는 답안을 찾으십시오. vendor별 replication 설계가 특정 zone 레이아웃을 요구할 때 일반적인 SAN zoning 모범 사례를 과도하게 적용하지 않도록 주의하십시오.
5
문제 5
관리자는 데이터를 원격지 Storage Center로 복제해야 합니다. 양쪽의 데이터는 항상 일치해야 합니다. 관리자는 데이터가 기록되는 즉시 원격 시스템으로 전송되도록 해야 합니다. 원격 시스템과의 통신이 실패하면, 로컬 시스템에 대한 모든 쓰기는 중지되어야 합니다. 요구 사항을 충족하기 위해 관리자는 어떤 옵션을 선택해야 합니까?
High Consistency를 사용하는 synchronous replication은 모든 요구 사항을 충족합니다. 쓰기는 acknowledgment 전에 로컬과 원격 모두에 커밋되므로 데이터셋이 항상 일치하도록 보장합니다. replication link가 실패하면 분기를 방지하기 위해 시스템은 정확히 문제에서 설명한 대로 쓰기를 중지/보류해야 합니다. 이는 거의 0에 가까운 RPO를 제공하지만 latency를 증가시키고 link 장애 중 availability를 낮춥니다.
High Availability를 사용하는 synchronous replication은 원격 통신이 실패할 때 모든 로컬 쓰기를 중지해야 한다는 요구 사항과 충돌합니다. “High Availability”는 일반적으로 장애에도 불구하고 작업을 계속 수행하는 것을 의미하며(종종 로컬 쓰기를 계속 진행하거나 failover 수행), 이는 분기 위험을 초래하거나 복잡한 quorum/failover 동작을 요구할 수 있습니다. 이 문제는 availability보다 consistency를 명시적으로 우선합니다.
Active Replay의 asynchronous replication은 replication이 write acknowledgment와 분리되어 있으므로 양쪽의 데이터가 항상 일치한다고 보장할 수 없습니다. 변경 사항이 빠르게 전송되더라도 항상 잠재적인 지연(0이 아닌 RPO)이 존재합니다. link가 실패하면 일반적으로 로컬 쓰기는 계속되며, 이는 통신 실패 시 쓰기를 중지해야 한다는 요구 사항을 직접적으로 위반합니다.
빈번한 replay를 사용하는 asynchronous replication은 지연을 줄일 수는 있지만, 양쪽이 매 순간 항상 일치해야 한다는 엄격한 보장을 여전히 제공하지 못합니다. 빈번한 replay는 RPO를 개선할 수 있지만 여전히 0이 아니며 replay 간격과 네트워크 상태에 따라 달라집니다. 또한 asynchronous 설계는 일반적으로 link 장애 중에도 로컬 쓰기를 허용하므로 요구 사항과 모순됩니다.
문제 분석
핵심 개념: 이 문제는 스토리지 시스템의 replication mode와 consistency 보장에 대한 이해를 평가합니다. 핵심 설계 선택은 synchronous와 asynchronous replication의 차이, 그리고 원격 사이트를 사용할 수 없을 때 로컬 쓰기에 어떤 일이 발생하는지입니다. 이는 고전적인 RPO/RTO 사고방식 및 Azure Well-Architected Framework의 reliability pillar와 연결되며, 비즈니스 요구 사항을 충족하기 위한 올바른 데이터 replication 전략을 선택하는 것입니다. 정답인 이유: 요구 사항은 다음과 같습니다: (1) 양쪽의 데이터가 항상 일치해야 함, (2) 데이터가 기록되는 즉시 원격 시스템으로 전송되어야 함, (3) 통신이 실패하면 로컬 시스템에 대한 모든 쓰기가 중지되어야 함. 이는 엄격한/강한 consistency를 갖는 synchronous replication의 정의적 특성입니다. synchronous replication에서는 쓰기가 로컬에 커밋되고 원격 사이트에서도 확인되기 전까지 애플리케이션에 acknowledgment되지 않습니다. replication link가 실패하면 시스템은 동일한 복사본을 안전하게 보장할 수 없으므로 consistency를 유지하기 위해 쓰기를 중단하거나 실패 처리해야 합니다(“write-stall” 또는 “I/O freeze”). “High Consistency”는 이러한 동작과 일치합니다. 주요 특징 / 모범 사례: synchronous replication은 acknowledgment된 모든 쓰기가 두 위치 모두에 존재하므로 거의 0에 가까운 RPO(데이터 손실 없음)를 제공합니다. 그 대가로 더 높은 write latency(원격 사이트까지의 round-trip)와 네트워크 신뢰성 및 거리(일반적으로 metro/low-latency 범위 내에서 가장 적합)에 대한 의존성이 있습니다. 아키텍처 관점에서 이는 네트워크 partition 동안 availability보다 consistency를 우선하는 CP 스타일의 선택입니다. 시스템은 분기되는 것보다 쓰기를 중지하는 것을 선호합니다. 이는 Well-Architected 지침과도 일치합니다: consistency 요구 사항을 명확히 선택하고 availability/latency 영향도를 이해해야 합니다. 일반적인 오해: “High Availability”는 목표처럼 들릴 수 있지만, 요구 사항은 원격 link가 실패하면 쓰기가 중지되어야 한다고 명시하고 있습니다. 이는 availability를 극대화하는 것과는 반대입니다. asynchronous 옵션은 데이터를 빠르게 전송하고 자주 replay할 수 있지만, 본질적으로 원격 복사본이 항상 primary와 일치하지 않을 수 있는 지연 구간을 허용합니다. 시험 팁: “항상 일치해야 함”, “기록되는 즉시”, “link 실패 시 쓰기 중지”와 같은 표현을 찾으십시오. 이는 강한 consistency(0 또는 거의 0에 가까운 RPO)를 갖는 synchronous replication과 장애 중 availability를 희생할 의지가 있음을 나타냅니다. 반대로 문제가 “원격이 다운되어도 로컬이 계속 실행되어야 함”을 강조한다면, 이는 asynchronous replication을 의미합니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
6
문제 6
(2개 선택)볼륨에서 공간을 pre-allocate하면 어떤 두 가지 효과가 있습니까? (두 개 선택)
정답입니다. 공간을 pre-allocate하면 쓰기 중 on-demand extent allocation 및 관련 metadata 작업을 피할 수 있으므로 특정 애플리케이션의 성능 일관성을 향상시킬 수 있습니다. 이는 latency spike와 fragmentation 위험을 줄일 수 있으며, 특히 write-heavy, latency-sensitive workload(예: database 또는 high-ingest logging)에 유리합니다. 모든 workload에 대해 보장되는 것은 아니지만, pre-allocation의 알려진 효과입니다.
정답입니다. Thin provisioning은 데이터가 기록될 때 physical storage를 할당합니다. 공간을 pre-allocate하면 capacity를 미리 예약/확정하므로, 해당 볼륨은 사실상 더 이상 thin provisioned가 아니게 됩니다(보통 thick provisioned로 간주됨). 이는 storage pool 수준에서 overcommitment 위험을 줄이지만 capacity를 즉시 소비합니다.
오답입니다. RAID level은 기본 storage configuration(disk group/aggregate/pool)에 의해 결정되며, 일반적으로 공간 pre-allocation과 같은 볼륨 수준 작업으로 변경되지 않습니다. Pre-allocation은 볼륨에 대해 capacity가 예약되는 방식에 영향을 줄 뿐이며, 디스크의 redundancy/performance layout(RAID 0/1/5/6/10)에는 영향을 주지 않습니다.
오답입니다. Data progression(성능 tier와 capacity tier 간 데이터 이동)은 일반적으로 볼륨이 thin인지 thick인지가 아니라 storage policy와 access pattern에 의해 제어됩니다. 일부 platform에서는 특정 상호작용이 있을 수 있지만, 공간 pre-allocation만으로 볼륨의 data progression이 본질적으로 비활성화되지는 않습니다.
문제 분석
핵심 개념: 이 문제는 storage provisioning 동작, 특히 볼륨에서 공간을 pre-allocate할 때 어떤 일이 발생하는지를 테스트합니다. 많은 enterprise storage 시스템에서 볼륨은 thin provisioned(physical capacity는 데이터가 기록될 때만 소비됨) 또는 thick/eager provisioned(capacity가 미리 예약됨)일 수 있습니다. “pre-allocating space”는 일반적으로 필요 시점에 할당하는 대신 backing storage capacity를 즉시 예약/할당하는 것을 의미합니다. 정답이 맞는 이유: A가 정답인 이유는 pre-allocation이 특정 workload에 대해 성능 예측 가능성을 향상시킬 수 있기 때문입니다. Thin provisioning은 쓰기 중에 allocation overhead(metadata 업데이트, extent allocation, 잠재적 fragmentation, 그리고 platform에 따라 background zeroing)를 유발할 수 있습니다. 공간을 미리 할당하면 storage 시스템은 peak I/O 동안 allocation 작업을 줄이거나 제거할 수 있으며, 이는 latency를 낮추고 성능 변동성을 줄일 수 있습니다. 특히 write-heavy 또는 latency-sensitive 애플리케이션에서 그렇습니다. B가 정답인 이유는 공간을 pre-allocate하면 해당 볼륨의 thin-provisioned 동작이 사실상 제거되기 때문입니다(또는 platform 용어에 따라 thick provisioning으로 변환됩니다). 공간이 pre-allocate되면 볼륨은 더 이상 “allocate-on-write” semantics에 의존하지 않으며, physical capacity가 예약/확정됩니다. 주요 기능 및 모범 사례: Pre-allocation은 일반적으로 database, high-ingest logging 및 일관된 write 성능이 중요한 기타 workload에 사용됩니다. 또한 storage pool 수준에서 thin-provisioning overcommitment로 인해 out-of-space 상태가 발생할 위험을 줄여줍니다. 운영 관점에서(Well-Architected reliability 및 performance efficiency 원칙에 부합), pre-allocation은 더 높은 초기 capacity 소비를 대가로 더 예측 가능한 성능과 감소된 capacity 위험을 제공합니다. 일반적인 오해: 학습자들은 종종 pre-allocation이 RAID level을 변경하거나 tiering/data progression을 비활성화한다고 가정합니다. 그러나 이것들은 별개의 storage 기능입니다. RAID는 기본 disk group/aggregate의 속성이며, 일반적으로 볼륨 수준의 pre-allocation 설정으로 변경되지 않습니다. 마찬가지로 data progression/tiering은 보통 정책과 access pattern에 의해 제어되며, 볼륨이 thin인지 thick인지에 의해 결정되지 않습니다. 시험 팁: “pre-allocate”를 보면 “thick/eager allocation”, “더 적은 allocation overhead”, “더 예측 가능한 성능”을 떠올리되, 동시에 “즉시 capacity를 사용함”도 생각해야 합니다. 문제가 이를 명시적으로 연결하지 않는 한 provisioning type을 RAID configuration 또는 tiering 기능과 혼동하지 마세요.
7
문제 7
기존에 Azure Active Directory (Azure AD) 사용자를 차단하는 데 사용되는 Azure logic app이 있습니다. 이 logic app은 수동으로 트리거됩니다. Azure Sentinel을 배포합니다. 기존 logic app을 Azure Sentinel에서 playbook으로 사용해야 합니다. 가장 먼저 무엇을 해야 합니까?
Scheduled query rule(analytics rule)은 log query에서 alert/incident를 생성합니다. Analytics rule을 automation rule과 함께 사용하여 playbook을 실행할 수는 있지만, 이것은 핵심 문제를 해결하지 못합니다. Logic App은 수동으로 트리거되며 아직 Sentinel playbook trigger와 호환되지 않습니다. 일반적으로 playbook을 사용할 수 있게 만든 후 detection을 생성/조정하며, 이를 변환의 첫 단계로 하지는 않습니다.
Data connector는 data source를 Microsoft Sentinel로 수집하는 데 사용됩니다(예: Entra ID, Microsoft 365 Defender 또는 Azure Activity). Data 수집은 detection 및 investigation에 중요하지만, Logic App이 트리거되는 방식을 변경하지는 않습니다. Connector를 추가해도 수동으로 트리거되는 Logic App을 Sentinel playbook으로 호출 가능하게 만들 수는 없습니다.
Threat Intelligence connector는 Sentinel에서 correlation 및 detection을 위해 TI indicator(STIX/TAXII, platforms 등)를 수집하는 데 사용됩니다. 이는 incident response automation과 관련이 없으며, 기존 Logic App을 playbook으로 사용할 수 있는지 여부에도 영향을 주지 않습니다. 이 선택지는 threat intel 수집과 SOAR 실행 요구 사항을 혼동한 것입니다.
Logic App을 Sentinel playbook으로 사용하려면, Sentinel이 이를 호출하고 incident context를 전달할 수 있도록 Sentinel이 지원하는 trigger(일반적으로 Microsoft Sentinel incident trigger)가 있어야 합니다. 기존 Logic App은 수동으로 트리거되므로, 가장 먼저 필요한 작업은 trigger를 그에 맞게 수정하는 것입니다. 그 후 automation rule을 통해 연결하거나 incident에서 실행할 수 있습니다.
문제 분석
핵심 개념: Microsoft Sentinel playbook은 Sentinel에 의해 호출되는 Azure Logic Apps입니다(일반적으로 automation rule, incident 또는 alert에서 호출됨). Sentinel이 Logic App을 playbook으로 호출하려면, Logic App은 순수한 수동 trigger가 아니라 Sentinel이 지원하는 trigger(예: Microsoft Sentinel incident trigger)를 사용해야 합니다. 정답이 맞는 이유: 기존 Logic App은 수동으로 트리거됩니다. 수동으로 트리거되는 Logic App은 Sentinel이 playbook으로 자동 실행할 수 없습니다. Sentinel은 예상되는 방식으로 호출할 수 있는 trigger endpoint(incident/alert entity context 또는 지원되는 request trigger pattern)가 필요하기 때문입니다. 따라서 첫 번째 단계는 Logic App trigger를 Sentinel playbook trigger(일반적으로 “When a response to a Microsoft Sentinel incident is triggered” / incident trigger)로 수정하는 것입니다. 그 후 automation rule을 통해 incident에 연결하거나 incident에서 수동으로 실행할 수 있습니다. 주요 기능 및 모범 사례: - Playbook은 Sentinel에서 incident response automation (SOAR)에 사용되며 일반적으로 Automation rules에서 실행됩니다. - Logic App은 동일한 tenant에 있어야 하며 Entra ID (Azure AD) 사용자를 차단하는 작업을 수행하기 위한 적절한 권한(managed identity 또는 connections)을 가져야 합니다. - Azure Well-Architected Framework (Security 및 Reliability)를 따르세요: Graph/Entra 작업에는 least privilege를 적용하고, audit logging을 활성화하며, idempotent design을 사용하세요(확인 없이 동일한 사용자를 반복적으로 차단하지 않도록 방지). 일반적인 오해: - Analytics rule(scheduled query rule) 생성은 detection을 위한 것이며, 기존 Logic App을 playbook으로 사용할 수 있게 만드는 작업이 아닙니다. - Data connector는 데이터를 수집하는 역할을 하며, 수동 Logic App을 Sentinel playbook으로 변환하지 않습니다. - Threat Intelligence connector는 response automation 실행과 관련이 없습니다. 시험 팁: 질문이 “기존 Logic App을 Sentinel playbook으로 사용하는 방법”을 묻는다면, 먼저 trigger 유형을 확인하세요. Sentinel playbook은 Sentinel이 incident/alert context를 전달하고 workflow를 호출할 수 있도록 Sentinel 호환 trigger가 필요합니다. Detection 구성(analytics rules)과 수집(data connectors)은 SOAR 활성화와는 별개의 단계입니다.
8
문제 8
Azure Defender를 사용하는 Microsoft 365 구독이 있습니다. RG1이라는 리소스 그룹에 100개의 가상 머신이 있습니다. SecAdmin1이라는 새 사용자에게 Security Admin 역할을 할당합니다. Azure Defender를 사용하여 SecAdmin1이 가상 머신에 quick fixes를 적용할 수 있도록 해야 합니다. 솔루션은 최소 권한 원칙을 사용해야 합니다. SecAdmin1에게 어떤 역할을 할당해야 합니까?
구독 범위의 Security Reader는 보안 정보에 대한 읽기 전용 역할입니다. SecAdmin1은 Defender for Cloud 권장 사항, alerts 및 secure score 데이터를 볼 수는 있지만, remediation 작업을 실행하거나 VM에 extensions/agents를 배포할 수는 없습니다. 이러한 작업에는 기본 리소스에 대한 쓰기 권한이 필요하므로 “quick fixes 적용” 요구 사항을 충족하지 못합니다.
구독 범위의 Contributor는 SecAdmin1이 VM을 remediation할 수 있게 해주지만, 전체 구독(모든 리소스 그룹 및 리소스)에 걸쳐 광범위한 쓰기 액세스를 부여합니다. 요구 사항은 RG1의 100개 VM에만 해당하므로 이는 최소 권한 원칙을 위반합니다. 흔한 함정은 기능은 맞지만 범위가 잘못되었다는 점입니다.
RG1의 Contributor는 해당 리소스 그룹의 VM을 수정하는 데 필요한 쓰기 권한(agents/extensions 설치 및 구성 변경 포함)을 제공합니다. 이는 일반적으로 Defender for Cloud quick fixes에 필요합니다. 또한 RG1에만 액세스를 제한하므로 최소 권한 및 올바른 거버넌스 관행에 부합합니다.
RG1의 Owner도 quick fixes를 적용할 수 있게 해주지만, Microsoft.Authorization/* 권한(다른 사용자에게 액세스 권한을 부여하는 기능)을 포함하므로 필요 이상으로 높은 권한입니다. 시나리오에서 SecAdmin1이 RBAC 할당을 관리해야 한다는 요구가 없다면, Owner는 과도하며 Contributor와 비교할 때 최소 권한 원칙에 맞지 않습니다.
문제 분석
핵심 개념: 이 문제는 Azure role-based access control (RBAC)과 Microsoft Defender for Cloud(이전의 Azure Defender) remediation 기능을 테스트합니다. Defender for Cloud의 “Quick fixes”(예: endpoint protection 활성화, agents/extensions 설치, 권장 구성 적용)는 일반적으로 대상 리소스(VM 및 경우에 따라 extensions, network settings 또는 policy assignments와 같은 관련 리소스)에 대한 쓰기 권한이 필요합니다. 최소 권한 원칙은 필요한 최소 범위와 권한만 부여하는 것을 의미합니다. 정답인 이유: RG1 범위에서 Contributor 역할을 할당하면(옵션 C) SecAdmin1은 RG1의 가상 머신에 변경을 수행할 수 있으며, 여기에는 VM extensions/agents 배포와 Defender for Cloud quick fixes가 자주 수행하는 구성 변경 적용이 포함됩니다. 또한 전체 구독이 아니라 100개의 VM이 포함된 리소스 그룹으로만 권한을 제한합니다. 사용자는 이미 Security Admin을 가지고 있지만, 이 역할은 보안 정책 및 설정 관리에 초점이 있으며 remediation에 필요한 compute 리소스에 대한 전체 쓰기 권한을 본질적으로 부여하지는 않습니다. 주요 기능 / 모범 사례: - Defender for Cloud 권장 사항 및 remediation 작업에는 자주 Microsoft.Compute/* 쓰기 작업(VM/extension 변경)이 필요하며, 수정 내용에 따라 때로는 Microsoft.Network/* 변경도 필요합니다. - Azure Well-Architected Framework의 거버넌스 및 보안 원칙(최소 권한, 직무 분리)에 맞추기 위해 범위가 지정된 RBAC 할당(리소스 그룹 또는 특정 리소스)을 사용합니다. - 실제 환경에서는 Contributor보다 더 세분화된 custom roles를 사용할 수도 있지만, 주어진 옵션 중에서는 RG 범위의 Contributor가 remediation을 가능하게 하면서도 최소 권한을 충족하는 역할입니다. 일반적인 오해: - “Security Admin”은 문제를 수정하기에 충분해 보일 수 있지만, 주로 보안 구성/관리를 다루며 반드시 VM 수정 권한을 포함하지는 않습니다. - “Security Reader”는 권장 사항을 볼 수는 있지만 수정 사항을 적용할 수는 없습니다. - “Owner”는 역할 할당 권한을 포함하므로 과도합니다. 시험 팁: 문제에서 Azure 리소스에 수정/fixes/remediation 적용을 언급하면, 해당 리소스에 대한 쓰기 권한이 필요하다고 가정하십시오. 대상 리소스를 포함하는 가장 작은 범위(RG1 대 구독)를 선택하고, 역할 위임이 명시적으로 필요한 경우가 아니라면 Owner는 피하십시오. 학습 참고 자료: - Defender for Cloud remediation 및 권장 사항 - Azure RBAC 기본 제공 역할(Security Admin, Security Reader, Contributor, Owner) 및 범위 상속
9
문제 9
(2개 선택)새 Azure subscription에서 Linux virtual machine을 프로비저닝합니다. Azure Defender를 사용하도록 설정하고 virtual machine을 Azure Defender에 온보딩합니다. virtual machine에 대한 공격이 Azure Defender에서 alert를 트리거하는지 확인해야 합니다. virtual machine에서 어떤 두 개의 Bash 명령을 실행해야 합니까? 각 정답은 솔루션의 일부를 나타냅니다. 참고: 각 정답 선택에는 1점이 부여됩니다.
정답입니다. 이는 무해한 binary(/bin/echo)를 새 executable 이름(asc_alerttest_662jfi039n)으로 복사합니다. 이 테스트는 process 이름이 Defender/MDE alert simulation에 사용되는 알려진 패턴과 일치하는 것에 의존합니다. 올바른 이름의 executable을 만드는 것은 실제 malware를 도입하지 않고 예상되는 테스트 alert를 생성하는 첫 번째 단계입니다.
오답입니다. “eicar” 키워드를 포함하고 있기는 하지만, “alerttest”라는 프로그램을 실행하려고 시도하는데, 이 옵션 집합에서 다른 올바른 단계 없이는 해당 프로그램이 생성되지 않습니다(옵션 C도 실행해야 함). 생성되더라도 process 이름이 이 Defender simulation 시나리오에서 기대하는 특정 테스트 harness 이름과 일치하지 않을 수 있습니다.
오답입니다. 이는 예상되는 “asc_alerttest_662jfi039n”이 아니라 “alerttest”라는 이름의 executable을 생성합니다. /bin/echo의 이름을 바꾸는 것은 실행 가능한 파일을 만드는 안전한 방법이지만, 이 문제의 alert simulation은 다른 옵션에 표시된 특정 파일명과 연결되어 있으므로 이 단계만으로는(또는 B와 짝지어도) 의도한 Defender alert를 트리거하지 못할 수 있습니다.
정답입니다. 이는 이름이 변경된 테스트 binary를 실행하고 “eicar”가 포함된 인수를 전달합니다. 이는 안전한 테스트 detection/alert를 트리거하는 데 일반적으로 사용됩니다. VM이 올바르게 온보딩되어 있고 telemetry가 흐르고 있다면, 이는 Defender for Cloud(통합된 endpoint alerts를 통해)에서 관찰할 수 있는 alert를 생성하여 detection이 작동하는지 확인할 수 있게 합니다.
문제 분석
핵심 개념: 이 문제는 안전한 모의 malware/attack 신호를 생성하여 Linux VM에서 Microsoft Defender for Cloud(이전의 Azure Defender) alerting을 검증하는 방법을 테스트합니다. Defender for Cloud는 지원되는 머신에서 Defender for Endpoint(MDE) sensor와 통합됩니다. 온보딩되면 MDE는 알려진 “EICAR” 테스트 문자열을 사용하여 테스트 alert를 생성할 수 있습니다. 이는 sensor -> cloud service -> Defender portal의 alert로 이어지는 end-to-end pipeline을 확인하는 표준 방법입니다. 정답인 이유: Linux에서 일반적인 테스트 방법은 Defender/MDE 테스트 도구에서 사용하는 특정 패턴의 이름을 가진 binary를 실행하고 EICAR 키워드가 포함된 인수를 전달하는 것입니다. 옵션의 두 단계 프로세스는 다음과 같습니다. 1) 정상 binary(/bin/echo)를 예상되는 테스트 executable 이름(asc_alerttest_662jfi039n)을 가진 새 파일명으로 복사합니다. 이는 다음 명령으로 수행됩니다: cp /bin/echo ./asc_alerttest_662jfi039n (옵션 A). 2) 이름이 변경된 executable을 “eicar”가 포함된 매개변수와 함께 실행하여 테스트 detection을 트리거합니다: ./asc_alerttest_662jfi039n testing eicar pipe (옵션 D). 이렇게 하면 Defender for Cloud/MDE에서 alert를 생성해야 하는 무해한 이벤트가 만들어지며, 이를 통해 alert 수집 및 가시성을 확인할 수 있습니다. 주요 기능 / 모범 사례: - VM이 Defender for Endpoint(또는 Defender for Cloud의 endpoint 통합)에 올바르게 온보딩되어 있고 필요한 endpoint에 대한 네트워크 액세스가 있는지 확인합니다. - alert가 표시되기까지 몇 분이 걸릴 수 있으므로 Microsoft Defender portal 및/또는 Defender for Cloud security alerts에서 확인합니다. - 위험을 피하기 위해 실제 malware 대신 EICAR와 같은 테스트 방법을 사용합니다. 일반적인 오해: 흔한 실수는 잘못된 파일명을 사용하는 것입니다. 일부 detection은 테스트 harness에서 사용하는 특정 process 이름/경로에 의존합니다. 옵션 B와 C는 예상되는 “asc_alerttest_662jfi039n” 대신 “alerttest”를 사용하므로 의도한 테스트 alert를 트리거하지 못할 수 있습니다. 시험 팁: SC-200에서는 “verification” 문제에 안전한 simulation artifact(EICAR)가 자주 사용되며, 테스트 조건 생성과 실행이 모두 필요하다는 점을 기억하세요. 또한 Defender for Cloud와 Defender for Endpoint를 구분하세요. Defender for Cloud는 endpoint alert를 표시할 수 있지만, 기본 신호는 종종 머신의 MDE에서 발생합니다.
10
문제 10
DRAG DROP -
새 Azure 구독을 만들고 Azure Monitor 로그 수집을 시작했습니다.
Azure 가상 머신에서 의심스러운 로그인과 관련된 위협 탐지가 정상적으로 동작하는지 Microsoft Defender for Cloud에서 검증해야 합니다.
올바른 순서를 고르세요.
파트 1:
올바른 순서를 고르세요.
정답은 A입니다. 서버 위협 경고를 생성하려면 먼저 구독에서 Defender for Servers가 활성화되어 있어야 합니다. 이후 가상 머신에 ASC_AlertTest_662jfi039N.exe 테스트 파일을 복사해 이름을 맞추고 실행하면 검증용 경고가 발생합니다. 다른 선택지는 플랜을 활성화하기 전에 테스트하거나, Sentinel/억제 규칙처럼 Defender for Servers 탐지 검증과 직접 관련 없는 기능을 사용합니다.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
11
문제 11
귀사는 Azure Security Center 및 Azure Defender를 사용합니다.
회사 내 security operations team은 security alerts에 대한 email notifications를 받지 못한다고 알려왔습니다. email notifications를 활성화하려면 Security Center에서 무엇을 구성해야 합니까?
Security solutions는 통합된 security products 및 protections를 검색, 연결 또는 관리하는 데 사용되며, 누가 email notifications를 받는지 정의하는 곳이 아닙니다. 이는 administrative contact settings보다는 security tooling 및 integrations에 중점을 둡니다. 어떤 solution이 findings를 생성하더라도, 이 섹션은 Security Center의 기본 제공 alert email recipients를 제어하지 않습니다. 따라서 security operations team에 대한 email notifications를 활성화하는 데 사용할 수 없습니다.
Security policy가 정답인 이유는 Azure Security Center가 policy settings와 연결된 security contact configuration 아래에 alert email notification 동작을 저장하기 때문입니다. 이곳에서 administrators는 email recipients를 지정하고 security alerts에 대해 notifications를 보낼지 구성합니다. 이 기능은 alert investigation interface가 아니라 subscription 또는 management scope의 security configuration에 연결되어 있습니다. 시험에서는 Security Center에서 alert emails를 활성화하는 문제는 일반적으로 Security policy 또는 security contacts에 해당합니다.
Pricing & settings는 주로 Defender plans를 활성화하고, coverage를 선택하며, subscription-level onboarding 또는 pricing 관련 구성을 관리하는 데 사용됩니다. 어떤 protections가 활성화되는지에는 영향을 주지만, alerts에 대한 security contact email notifications를 정의하는 위치는 아닙니다. plan configuration을 notification configuration과 혼동하는 것은 흔한 실수입니다. 여기서 services를 활성화하는 것만으로는 operations team에 alert emails가 전송되지 않습니다.
Security alerts는 이미 생성된 alerts를 보고, triage하고, 조사하는 workspace입니다. 이는 notification recipients를 구성하는 settings page가 아닙니다. 사용자는 그곳에서 incidents 및 remediation guidance를 분석할 수 있지만, 해당 blade에서 alert emails를 활성화할 수는 없습니다. 따라서 질문에서 설명한 문제를 해결하지 못합니다.
Azure Defender는 Security Center/Defender for Cloud 내의 advanced threat protection capabilities를 의미합니다. 이를 켜면 detection 및 alert generation은 증가하지만, 누가 email notifications를 받아야 하는지는 지정하지 않습니다. notification recipients 및 alert email behavior는 policy/security contact settings에서 별도로 구성됩니다. 따라서 Azure Defender 자체는 email notifications를 활성화하는 올바른 위치가 아닙니다.
문제 분석
핵심 개념: Azure Security Center(현재 Microsoft Defender for Cloud)에서 security alerts에 대한 email notifications는 Security policy 내의 security contact settings의 일부로 구성됩니다. 이러한 설정은 누가 alert emails를 받고 어떤 severity levels에 대해 받는지를 결정합니다. 정답인 이유: Security policy 영역에는 administrators 및 기타 recipients에게 security alerts를 알리는 데 사용되는 email notifications 및 security contacts 구성이 포함되어 있습니다. 주요 기능: security contacts를 정의하고, email notifications를 활성화하며, portal/version에 따라 high-severity alerts 또는 모든 alert severities에 대해 notifications를 보낼지 선택할 수 있습니다. 흔한 오해: 많은 응시자가 Pricing & settings를 notification configuration과 혼동하는데, 이는 plan enablement 및 scope settings를 제어하지만 alert email recipients를 직접 관리하지는 않기 때문입니다. 시험 팁: Security Center에서 alert emails 또는 security contacts를 어디서 구성하는지 묻는 문제라면, alert viewing pages나 Defender plan enablement보다 Security policy/security contacts를 떠올리십시오.
12
문제 12
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 일부입니다. 시리즈의 각 문제에는 제시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 문제 세트에는 둘 이상의 올바른 솔루션이 있을 수 있지만, 다른 문제 세트에는 올바른 솔루션이 없을 수도 있습니다. 이 섹션의 문제에 답한 후에는 해당 문제로 돌아갈 수 없습니다. 따라서 이러한 문제는 검토 화면에 표시되지 않습니다. 사용자는 Azure Security Center를 사용합니다. Security Center에서 보안 경고를 받습니다. Security Center에서 경고를 해결하기 위한 권장 사항을 확인해야 합니다. 솔루션: Security alerts에서 경고를 선택하고, Take Action을 선택한 다음, Mitigate the threat 섹션을 확장합니다. 이것이 목표를 충족합니까?
이 옵션이 정답인 이유는 Azure Security Center에서 보안 경고를 열고 Take Action 영역을 사용하여 권장 수정 단계를 검토할 수 있기 때문입니다. Mitigate the threat 섹션은 감지된 위협에 대응하고 그 영향을 줄이는 방법에 대한 지침을 제공하도록 특별히 설계되었습니다. 목표가 경고를 해결하기 위한 권장 사항을 확인하는 것이므로, 이 탐색 경로는 요구 사항을 직접 충족합니다. 이는 일반적인 보안 상태 보기가 아니라 경고 중심 워크플로이므로 올바른 선택입니다.
이 옵션은 설명된 솔루션이 실제로 목표를 충족하므로 오답입니다. Azure Security Center에서 보안 경고를 선택한 다음 Take Action 및 Mitigate the threat 섹션을 검토하는 것은 수정 지침을 확인하는 유효한 방법입니다. "아니요"라고 답하는 것은 이 경로가 권장 사항을 제공하지 않는다는 의미가 되지만, 이는 사실이 아닙니다. 이 플랫폼은 정확히 이 위치에서 경고별 완화 단계를 표시하도록 설계되어 있습니다.
문제 분석
핵심 개념: 이 문제는 Azure Security Center(현재는 Microsoft Defender for Cloud의 일부)가 보안 경고에 대한 수정 지침을 어떻게 제공하는지에 대한 지식을 평가합니다. 구체적으로, 감지된 위협을 조사하고 완화할 수 있도록 경고와 관련된 권장 작업을 어디에서 찾는지 알고 있는지를 확인합니다. 정답인 이유: Azure Security Center에서 보안 경고를 열면 Take Action 영역에서 해당 경고에 대한 대응 지침을 제공합니다. Mitigate the threat 섹션을 확장하면 Security Center가 식별한 문제를 해결하는 데 도움이 되는 권장 사항과 수정 단계가 표시됩니다. 이는 경고별 권장 사항을 확인하는 올바른 워크플로이므로, 제안된 솔루션은 제시된 목표를 충족합니다. 주요 기능 / 구성: - Security alerts는 인시던트 세부 정보, 영향을 받는 리소스, 심각도 및 탐지 컨텍스트를 제공합니다. - Take Action 창은 대응자가 조사 및 수정 과정을 진행할 수 있도록 안내하도록 설계되었습니다. - Mitigate the threat 섹션에는 위험을 줄이고 감지된 문제를 수정하기 위한 권장 단계가 포함되어 있습니다. - Azure Security Center / Microsoft Defender for Cloud는 보안 상태 권장 사항과 경고별 대응 지침을 모두 제공합니다. 일반적인 오해: - 응시자는 일반적인 Secure Score 또는 보안 권장 사항과 경고별 완화 지침을 자주 혼동합니다. - 일부는 권장 사항이 Recommendations 블레이드에서만 제공된다고 생각하지만, 경고 수정 지침은 경고에서 직접 액세스할 수도 있습니다. - 또 다른 일부는 Security Center가 경고만 보고하고 대응 작업은 제공하지 않는다고 생각하지만, 이는 사실이 아닙니다. 시험 팁: - 경고 수정 단계를 찾을 때는 일반 권장 사항 페이지가 아니라 특정 보안 경고에서 시작하세요. - Take Action 또는 Mitigate the threat와 같은 작업 중심 섹션을 찾으세요. - 보안 상태 개선 권장 사항과 인시던트/경고 대응 지침을 구분하세요. - Azure 시험 문제에서 "경고를 해결"과 같은 표현은 일반적으로 경고별 완화 지침을 의미합니다.
13
문제 13
DRAG DROP - 외부 솔루션이 Azure Sentinel에 Common Event Format (CEF) 메시지를 전송하도록 연결할 계획입니다. 로그 전달자를 배포해야 합니다. 세 가지 작업을 어떤 순서로 수행해야 합니까? 답하려면 작업 목록에서 적절한 작업을 답 영역으로 이동하고 올바른 순서로 정렬하세요. 선택하고 배치하세요:
파트 1:
아래 이미지에서 올바른 답을 선택하세요.
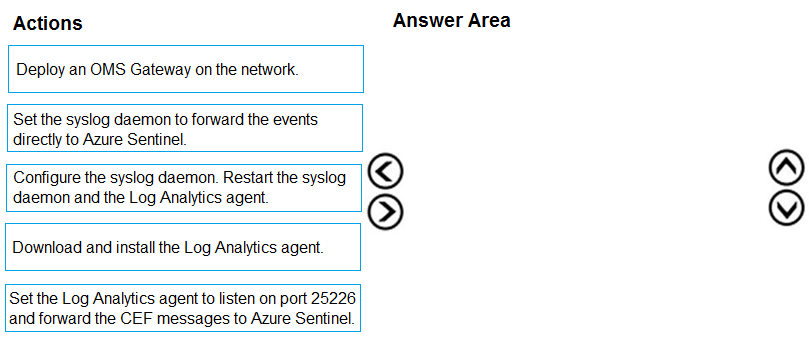
Sentinel CEF connector/log forwarder 배포에 대한 올바른 순서가 명확하게 정의되어 있으므로 정답이 적절합니다. 올바른 3단계 순서: 1) Log Analytics agent를 다운로드하고 설치합니다. 2) Log Analytics agent가 포트 25226에서 수신 대기하도록 설정하고 CEF 메시지를 Azure Sentinel (Log Analytics workspace)로 전달하도록 설정합니다. 3) syslog daemon을 구성합니다. syslog daemon과 Log Analytics agent를 다시 시작합니다. 이유: agent가 데이터를 수신/전달하려면 먼저 설치해야 합니다. 그다음 agent의 CEF/syslog 수집을 구성합니다(포트 25226은 CEF forwarder 설정에서 일반적으로 사용되는 TCP listener입니다). 마지막으로 rsyslog/syslog-ng가 들어오는 CEF 메시지를 적절히 전달/라우팅하도록 구성하고, 구성 변경 사항이 적용되도록 서비스를 다시 시작합니다. 다른 선택지가 틀린 이유: “syslog daemon이 이벤트를 Azure Sentinel로 직접 전달하도록 설정”은 잘못되었습니다. Sentinel은 직접적인 syslog endpoint가 아니라 Log Analytics를 통해 수집하기 때문입니다. “OMS Gateway 배포”는 선택 사항(proxy 시나리오)이며 표준 forwarder 배포에는 필요하지 않습니다.
14
문제 14
귀사는 10,000개가 넘는 IoT 디바이스의 경고를 관리하기 위해 Azure Sentinel을 사용합니다. 회사 보안 관리자는 많은 수의 incident로 인해 보안 위협을 추적하는 것이 점점 더 어려워지고 있다고 보고합니다. 위협 조사를 단순화하기 위한 custom visualization을 제공하고 machine learning을 사용하여 위협을 추론할 수 있는 솔루션을 권장해야 합니다. 권장 사항에 무엇을 포함해야 합니까?
Microsoft Sentinel의 built-in queries는 분석가가 일반적인 시나리오를 빠르게 hunting하거나 조사할 수 있도록 도와주는 미리 작성된 KQL query입니다. 속도와 일관성을 향상시키지만, 주로 query template이며 advanced custom visualization이나 machine learning environment를 본질적으로 제공하지는 않습니다. triage와 hunting에는 유용하지만, ML을 사용해 위협을 추론해야 한다는 요구 사항은 충족하지 못합니다.
Microsoft Sentinel의 Livestream은 이벤트가 도착하는 즉시 near-real-time으로 모니터링하는 데 사용되며, 분석가가 활동을 관찰하고 진행 중인 조사 중 빠르게 pivot할 수 있도록 도와줍니다. 모니터링을 단순화할 수는 있지만, 표준 query 결과를 넘어서는 custom visualization을 구축하도록 설계된 것은 아니며, 위협 추론을 위한 machine learning model을 실행할 수 있는 notebook 스타일 environment도 제공하지 않습니다.
Notebooks(Microsoft Sentinel과 통합된 Jupyter notebooks)는 Python 및 data science library를 사용한 advanced hunting과 조사를 위해 설계되었습니다. custom visualization, enrichment, 대규모 dataset 전반의 correlation, 그리고 machine learning 기법(예: anomaly detection, clustering) 적용을 통해 위협을 추론할 수 있습니다. 이는 custom visualization과 IoT 규모에서의 ML 기반 추론이라는 두 요구 사항을 모두 직접 충족합니다.
Microsoft Sentinel의 Bookmarks는 분석가가 흥미로운 이벤트, query 결과 또는 조사 artifact를 저장하고 태그 지정하여 증거를 보존하고 협업할 수 있게 해줍니다. 조사 관리와 결과 문서화에는 도움이 되지만, custom visualization 기능이나 machine learning 기반 analytics는 제공하지 않습니다. Bookmarks는 advanced analytics보다는 조사 workflow와 기록 보관에 관한 기능입니다.
문제 분석
핵심 개념: 이 문제는 기본 KQL query를 넘어서는 Microsoft Sentinel 조사 도구, 특히 대규모 환경에서 custom visualization과 machine learning 기반 위협 추론을 지원하는 기능을 테스트합니다. Sentinel에서는 이것이 Notebooks(Sentinel/Log Analytics와 통합된 Jupyter notebooks)로 제공되며, advanced analytics, enrichment, visualization을 지원합니다. 정답인 이유: 10,000개 이상의 IoT 디바이스에서 발생하는 경고를 처리하려면 분석가는 조사 복잡성을 줄이고 data science 기법을 적용할 수 있는 방법이 필요합니다. Microsoft Sentinel Notebooks는 Log Analytics에서 데이터를 가져오고, 외부 소스로 enrichment를 수행하며, ML model(예: clustering, anomaly detection, classification)을 실행하고, custom visualization(timeline, graph, entity relationship, geo map)을 생성할 수 있는 interactive environment(일반적으로 Python)를 제공합니다. 이는 “custom visualization 제공” 및 “machine learning을 사용한 위협 추론” 요구 사항과 직접적으로 일치합니다. 주요 기능 및 모범 사례: - Notebooks는 Azure Machine Learning/Jupyter 기반이며 API와 Log Analytics workspace를 통해 Sentinel 데이터와 통합됩니다. - 반복 가능한 조사 playbook을 가능하게 합니다. parameterized notebook은 많은 유사 incident에 대한 triage를 표준화할 수 있습니다. - advanced visualization(예: matplotlib/plotly) 및 graph analysis(예: 디바이스, IP, alert 간 network relationship)를 지원하며, 이는 IoT 규모의 correlation에 유용합니다. - Azure Well-Architected 관점에서 notebooks는 Operational Excellence(반복 가능한 분석), Reliability(일관된 workflow), Security(더 나은 탐지/조사 심층도)를 향상시킵니다. notebook 액세스와 data connector에는 RBAC와 least privilege를 사용해야 합니다. 일반적인 오해: built-in queries와 bookmarks는 조사 효율성에 도움이 되지만, 완전한 ML 지원 custom visualization environment를 제공하지는 않습니다. Livestream은 near-real-time monitoring 및 hunting에 초점을 맞추며, ML 기반 추론과 풍부한 custom visual에는 적합하지 않습니다. 시험 팁: Sentinel에서 “custom visualization”과 “machine learning”이 함께 나오면 Notebooks를 떠올리십시오. “증거/중요 결과 저장”이 나오면 Bookmarks를 떠올리십시오. “real-time view”가 나오면 Livestream을 떠올리십시오. “KQL 시작점”이 나오면 built-in queries를 떠올리십시오.
15
문제 15
Microsoft Defender for Office 365를 사용하여 해결할 수 있는 이슈는 어느 팀의 것입니까?
임원진은 phishing 및 BEC의 고가치 대상이므로 Defender for Office 365 보호(Safe Links, anti-phishing)의 혜택을 받습니다. 그러나 일반적으로 보안 policies를 관리하거나 조사/수정 조치를 수행하지는 않습니다. 보안/SOC 팀이 MDO를 사용하여 위협을 분석하고, 조사를 수행하며, mailbox에서 악성 메시지를 제거합니다.
Marketing 사용자는 외부 이메일, 첨부 파일, 링크를 자주 수신하므로 phishing 및 malware에 대한 노출이 증가합니다. Defender for Office 365는 이들을 보호하는 데 도움이 되지만, marketing은 MDO policies를 구성하거나 incidents를 해결하는 팀이 아닙니다. 보안 운영이 alert triage, Explorer에서의 위협 헌팅, quarantine 또는 메시지 제거와 같은 수정 조치를 관리합니다.
보안 팀은 Microsoft Defender for Office 365를 구성하고 운영할 책임이 있습니다. 이들은 anti-phishing, Safe Links, Safe Attachments policies를 생성하고 조정하며, Microsoft 365 Defender에서 alerts와 incidents를 모니터링하고, Threat Explorer를 사용하여 캠페인을 조사하며, 악성 콘텐츠를 격리하거나 제거하여 수정 조치를 수행합니다. 이는 SC-200에서 평가되는 핵심 SOC/보안 운영 책임입니다.
영업 팀은 credential phishing 및 invoice fraud의 빈번한 대상이므로 MDO 보호의 혜택을 받습니다. 그러나 영업은 보안 도구 운영을 담당하지 않습니다. 보안 팀이 Defender for Office 365를 사용하여 의심스러운 이메일을 조사하고, 영향을 받은 사용자를 식별하며, 수정 조치(quarantine, 삭제, URL/senders 차단)를 수행하여 이슈를 해결합니다.
문제 분석
핵심 개념: Microsoft Defender for Office 365 (MDO)는 Microsoft 365용 이메일 및 협업 보안 서비스로, Exchange Online, SharePoint Online, OneDrive, Microsoft Teams를 통해 전달되는 위협을 탐지, 방지, 조사 및 대응하는 데 도움을 줍니다. SC-200에서는 phishing, malware, business email compromise (BEC) 위험을 줄이기 위해 SOC 분석가가 사용하는 보안 운영 도구로 자주 출제됩니다. 정답인 이유: Microsoft Defender for Office 365를 사용하여 이슈를 해결하는 팀은 보안 팀입니다. MDO는 보안 중심 제어(Safe Links, Safe Attachments, anti-phishing policies), 위협 헌팅/조사(Threat Explorer/Real-time detections), 자동 대응(Automated Investigation and Response), 사고 상관관계 분석(Microsoft 365 Defender와의 통합)을 제공합니다. 이러한 기능은 marketing이나 sales 같은 비즈니스 기능이 아니라 보안 운영에서 소유하고 운영합니다. 주요 기능, 구성 및 모범 사례: 1) 보호: anti-phishing, anti-malware, anti-spam policies를 구성하고 Safe Links(클릭 시점 URL detonation/rewriting) 및 Safe Attachments(sandbox에서 detonation)를 활성화합니다. 더 빠르고 모범 사례에 맞는 배포를 위해 preset security policies(Standard/Strict)를 사용합니다. 2) 탐지 및 대응: Threat Explorer를 사용하여 캠페인을 조사하고, 영향을 받은 사용자를 식별하며, 수정 조치(quarantine, soft delete, hard delete)를 수행합니다. AIR는 메시지와 파일을 자동으로 조사하고 수정할 수 있습니다. 3) 운영 정렬: 중앙 집중식 SOC 워크플로를 위해 Microsoft 365 Defender incidents 및 Microsoft Sentinel과 통합합니다. 이는 Azure Well-Architected Framework의 security pillar 목표인 향상된 위협 보호, 탐지 및 대응을 지원합니다. 일반적인 오해: 임원진, marketing, sales는 phishing/BEC의 빈번한 대상이므로 이 도구가 그들에게 “속한다”고 생각할 수 있습니다. 그러나 그들은 보호의 수혜자일 뿐 운영자는 아닙니다. 보안 팀이 policies를 구성하고, alerts를 모니터링하며, 조사를 수행하고, 수정 조치를 수행합니다. 시험 팁: 문제에서 “Defender for Office 365를 사용하여 어느 팀이 이슈를 해결할 수 있는가”를 묻는다면, 제품을 운영 주체에 매핑하세요. MDO는 보안 제어이자 SOC 조사 도구입니다. 비즈니스 팀은 의심스러운 이메일을 보고할 수 있지만, 보안 팀이 MDO를 사용하여 조사, 헌팅 및 수정 조치를 수행합니다. 또한 MDO는 endpoint 전용 이슈(Defender for Endpoint)나 identity 전용 이슈(Defender for Identity)가 아니라 이메일/협업 위협에 중점을 둔다는 점도 기억하세요.
합격 루틴을 앱에서 이어가세요
실전 모의고사, AI 해설, 약점 회독과 학습 분석을 모두 제공합니다.
16
문제 16
Azure Information Protection 요구 사항을 구현해야 합니다. 가장 먼저 무엇을 구성해야 합니까?
오답입니다. Microsoft Defender Security Center의 Device health and compliance reports는 endpoint posture 및 compliance reporting(주로 Defender for Endpoint 및 Intune과 연계됨)과 관련이 있습니다. 이는 Azure Information Protection scanning을 설정하거나 활성화하지 않습니다. 온-프레미스 파일을 검색/분류하는 AIP 요구 사항은 Defender device compliance report settings가 아니라 AIP scanner configuration을 통해 충족됩니다.
정답입니다. Scanner clusters는 AIP scanner 관리의 기본 구성 요소입니다. 먼저 cluster를 구성해야 scanner nodes(서버)를 해당 cluster에 등록하고 scanner settings를 중앙에서 관리할 수 있습니다. cluster가 존재하고 nodes가 연결된 후에야 repositories, schedules 및 labeling/protection actions를 지정하는 content scan jobs를 정의할 수 있습니다.
오답입니다. Content scan jobs는 무엇을 scan할지(repositories/paths), 언제 scan할지, 어떤 actions를 수행할지(discover, label, protect)를 정의합니다. 그러나 scanner infrastructure, 특히 scanner cluster 및 등록된 scanner nodes가 구축되기 전에는 scan jobs를 효과적으로 생성하고 실행할 수 없습니다. jobs는 cluster 위에 구축되는 이후 단계입니다.
오답입니다. Microsoft Defender Security Center의 Advanced features는 일반적으로 추가 endpoint capabilities(예: advanced hunting, automated investigation 또는 제품 컨텍스트에 따른 integration features)를 활성화합니다. 이는 Azure Information Protection scanning을 구성하지 않습니다. AIP scanner setup은 Defender advanced features를 전환해서가 아니라 AIP/Microsoft Purview Information Protection tooling에서 수행됩니다.
문제 분석
핵심 개념: Azure Information Protection (AIP) scanning(주로 AIP unified labeling scanner를 통해 수행됨)은 sensitivity labels 및 policies를 사용하여 온-프레미스 데이터 리포지토리(예: file shares 및 SharePoint Server)를 검색, 분류하고 선택적으로 보호하는 데 사용됩니다. AIP의 scanning workflow에서는 무엇을 scan할지 정의하기 전에 scanner infrastructure(스캐너가 그룹화되고 관리되는 방식 포함)를 먼저 구축해야 합니다. 정답인 이유: 첫 번째 구성 단계는 Azure Information Protection에서 scanner clusters를 설정하는 것입니다. scanner cluster는 하나 이상의 scanner nodes(scanner service를 실행하는 서버)를 그룹화하고 해당 노드에 대한 중앙 집중식 구성 및 보고를 제공하는 논리적 관리 경계입니다. cluster가 없으면 scanner nodes를 등록하고, scanner settings를 일관되게 적용하거나, scan configurations를 대상으로 지정할 수 있는 기본 컨테이너가 없습니다. cluster가 존재한 후에만 repositories(paths/URLs), schedules, label policies 및 actions(discover-only 대 labeling/protection 적용)을 정의하는 content scan jobs를 만들 수 있습니다. 주요 기능, 구성 및 모범 사례: - Scanner clusters는 scale-out 및 resiliency를 지원합니다. 여러 scanner nodes를 동일한 cluster에 추가하여 throughput 및 high availability를 확보할 수 있습니다. - Clusters는 일관된 구성을 지원합니다. scanner settings(예: network discovery, labeling behavior 및 logging)는 cluster 수준에서 적용됩니다. - clusters 다음에는 content scan jobs를 구성합니다. data sources, include/exclude rules, scheduling 및 labels를 자동으로 적용할지 여부를 정의합니다. - Azure Well-Architected Framework(Operational Excellence 및 Reliability)에 맞추어 multiple nodes를 사용하고, scanner health를 모니터링하며, environment(prod/test) 또는 administrative boundary별로 clusters를 분리합니다. 일반적인 오해: Microsoft Defender for Endpoint(Defender Security Center) settings를 언급하는 옵션은 Defender가 더 넓은 Microsoft security stack의 일부이기 때문에 관련 있어 보일 수 있지만, AIP scanner setup은 Defender advanced features 또는 device compliance reports를 활성화하여 수행되지 않습니다. 이러한 settings는 endpoint management 및 telemetry와 관련이 있으며, AIP의 온-프레미스 content classification workflow와는 관련이 없습니다. 시험 팁: AIP scanner 관련 문제에서는 작업 순서를 기억하십시오. (1) prerequisites(service account, permissions, labeling/policies) 준비, (2) scanner infrastructure(cluster 및 nodes) 구성/등록, (3) repositories를 대상으로 하는 content scan jobs 생성. 질문이 “가장 먼저”를 묻는다면, 이후의 모든 scanning configuration을 가능하게 하는 단계를 선택하십시오.
17
문제 17
사용자가 조직의 다른 사용자들이 로그인하는 데 한 번도 사용한 적이 없는 위치에서 로그인하려고 시도할 때 security alert를 받아야 합니다. 어떤 anomaly detection policy를 사용해야 합니까?
Impossible travel은 동일한 사용자에 대해 지리적으로 먼 위치에서 비현실적인 이동 시간 내에 발생한 sign-ins를 탐지합니다(예: 미국에서 로그인한 뒤 몇 분 후 유럽에서 로그인). 이것은 연속된 sign-ins 사이의 속도와 물리적 가능성에 관한 것이지, 그 위치가 조직에 새로운지 여부에 관한 것이 아닙니다. 단지 어떤 국가가 다른 사용자들에게 한 번도 사용되지 않았다는 이유만으로는 안정적으로 트리거되지 않습니다.
Activity from anonymous IP addresses는 Tor, VPN endpoints 또는 알려진 proxy infrastructure와 같은 anonymization services와 연관된 IPs에서 발생하는 sign-ins를 표시합니다. 이 detection은 geographic novelty가 아니라 IP reputation 및 obfuscation에 초점을 둡니다. 새로운 국가에서의 sign-in이 일반 ISP IP에서 발생할 수 있으며, 그런 경우 반드시 anonymous IP activity로 탐지되지는 않습니다.
Activity from infrequent country는 조직의 tenant sign-in 패턴에서 거의 보이지 않거나 일반적이지 않은 국가/지역에서 발생하는 sign-ins를 탐지하도록 설계되었습니다. 이는 사용자가 조직의 다른 사용자들이 사용하지 않은 위치에서 로그인할 때 alert를 받아야 한다는 요구 사항과 직접적으로 일치합니다. 이것은 사용자별 travel/velocity 확인이 아니라 조직 전체 baseline anomaly입니다.
Malware detection은 Identity Protection sign-in anomaly policy가 아닙니다. Malware 관련 detections는 일반적으로 Microsoft Defender for Endpoint, Defender for Office 365 또는 악성 코드 실행이나 전달을 나타내는 기타 threat protection signals에서 발생합니다. 이는 geographic sign-in anomalies를 다루지 않으므로, 비정상적인 sign-in 위치를 탐지하기 위한 올바른 제어가 아닙니다.
문제 분석
핵심 개념: 이 문제는 Microsoft Entra ID (Azure AD) Identity Protection anomaly detections 및 관련 risk policies/alerts를 다룹니다. Identity Protection은 기본 제공 machine learning signals를 사용하여 의심스러운 sign-in 패턴(예: 익숙하지 않은 위치, anonymous IPs, impossible travel)을 탐지하고 alerts와 user/sign-in risk를 생성할 수 있습니다. 정답인 이유: 요구 사항은 다음과 같습니다: 사용자가 조직의 다른 사용자들이 로그인에 사용한 적이 없는 위치에서 로그인하려고 할 때 alert를 받는 것. 이것은 사용자별 baseline이 아니라 조직 전체의 희소성 신호입니다. “tenant에서 일반적으로 사용되지 않는 국가/지역”에 해당하는 Identity Protection detection은 “Activity from infrequent country”입니다. 이는 조직의 sign-in 기록 전반에서 거의 보이지 않는 국가에서 발생한 sign-ins를 표시하므로, “조직의 다른 사용자들이 한 번도 사용하지 않은 위치”와 직접적으로 일치합니다. 주요 기능 / 사용 방법: - Identity Protection은 기본 제공 detections를 제공하고 이를 risk detections 및 alerts로 표시합니다. - “Activity from infrequent country”는 tenant 맥락 기반입니다: sign-in의 국가를 조직에서 일반적인 패턴과 비교합니다. - sign-in risk/user risk를 기반으로 Conditional Access risk-based policies(예: MFA 요구, password change 요구 또는 차단)를 구성하고, alerts를 Microsoft Sentinel에 통합하여 SOC workflows에 대응할 수 있습니다. - 모범 사례 (Azure Well-Architected Framework—Security pillar): 계층형 제어를 사용합니다—Identity Protection detections + Conditional Access + MFA + monitoring/incident response. 흔한 오해: 많은 사람이 “Impossible travel”을 “새로운 위치”와 혼동합니다. Impossible travel은 동일한 사용자의 두 sign-ins 사이 시간/거리상 물리적으로 불가능한 이동에 관한 것이지, 그 위치가 조직에 새로운지 여부에 관한 것이 아닙니다. 또 어떤 사람은 anonymous IPs를 선택할 수 있지만, 그것은 IP reputation/obfuscation (VPN/Tor/proxies)에 관한 것이며 조직 차원의 새로움과는 관련이 없습니다. 시험 팁: 문구를 주의 깊게 매핑하세요: - “조직의 다른 사용자들이 한 번도 사용하지 않음” => 조직 차원의 희소성 => infrequent country. - “사용자가 서로 멀리 떨어진 두 위치에서 너무 짧은 시간 안에 로그인함” => impossible travel. - “Tor/VPN/anonymous proxy” => anonymous IP. - “Malware” => endpoint/email signals이며, sign-in geography가 아닙니다. 또한 Identity Protection detections는 기본 제공되며, 일반적으로 Conditional Access를 통해 대응을 구성하고 Sentinel/Defender를 통해 alerting/automation을 구성한다는 점도 기억하세요.
18
문제 18
(3개 선택)귀사는 Microsoft Defender for Endpoint를 사용합니다. 회사에는 macros를 포함하는 Microsoft Word 문서가 있습니다. 이 문서는 회사 회계 팀의 디바이스에서 자주 사용됩니다. 기존 보안 태세를 유지하면서 Alerts queue에서 false positive를 숨겨야 합니다. 어떤 세 가지 작업을 수행해야 합니까? 각 정답은 솔루션의 일부를 나타냅니다. 참고: 각 정답 선택에는 1점이 부여됩니다.
alert를 자동으로 resolve하는 것은 정답의 일부입니다. 이는 suppression criteria와 일치하는 향후 alerts가 분석가의 수동 개입 없이 처리되도록 보장하기 때문입니다. Microsoft Defender for Endpoint에서 suppression rules는 일치하는 alerts가 자동으로 resolve되도록 구성할 수 있으며, 이는 반복되는 false positives에 대해 Alerts queue를 깔끔하게 유지합니다. 이렇게 하면 기본 탐지 로직과 보호 설정을 유지하면서 운영 노이즈를 줄일 수 있습니다. 이는 rule을 비활성화하거나 광범위한 exclusion을 만드는 것과는 다르며, 그러한 방식은 보안 태세를 약화시킵니다.
alert를 숨기는 것은 현재 false-positive alert를 Alerts queue에서 제거하므로 정답입니다. 이는 기존 노이즈를 숨기라는 즉각적인 요구 사항을 해결합니다. 이 작업은 endpoint protection이 아니라 분석가 가시성에 영향을 주므로 조직의 방어 통제를 약화시키지 않습니다. 이미 조사되었고 benign한 것으로 알려진 alerts에 유용합니다. 그러나 향후 발생을 해결하려면 suppression 관련 tuning과 함께 사용해야 합니다.
모든 device를 범위로 하는 suppression rule을 생성하는 것은 오답입니다. 범위가 지나치게 넓어 전체 환경에서 유사한 alerts를 suppress하게 되기 때문입니다. 이는 회계 팀 외부의 디바이스에서 실제 악성 macro 활동을 숨길 수 있으므로 보안 태세를 약화시킵니다. 문제는 기존 보안 태세를 유지할 것을 명시적으로 요구하므로, 가장 좁고 효과적인 범위를 사용해야 함을 의미합니다. 이 시나리오에서는 device group이 적절한 경계입니다.
device group을 범위로 하는 suppression rule을 생성하는 것은 정답입니다. macros가 포함된 Word 문서가 예상되고 자주 사용되는 회계 팀의 디바이스로 tuning을 제한하기 때문입니다. 이 좁은 범위는 조직의 나머지 부분에서는 유사한 alerts가 계속 표시되도록 하여 기존 보안 태세를 유지합니다. Device-group 범위 지정은 특정 집단에 대해 알려진 benign 동작을 처리할 때 Defender for Endpoint의 모범 사례입니다. 이는 관련 없는 사용자와 시스템 전반에 불필요한 blind spots를 만드는 것을 방지합니다.
alert를 생성하는 것은 Microsoft Defender for Endpoint에서 false positives를 숨기는 데 사용되는 alert-tuning 또는 queue-management 작업이 아니므로 오답입니다. 이 시나리오는 알려진 benign alerts를 suppress하거나 숨기기 위해 어떤 작업을 수행해야 하는지를 묻는 것이지, 이를 재현하거나 검증하는 방법을 묻는 것이 아닙니다. alert를 관찰하는 것이 분석가가 이를 이해하는 데 도움이 될 수는 있지만, alert 생성은 Defender의 suppression 및 alert-handling 기능이 설명하는 운영 솔루션의 일부가 아닙니다. 따라서 필요한 작업 중 하나로 선택해서는 안 됩니다.
문제 분석
핵심 개념: 이 문제는 보호를 약화시키지 않으면서 Microsoft Defender for Endpoint에서 false-positive alert 노이즈를 줄이는 것에 관한 것입니다. 올바른 접근 방식은 탐지를 비활성화하는 대신 alert suppression과 좁은 범위 지정을 사용하여 alert 처리를 조정하는 것입니다. 정답인 이유: 기존 false-positive alert를 queue에서 숨기고, 회계 팀의 device group으로 제한된 suppression rule을 만들고, 반복적으로 일치하는 항목이 계속해서 분석가의 조치를 요구하지 않도록 alert가 자동으로 resolve되도록 구성해야 합니다. 주요 기능: Hide는 현재 노이즈를 분석가 보기에서 제거하고, suppression rules는 향후 일치하는 alerts를 방지하거나 자동으로 resolve하며, device-group 범위 지정은 환경의 다른 곳에서 보호를 유지합니다. 일반적인 오해: 모든 device에 대한 광범위한 suppression은 너무 위험하며, alert 생성은 remediation 또는 tuning 작업이 아닙니다. 시험 팁: 문제에서 '기존 보안 태세를 유지'라고 하면, 가장 대상이 명확한 suppression 범위를 선호하고 tenant 전체 exclusions 또는 탐지 비활성화는 피하십시오.
19
문제 19
Azure Sentinel workspace가 있습니다. Azure portal에서 playbook을 수동으로 테스트해야 합니다. Azure Sentinel에서 어디에서 테스트를 실행할 수 있습니까?
Playbooks는 Sentinel이 automation에 사용하는 Logic Apps를 만들고, 보고, 관리하는 위치이지만, 컨텍스트에서 playbook을 수동으로 실행하는 표준적인 Sentinel 위치는 아닙니다. 이 블레이드에서 기본 Logic App 리소스에 액세스할 수는 있지만, 이는 문제에서 언급하는 Sentinel 실행 화면이 아니라 관리 기능입니다. 시험 관점에서 이 선택지는 playbook 관리와 Sentinel 운영 내 수동 실행을 혼동한 것입니다. 따라서 Azure Sentinel에서 테스트를 실행할 위치에 대한 최선의 답은 아닙니다.
Analytics는 detection rule을 만들고 관리하는 데 사용되며, 여기에는 alert 또는 incident가 생성될 때 playbook을 호출할 수 있는 automation 구성도 포함됩니다. 그러나 필요할 때 수동으로 playbook을 실행하는 기본 인터페이스는 제공하지 않습니다. 그 목적은 incident response 실행이 아니라 detection engineering입니다. 이런 이유로 Analytics는 Sentinel에서 playbook을 수동으로 테스트하는 올바른 위치가 아닙니다.
Threat intelligence는 Microsoft Sentinel 내에서 침해 지표와 관련 intelligence 데이터를 관리하는 데 사용됩니다. Logic Apps를 수동으로 실행하거나 playbook을 테스트하는 역할은 없습니다. Threat intelligence가 detections 및 조사에 영향을 줄 수는 있지만, automation 실행 화면은 아닙니다. 따라서 이 선택지는 명백히 틀렸습니다.
Incidents가 정답인 이유는 Microsoft Sentinel이 분석가가 조사 또는 대응 중 incident에서 playbook을 수동으로 트리거할 수 있도록 하기 때문입니다. 이는 실제 보안 사례의 컨텍스트에서 automation을 테스트하거나 실행하려는 경우의 일반적인 Sentinel 워크플로입니다. incident에서 playbook을 실행하면 playbook이 예상되는 Sentinel incident 엔터티와 관련 컨텍스트를 전달받을 수 있습니다. 또한 이는 incident 기반 playbook이 포털에서 일반적으로 검증되는 방식과도 일치합니다.
문제 분석
핵심 개념: 이 문제는 Azure portal 내 Microsoft Sentinel에서 분석가가 playbook을 수동으로 실행할 수 있는 위치를 묻습니다. Sentinel에서 playbook은 일반적으로 incident에 대응하여 실행되며, automation rule을 통해 자동으로 실행되거나 조사 중에 분석가가 수동으로 실행할 수 있습니다. 정답인 이유: 정답은 Incidents입니다. Sentinel에서는 분석가가 incident를 선택하고 해당 incident에서 연결된 playbook을 수동으로 실행할 수 있기 때문입니다. 이는 특히 incident 기반 automation을 테스트하거나 컨텍스트에서 playbook을 호출할 때 사용하는 표준적인 포털 내 Sentinel 워크플로입니다. 주요 특징: - Sentinel의 playbook은 대응 및 enrichment 작업에 사용되는 Azure Logic Apps입니다. - Sentinel에서의 수동 실행은 일반적으로 컨텍스트 기반이며, 즉 incident 레코드에서 시작됩니다. - Playbooks 블레이드는 주로 playbook을 보고, 만들고, 관리하는 데 사용되며, Sentinel에서의 실행은 일반적으로 incidents에서 이루어집니다. 일반적인 오해: - 많은 응시자가 Sentinel에서 playbook을 관리하는 것과 수동으로 실행하는 것을 혼동합니다. 기본 Logic App은 Playbooks 영역에서 열 수 있지만, Sentinel의 수동 실행 경험은 incidents에 연결되어 있습니다. - Analytics rule은 automation을 연결할 수 있지만, 필요할 때 수동으로 playbook을 실행하는 위치는 아닙니다. - Threat intelligence는 automation 워크플로 실행과 관련이 없습니다. 시험 팁: 문제가 Microsoft Sentinel에서 playbook을 수동으로 실행하는 위치를 묻는다면, 운영 워크플로를 떠올리십시오. 분석가는 incidents를 조사한 다음 incident에서 대응 작업을 트리거합니다. Logic Apps 관리(Playbooks)와 Sentinel 컨텍스트에서의 실행(Incidents)을 구분하십시오.
20
문제 20
참고: 이 문제는 동일한 시나리오를 제시하는 일련의 문제 중 일부입니다. 시리즈의 각 문제에는 명시된 목표를 충족할 수 있는 고유한 솔루션이 포함되어 있습니다. 일부 문제 세트에는 둘 이상의 올바른 솔루션이 있을 수 있지만, 다른 문제 세트에는 올바른 솔루션이 없을 수도 있습니다. 이 섹션의 문제에 답한 후에는 해당 문제로 돌아갈 수 없습니다. 따라서 이러한 문제는 검토 화면에 표시되지 않습니다. Microsoft Defender for Identity와 Active Directory의 통합을 구성하고 있습니다. Microsoft Defender for Identity portal에서 공격자가 악용할 수 있도록 여러 계정을 구성해야 합니다. 솔루션: Entity tags에서 해당 계정을 Honeytoken accounts로 추가합니다. 이것이 목표를 충족합니까?
예가 정답인 이유는 Microsoft Defender for Identity가 portal의 Entity tags를 통해 계정을 Honeytoken accounts로 태그하는 기능을 지원하기 때문입니다. Honeytoken accounts는 공격자가 정찰 및 측면 이동 중 열거하거나 사용하려고 시도할 수 있도록 의도적으로 노출되거나 발견 가능하게 만든 미끼 계정입니다. 이러한 계정에 접근하거나 조회하면 Defender for Identity는 해당 활동을 매우 의심스러운 것으로 간주하고 강력한 경고를 생성할 수 있습니다. 이는 기만 기반 탐지 전략의 일부로 공격자가 악용할 수 있도록 여러 계정을 구성해야 한다는 요구 사항을 직접적으로 충족합니다.
아니요가 오답인 이유는 Entity tags에서 계정을 Honeytoken accounts로 추가하는 것이 Microsoft Defender for Identity에서 기만용 계정을 표시하는 정확한 지원 방법이기 때문입니다. 이 기능은 합법적으로 사용되어서는 안 되는 계정을 식별하고 공격자가 해당 계정과 상호 작용할 때 경고를 트리거하도록 특별히 설계되었습니다. 시나리오에서는 공격자가 악용할 수 있도록 계정을 구성하라고 요구하고 있으며, 이는 honeytokens의 목적과 일치합니다. 따라서 이 솔루션이 목표를 충족하지 않는다고 말하는 것은 Defender for Identity의 기만 기능이 작동하는 방식을 오해한 것입니다.
문제 분석
핵심 개념: 이 문제는 Microsoft Defender for Identity의 기만(deception) 기능, 특히 공격자가 의심스러운 방식으로 사용할 때 모니터링할 수 있는 미끼 계정을 구성하는 방법에 대한 지식을 평가합니다. Defender for Identity portal에서 계정을 Honeytoken accounts로 추가하는 것이 악의적인 활동의 매력적인 표적으로 표시하는 올바른 방법인지에 초점을 맞춥니다. 정답인 이유: Microsoft Defender for Identity의 Honeytoken accounts는 정상 운영 중에는 절대 사용되어서는 안 되는 기만용 엔터티로 작동하도록 설계되었습니다. Entity tags에서 선택한 Active Directory 계정을 Honeytoken accounts로 태그하면, Defender for Identity는 해당 계정에 대한 모니터링 민감도를 높이고, 해당 계정이 조회되거나 인증되거나 그 밖의 방식으로 의심스럽게 사용될 경우 높은 신뢰도의 경고를 생성합니다. 이는 공격자가 악용할 수 있도록 계정을 구성한다는 목표와 직접적으로 일치합니다. 그 목적이 미끼 ID에 대한 정찰, 자격 증명 탈취, 측면 이동 시도를 탐지하는 것이기 때문입니다. 주요 기능 / 구성: - Microsoft Defender for Identity의 Entity tags를 사용하면 관리자가 민감한 계정 또는 기만용 계정을 분류할 수 있습니다. - Honeytoken accounts는 공격자 활동을 유인하기 위한 미끼 AD 계정입니다. - Honeytoken account와의 모든 상호 작용은 정상적인 사용자와 서비스가 이를 사용해서는 안 되므로 매우 의심스러운 것으로 간주됩니다. - Defender for Identity는 이러한 태그를 사용하여 탐지를 개선하고 정찰 및 자격 증명 오용과 관련된 경고를 발생시킵니다. - 이는 하이브리드 또는 온-프레미스 Active Directory 환경에서의 ID 기반 위협 탐지의 일부입니다. 일반적인 오해: - 응시자는 Honeytoken accounts를 privileged accounts와 혼동하는 경우가 많습니다. privileged accounts는 실제 관리 ID인 반면, honeytokens는 탐지를 위해 특별히 생성된 미끼입니다. - 일부는 계정이 Active Directory에서만 구성되어야 한다고 가정합니다. 실제로는 portal에서의 Defender for Identity 태깅이 기만 기반 탐지 동작을 활성화하는 중요한 부분입니다. - 또 다른 사람들은 honeytokens가 공격을 방지한다고 생각합니다. honeytokens는 공격자를 직접 차단하지 않으며, 대신 공격자가 이들과 상호 작용할 때 높은 신호의 탐지를 제공합니다. 시험 팁: - 목표가 공격자 탐지를 위한 미끼 ID를 만드는 것이라면, Honeytoken accounts를 떠올리십시오. - Defender for Identity에서 Entity tags는 sensitive 또는 honeytoken과 같은 계정을 분류하는 데 사용됩니다. - Honeytoken 사용은 정상 운영에서 드물거나 없어야 하므로 경고의 신뢰도가 높습니다. - 시험에서는 보호 제어와 탐지/기만 제어를 구분하십시오.
시험 도메인
출제 비중을 기준으로 먼저 학습할 영역을 정하세요.
Configure protections and detections출제율 20%
Manage incident response출제율 30%
Manage security threats출제율 25%
모의고사
2 모의고사 · 50 문제 · 100 분
다른 Microsoft 자격증












지금 학습 시작하기
Cloud Pass를 다운로드하여 Microsoft SC-200 전체 학습을 이어가세요.