
AI搭載
3重AI検証済み解答&解説
すべてのGoogle Professional Cloud Developer解答は3つの主要AIモデルで交差検証され、最高の精度を保証します。選択肢ごとの詳細な解説と深い問題分析を提供します。
試験ドメイン
練習問題
Company overview: SkyLend is a peer‑to‑peer micro‑lending platform expanding from one country to global regions (us-central1, europe-west1, asia-southeast1) and targeting a 10x increase in concurrent users (from 5,000 to 50,000) while reducing operational overhead; technical requirement: the public /loan and /payment APIs must meet 99.9% monthly availability and 95th percentile latency under 250 ms per region, teams must define SLIs and SLOs, track error budgets, visualize SLO health, and receive burn‑rate alerts (2x over 1 hour and 5x over 5 minutes) without building custom tooling; compliance and exec reporting require auditable SLO dashboards across services and regions. Question: Which Google Cloud product best meets SkyLend’s need to define, monitor, and alert on service level indicators and objectives (including error budgets and burn‑rate alerts) across regions?
Cloud Profiler is designed for continuous code-level performance analysis, such as identifying CPU hot spots, memory allocation issues, and expensive functions in running applications. That makes it useful for optimization work after a latency or cost problem has been detected, but it does not provide first-class SLO objects or service-level compliance tracking. It cannot calculate error budgets or represent whether a service is meeting a 99.9% availability target over a rolling period. It also is not the tool used to create standardized SLO burn-rate alerts or executive SLO dashboards across regions.
Cloud Monitoring is the correct answer because it is Google Cloud’s native product for defining services, attaching SLIs, and managing SLOs over rolling compliance periods. It can evaluate availability and latency-oriented objectives using request-based or windows-based SLIs derived from built-in or custom metrics, which fits the requirement to monitor user-facing APIs across multiple regions. Cloud Monitoring also computes and visualizes error budget consumption automatically, so teams can track whether they are operating within reliability targets. In addition, it supports SLO-based alerting patterns such as burn-rate alerts over different time windows, and its dashboards provide centralized, auditable visibility for engineering, compliance, and executive stakeholders.
Cloud Trace is used to capture and analyze distributed request traces so developers can understand where latency is being introduced across services and dependencies. It is valuable for troubleshooting a slow /loan or /payment request, but it does not define service-level objectives or compute compliance against an SLO target. Trace data may help explain why an SLO is being missed, yet the SLO itself and its error budget are managed elsewhere. It also does not serve as the primary product for burn-rate alerting and auditable SLO reporting across services and regions.
Cloud Logging is focused on collecting, storing, querying, and routing logs generated by applications and infrastructure. Although logs can be used to create log-based metrics that feed into Monitoring, Logging itself does not provide native SLO entities, error budget calculations, or SLO health dashboards. Teams could use logs as an input signal, but they would still rely on Cloud Monitoring to define and evaluate the SLO. Therefore, Logging alone does not satisfy the requirement for built-in SLI/SLO management and burn-rate alerting without custom tooling.
問題分析
Core Concept: This question tests Google Cloud’s built-in Site Reliability Engineering (SRE) capabilities for defining and operating SLIs/SLOs, tracking error budgets, and generating burn-rate alerts without custom tooling. In Google Cloud, these capabilities are provided through Cloud Monitoring’s SLO Monitoring (part of Google Cloud Observability). Why the Answer is Correct: Cloud Monitoring is the product that lets teams define service level objectives for services (including multi-region services), automatically compute SLI compliance over rolling windows, track error budget consumption, and create burn-rate alerting policies (e.g., “2x over 1 hour” and “5x over 5 minutes”). It also supports auditable dashboards and reporting via Monitoring dashboards and integration with Cloud Logging/Trace metrics, meeting the requirement for executive/compliance visibility across services and regions. Key Features / How It Meets Requirements: 1) SLOs and SLIs: Define availability and latency SLOs using request-based metrics (e.g., from load balancers, Cloud Run, GKE, or custom metrics). Latency SLOs can be based on distribution metrics and thresholds (e.g., 95th percentile < 250 ms). 2) Error budgets: Automatically computed from the SLO target (e.g., 99.9%) and displayed as remaining budget and burn. 3) Burn-rate alerts: Native alerting on SLO burn rate with multi-window, multi-burn policies (exactly matching “fast burn” and “slow burn” patterns). Alerts can route to email, PagerDuty, Slack via notification channels. 4) Dashboards and auditability: Central dashboards per service/region, with consistent definitions and historical views suitable for exec reporting. Common Misconceptions: People often confuse Monitoring with Logging/Trace/Profiler because all are in Observability. Logging stores logs; Trace shows latency traces; Profiler shows CPU/memory hotspots. None of these alone provides first-class SLO objects, error budgets, and burn-rate alerting. Exam Tips: For SLOs/error budgets/burn-rate alerting on Google Cloud, think “Cloud Monitoring SLO Monitoring.” Pair it conceptually with Cloud Logging/Trace for troubleshooting, but Monitoring is the control plane for SRE objectives and alerting. Also map requirements to the Google Cloud Architecture Framework’s Reliability pillar: define SLOs, monitor user-facing SLIs, and alert on error budget burn rather than raw resource metrics.
Your IoT analytics company runs a multi-tenant data pipeline on a Google Kubernetes Engine (GKE) Autopilot cluster in us-central1 for 120 production customers, and you promote releases with Cloud Deploy; during a 2-week refactor of a telemetry aggregator service (container image <250 MB), developers will edit code every 5–10 minutes on laptops with 8 GB RAM and limited CPU and must validate changes locally before pushing to the remote repository. Requirements: • Automatically rebuild and redeploy on local code changes (hot-reload loop ≤ 10 seconds). • Local Kubernetes deployment should closely emulate the production GKE manifests and deployment flow. • Use minimal local resources and avoid requiring a remote container registry for inner-loop builds. Which tools should you choose to build and run the container locally on a developer laptop while meeting these constraints?
Docker Compose and dockerd can provide a fast local rebuild/restart loop, but it does not closely emulate Kubernetes manifests or the Kubernetes deployment flow used with GKE and Cloud Deploy. Compose uses a different configuration model (docker-compose.yml) and lacks native concepts like Deployments, Services, ConfigMaps, and RBAC. This fails the requirement to closely emulate production Kubernetes manifests and deployment behavior.
Terraform and kubeadm are oriented toward provisioning infrastructure and bootstrapping Kubernetes clusters, not rapid inner-loop development. kubeadm is heavyweight and operationally complex for a laptop workflow, and Terraform adds infrastructure management overhead rather than enabling hot-reload. Neither provides an automatic file-watching rebuild/redeploy loop comparable to Skaffold, so the ≤10-second iteration requirement is not met.
Minikube provides a lightweight local Kubernetes cluster suitable for laptops and can use a local image store so developers don’t need to push to a remote registry. Skaffold automates the inner loop by watching for code changes and rebuilding/redeploying to Kubernetes using the same manifests (or Kustomize/Helm) as production. Together they best satisfy fast hot-reload, Kubernetes fidelity, and minimal local/remote dependencies.
kaniko and Tekton are primarily designed for building images and running pipelines in Kubernetes (CI/CD), not for a fast local developer inner loop on resource-constrained laptops. kaniko commonly pushes to a registry, and Tekton requires a Kubernetes cluster and pipeline setup overhead. This combination is better suited to remote build systems (e.g., in-cluster CI) than local hot-reload development without a registry.
問題分析
Core concept: This question tests inner-loop developer workflows for Kubernetes apps: fast local build+deploy on file changes, Kubernetes-manifest fidelity, and avoiding remote dependencies. In Google Cloud–aligned workflows, Skaffold is the canonical tool for continuous local development with Kubernetes, and a lightweight local cluster (Minikube) provides a close approximation of GKE manifests. Why the answer is correct: Minikube runs a single-node Kubernetes cluster locally with relatively low overhead and supports using the local Docker daemon (or containerd) so images can be built and used without pushing to a remote registry. Skaffold provides an automated “edit-build-deploy” loop: it watches source files, rebuilds the container, and redeploys to the local cluster. With file sync (manual sync rules) and/or fast incremental builds, Skaffold can achieve sub-10-second iteration for many code changes, meeting the hot-reload/inner-loop requirement. Skaffold also deploys using the same Kubernetes manifests (or Kustomize/Helm) you use in production, closely emulating the GKE deployment shape. Key features / best practices: - Skaffold “dev” mode: file watching + continuous build + deploy. - Local builds without registry: use Minikube’s Docker environment (e.g., building directly into the cluster’s daemon) or configure Skaffold local builder with “push: false”. - Manifest fidelity: reuse production YAML/Kustomize overlays; keep environment-specific differences in overlays rather than separate tooling. - Resource constraints: Minikube can be tuned (CPU/memory limits) and is typically lighter than running a full multi-node local cluster. Common misconceptions: - Docker Compose is fast, but it does not emulate Kubernetes objects (Deployments, Services, ConfigMaps, RBAC) or the same deployment flow. - kaniko and Tekton are primarily CI/CD build primitives; they are not optimized for laptop inner-loop hot reload and usually assume a registry and cluster-based execution. - Terraform/kubeadm are for provisioning clusters/infrastructure, not rapid local iteration. Exam tips: For Professional Cloud Developer, map requirements to the developer lifecycle: inner loop (Skaffold, local K8s like Minikube/kind) vs outer loop (Cloud Build/Cloud Deploy). When you see “hot reload”, “watch files”, “Kubernetes manifests”, and “no remote registry”, Skaffold + a local Kubernetes cluster is the standard answer. Also note Autopilot is production; local emulation focuses on Kubernetes API compatibility, not Autopilot-specific scheduling behavior.
Your IoT solution in Google Cloud collects data from thousands of sensor devices. Each device must publish messages to its own Pub/Sub topic, and consume messages from its own subscription. You need to ensure that each device can only publish and subscribe to its own Pub/Sub resources, while preventing access to others. What should you do?
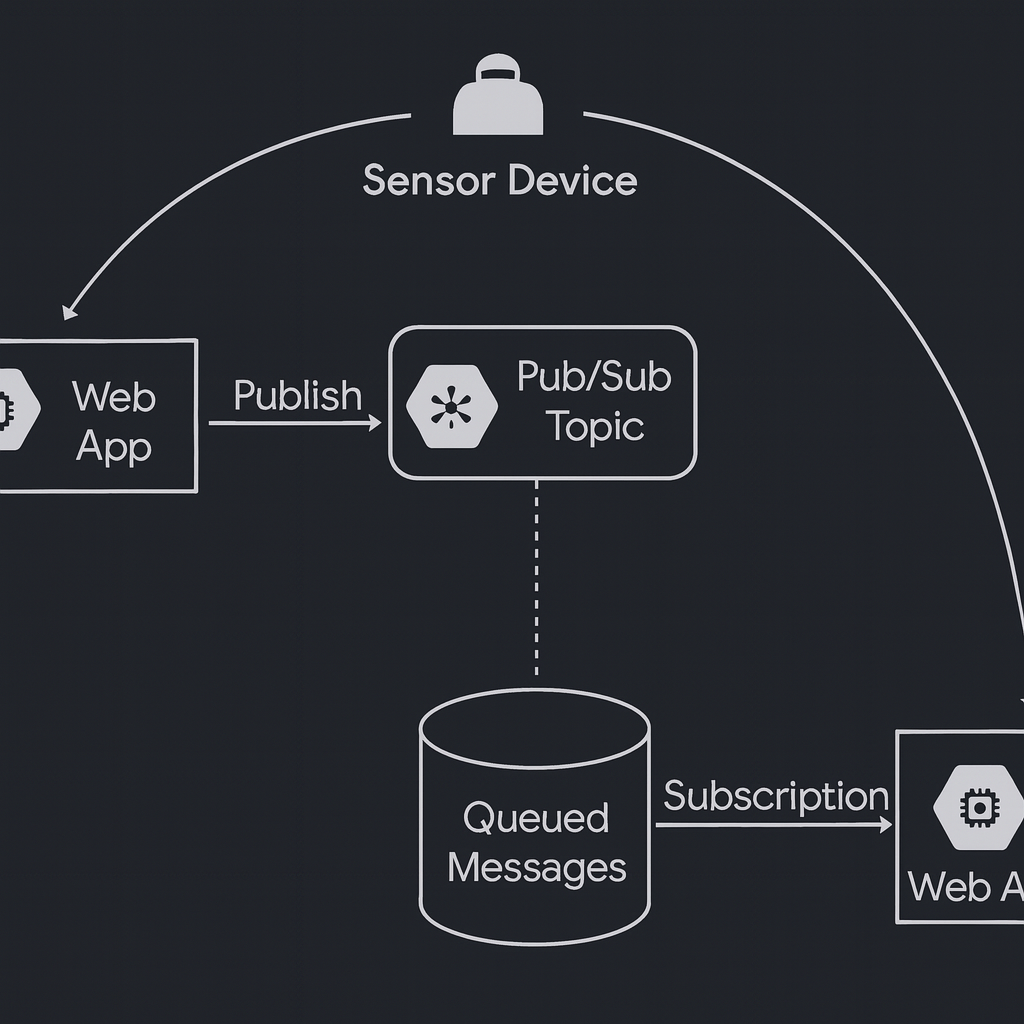
Correct. Assign pubsub.publisher on each device’s topic and pubsub.subscriber on each device’s subscription, binding the specific device identity at the resource level. This enforces least privilege and strong isolation: IAM evaluation will deny access to any other topic/subscription. It also improves auditability and supports targeted revocation if a single device is compromised.
Incorrect. Project-level pubsub.publisher and pubsub.subscriber allow the device identity to publish to any topic and subscribe to any subscription in the project (subject to role permissions), which violates the requirement to restrict each device to its own resources. This is a common anti-pattern for multi-tenant or per-device isolation scenarios.
Incorrect. Granting pubsub.topics.create and pubsub.subscriptions.create focuses on provisioning, not on restricting publish/subscribe to existing resources. It also increases risk by allowing devices to create arbitrary topics/subscriptions (potential quota exhaustion and cost growth). Even with a custom role, you still need resource-level publish/subscribe permissions for isolation.
Incorrect. A shared service account means all devices effectively have the same permissions, so any device can publish/subscribe to any resource that service account can access. This breaks isolation and makes it hard to attribute actions to a specific device. It also complicates incident response because rotating/revoking credentials impacts all devices.
問題分析
Core concept: This question tests Google Cloud IAM authorization for Pub/Sub using the principle of least privilege. Pub/Sub permissions are granted via IAM roles, and bindings can be applied at different resource levels (project, topic, subscription). For per-device isolation, you must scope permissions to the specific topic/subscription each device owns. Why the answer is correct: Binding each device identity (typically a unique service account per device, or a unique workload identity) to pubsub.publisher on its own topic and pubsub.subscriber on its own subscription enforces strict resource-level access control. Each device can publish only to its topic and pull/ack only from its subscription, and IAM prevents it from interacting with any other device’s Pub/Sub resources. This aligns with the Google Cloud Architecture Framework security pillar: least privilege, strong identity, and compartmentalization. Key features / best practices: - Use resource-level IAM on Pub/Sub topics and subscriptions rather than broad project-level grants. - Prefer one identity per device (or per device class) to enable revocation/rotation and auditability. - Use predefined roles (pubsub.publisher, pubsub.subscriber) rather than overly broad roles; they map cleanly to required actions (publish vs pull/ack). - Operationally, manage bindings via automation (Terraform/Deployment Manager/CI) to handle thousands of devices. Common misconceptions: - Granting roles at the project level feels simpler but breaks isolation because the identity can access all topics/subscriptions in the project. - Creating custom roles with create permissions confuses provisioning with runtime access; devices generally should not create Pub/Sub resources. - Sharing one service account across devices reduces IAM overhead but eliminates per-device isolation and makes incident response (revoking one device) difficult. Exam tips: When you see “only access its own resource,” choose the narrowest IAM scope (resource-level) and the smallest predefined roles that match the actions. For Pub/Sub, remember: publisher is for topics; subscriber is for subscriptions. Avoid project-level bindings unless the requirement explicitly allows broad access.
You are designing a tablet app for municipal tree inspectors that must store hierarchical observations (city -> district -> park -> tree -> inspection) with up to 5 nested levels and support offline work for up to 72 hours; upon reconnect, the app must automatically sync local changes and handle conflicts gracefully. A backend on Cloud Run will use a dedicated service account to enrich the same records (e.g., geocoding, policy tags) directly in the database, performing up to 5,000 writes per minute at peak. The solution must scale securely to 250,000 monthly active users in the first quarter and provide client SDKs with built-in offline caching and synchronization. Which database and IAM role should you assign to the backend service account?
Cloud SQL supports relational modeling for hierarchies, but it does not provide Google client SDKs with built-in offline persistence and automatic sync for mobile/tablet apps. You would need to implement local storage, change tracking, conflict resolution, and sync logic yourself. roles/cloudsql.editor also doesn’t directly grant database-level DML permissions; it manages instances and is broader than needed for app-level writes.
Bigtable can handle high write throughput and large scale, but it is a wide-column store optimized for time-series/analytics-style access patterns, not hierarchical document navigation with offline-first mobile sync. There are no Firestore-like client SDKs for offline caching/synchronization. Additionally, roles/bigtable.viewer is read-only, so it cannot support the backend requirement to enrich records with writes.
Firestore in Native mode matches the requirements for hierarchical observations and offline-first operation via Firebase/Firestore client SDKs (offline persistence, local cache, automatic sync on reconnect). It scales to large user bases and supports high write rates when designed to avoid hot spots. roles/datastore.user provides the backend service account the necessary read/write access to Firestore to perform enrichment updates securely.
Firestore in Datastore mode is primarily for Datastore API compatibility and does not align as directly with Firebase-style offline synchronization expectations for client apps. Even if the database choice were acceptable, roles/datastore.viewer is read-only and cannot support the Cloud Run backend’s requirement to perform up to 5,000 writes per minute to enrich records.
問題分析
Core concept: This question tests selecting a database that supports hierarchical data modeling plus mobile/offline-first synchronization using Google-provided client SDKs, and choosing the least-privilege IAM role for a Cloud Run service account that must write to that database. Why the answer is correct: Firestore in Native mode is the best fit because it is the database behind Firebase/Firestore client SDKs that provide built-in offline persistence, local caching, and automatic synchronization when connectivity returns—exactly matching the 72-hour offline requirement and “sync + conflict handling” requirement. Firestore’s document/collection model naturally represents hierarchical entities (city/district/park/tree/inspection) via subcollections or by storing references/IDs, and it supports up to 100 levels of subcollections, so 5 nested levels is well within limits. For backend enrichment from Cloud Run, the service account needs read/write access to Firestore; roles/datastore.user grants the ability to read and write entities/documents (and is the common least-privilege baseline for server-side access), enabling the backend to perform up to 5,000 writes/minute. Key features and best practices: - Offline-first: Firestore SDKs (Android/iOS/Web) support offline persistence and automatic sync; conflicts are typically handled via “last write wins” semantics and can be improved with transactions, server timestamps, and custom merge logic. - Scale: Firestore is serverless and designed for high concurrency and large user bases; it aligns with Google Cloud Architecture Framework principles for scalability and operational excellence. - Security: Use Firebase Authentication/Identity Platform for end-user auth and Firestore Security Rules for client access; use a dedicated service account for Cloud Run with IAM-based access. - Throughput: 5,000 writes/min (~83 writes/sec) is generally feasible; design for hot-spot avoidance (spread writes across document keys, avoid single-document contention). Common misconceptions: - Cloud SQL can store hierarchical data but does not provide offline sync SDKs; you would need to build custom sync/conflict resolution. - Bigtable is highly scalable but lacks mobile offline sync SDKs and is not ideal for hierarchical document access patterns. - Firestore in Datastore mode is oriented toward Datastore APIs and does not align as directly with Firebase offline sync expectations. Exam tips: When you see “client SDKs with offline caching and automatic synchronization,” think Firestore (Native mode) / Firebase. Then choose an IAM role that enables required operations (read/write) for the backend service account; viewer roles won’t work for writes, and overly broad roles should be avoided.
Your mobile health platform currently stores per-user workout telemetry and personalized settings in a single PostgreSQL instance; records vary widely by user and evolve frequently as new device firmware adds fields (e.g., heart-rate variability, sleep stages), resulting in weekly schema migrations, downtime risks, and high operational overhead; you expect up to 8 million users, peak 45,000 writes/second concentrated by userId, simple key-based reads per user, and only per-user transactional consistency is required, not multi-user joins or complex cross-entity transactions. To simplify development and scaling while accommodating highly user-specific, evolving state without rigid schemas, which Google Cloud storage option should you choose?
Cloud SQL (PostgreSQL) is a managed relational database but still requires schema management and careful capacity planning. Weekly schema migrations and downtime risk are exactly the pain points described. At 45,000 writes/second, a single instance will not suffice; scaling typically requires read replicas (not for writes) or application-level sharding, increasing operational overhead. It also doesn’t naturally support highly variable per-user records without frequent migrations.
Cloud Storage is an object store for blobs (files) with very high durability and throughput, but it is not a database optimized for low-latency key-based reads/writes with per-user transactional consistency. You could store per-user JSON objects, but you’d lose efficient querying, atomic updates across multiple related items, and database-like concurrency controls. It’s better for raw telemetry archives, exports, or batch analytics inputs.
Cloud Spanner provides horizontally scalable relational SQL with strong consistency and high availability, and it can handle very high write throughput. However, it is schema-based and best when you need relational modeling, SQL joins, and cross-row/table transactions at scale. The scenario explicitly wants to avoid rigid schemas and frequent migrations, and only needs per-user transactional consistency with simple key-based reads—making Spanner unnecessarily complex and costly.
Cloud Datastore/Firestore is purpose-built for scalable, low-ops NoSQL document storage with flexible schemas. It fits per-user partitioning (userId as document key), supports high write rates with automatic scaling, and avoids weekly schema migrations because documents can evolve field-by-field. It also supports transactions/batched writes for per-user consistency without requiring multi-entity relational joins. This directly addresses scaling, agility, and operational overhead concerns.
問題分析
Core concept: This question tests choosing a storage system for massive scale, high write throughput, and rapidly evolving per-entity data without frequent schema migrations. In Google Cloud, the primary fit is a schemaless (or schema-flexible) document/NoSQL database with automatic scaling and per-entity transactional semantics. Why the answer is correct: Cloud Datastore/Firestore (Firestore in Native mode) is designed for key-based access patterns and document-style data that can evolve over time (new fields can be added without migrations). Your workload is strongly partitionable by userId, needs simple reads/writes per user, and only requires transactional consistency within a user’s data. Firestore supports atomic operations and transactions within a set of documents, and it naturally models “per-user” documents/subcollections. It also scales horizontally to very high request rates without managing instances, reducing operational overhead and downtime risk. Key features / best practices: - Flexible schema: documents can contain varying fields per user and evolve as firmware adds telemetry attributes. - High scalability: automatic sharding/partitioning and managed operations align with 8M users and bursty writes. - Data modeling: use a top-level users collection keyed by userId; store settings in a user document and telemetry in subcollections (e.g., users/{userId}/telemetry/{eventId}). - Consistency/transactions: use transactions/batched writes for per-user invariants; avoid cross-user transactional requirements. - Architecture Framework alignment: operational excellence (managed service), reliability (multi-zone replication), and performance efficiency (low-latency key lookups). Common misconceptions: Spanner is often chosen for “scale,” but it’s relational and schema-based; frequent schema changes and document-like variability increase friction. Cloud SQL is familiar but won’t meet the scaling/ops goals at 45k writes/sec without significant sharding and operational complexity. Cloud Storage is durable and cheap but not a low-latency database for key-based reads/writes with transactional semantics. Exam tips: When you see: (1) rapidly changing fields, (2) per-entity access by key, (3) massive scale with minimal ops, and (4) only entity-level transactions, think Firestore/Datastore. Choose Spanner when you need relational modeling, SQL, and strong consistency across rows/tables at global scale; choose Cloud SQL for traditional relational workloads with moderate scale; choose Cloud Storage for blobs/objects, not operational database access patterns.
外出先でもすべての問題を解きたいですか?
Cloud Passをダウンロード — 模擬試験、学習進捗の追跡などを提供します。
During a disaster recovery drill, your workload fails over to a standby Google Cloud project in europe-west1. Within 20 seconds, a newly created and previously idle Cloud Storage bucket begins handling approximately 2100 object write requests per second and 7800 object read requests per second. As the surge continues, services calling the Cloud Storage JSON API start receiving intermittent HTTP 429 and occasional 5xx errors. You need to reduce failed responses while preserving as much throughput as possible. What should you do?
Distributing uploads across many buckets can help in some systems that have per-bucket hot-spotting constraints, but Cloud Storage generally supports very high request rates per bucket. The scenario emphasizes a newly created idle bucket and a sudden step increase, which points to ramp/throttling behavior and retry storms. Sharding adds operational complexity (naming, lifecycle, IAM, analytics) without directly addressing the spike-induced 429/5xx.
The JSON and XML APIs are different interfaces to the same Cloud Storage service. Switching APIs does not meaningfully change backend throttling behavior, quotas, or the need to handle 429/5xx correctly. You would still need proper retry and backoff logic. This option is a common trap: changing protocol rarely fixes rate limiting or transient errors caused by sudden load.
Propagating HTTP errors to end users does nothing to reduce failed responses; it simply exposes internal throttling and transient failures to customers and increases perceived downtime. Best practice is to handle 429/5xx with controlled retries, backoff, and circuit-breaking where appropriate. For DR/failover, you want graceful recovery and stable throughput, not raw error passthrough.
Client-side rate limiting with a gradual ramp-up smooths the sudden traffic spike that triggers 429 throttling and occasional 5xx. Combined with exponential backoff + jitter on retries, it prevents retry storms and allows Cloud Storage to serve a high sustained throughput with fewer errors. This is the recommended reliability pattern for Google APIs under load: control concurrency, ramp gradually after failover, and retry transient failures safely.
問題分析
Core concept: This question tests Cloud Storage request-rate behavior during sudden traffic spikes, and how to design clients/services to handle throttling (HTTP 429) and transient backend errors (5xx) while maintaining high throughput. It also touches disaster recovery failover patterns where “cold” resources suddenly become hot. Why the answer is correct: A newly created, previously idle bucket can experience a rapid ramp to high QPS. When many clients simultaneously start issuing requests, Cloud Storage can respond with 429 (Too Many Requests) due to per-project/per-bucket/per-client or internal fairness limits, and occasional 5xx during overload or transient conditions. The most effective way to reduce failed responses while preserving throughput is to smooth the spike: implement client-side rate limiting with a gradual ramp-up (and pair it with exponential backoff + jitter on retries). This aligns with Google’s guidance for handling 429/5xx: back off and retry rather than continuing to hammer the service. A controlled ramp reaches a stable high throughput with fewer errors than an immediate step-function increase. Key features / best practices: Use token-bucket/leaky-bucket rate limiting per client, gradually increasing allowed QPS over tens of seconds. For retries, use exponential backoff with jitter, respect Retry-After when present, and cap max retry concurrency to avoid retry storms. Consider request batching where applicable, and ensure idempotency for writes (e.g., preconditions like ifGenerationMatch) to safely retry. This approach follows the Google Cloud Architecture Framework reliability principles: design for graceful degradation and controlled recovery during failover. Common misconceptions: It’s tempting to “shard” into many buckets (A) to increase throughput, but Cloud Storage is designed for high request rates per bucket; the issue here is the sudden ramp and client behavior, not a fundamental need for bucket sharding. Switching APIs (B) doesn’t change underlying quotas/limits. Passing errors to end users (C) doesn’t reduce failures and harms user experience. Exam tips: When you see intermittent 429 plus occasional 5xx during a sudden surge, think: throttling + transient overload. The exam expects: implement exponential backoff with jitter and smooth ramp-up (rate limiting), rather than changing APIs or adding architectural complexity like bucket sharding unless the question explicitly indicates a sustained per-bucket limit problem.
You are deploying a Python microservice to a Linux-based GKE Autopilot cluster in us-central1 that must connect to a Cloud SQL for PostgreSQL instance (instance connection name: myproj:us-central1:orders-db) via a Cloud SQL Auth Proxy sidecar, and you have already created a dedicated service account (my-app-sa) and want to follow Google-recommended practices and the principle of least privilege; what should you do next?
Although a custom role containing only cloudsql.instances.connect appears to be more restrictive, it is not the best answer when the question asks for Google-recommended practices. For standard Cloud SQL Auth Proxy connectivity, Google commonly expects the predefined roles/cloudsql.client role rather than a custom role. Custom roles also add operational overhead and can be error-prone if the workload later needs additional related permissions. On certification exams, the predefined least-privilege role is usually preferred unless the prompt explicitly asks you to build a custom role.
roles/cloudsql.client is the standard predefined IAM role for workloads that need to connect to Cloud SQL through the Cloud SQL Auth Proxy. It is the Google-recommended least-privilege choice for connection-only access without granting administrative capabilities over the instance. The --unix-socket option is a valid way to expose the proxy locally inside the Pod, although the essential reason this option is correct is the IAM role assignment, not that Unix sockets are mandatory. In an Autopilot environment, this role is typically used together with Workload Identity so the sidecar can authenticate securely without long-lived keys.
roles/cloudsql.editor is overly permissive because it allows modifying Cloud SQL resources rather than only connecting to them. A Python microservice using the Auth Proxy does not need instance management permissions to establish a database session. Granting editor access violates the principle of least privilege and increases security risk if the workload is compromised. For exam scenarios, management roles are incorrect when the requirement is only application connectivity.
roles/cloudsql.viewer provides read-only visibility into Cloud SQL resources but does not grant the ability to connect through the Cloud SQL Auth Proxy. The proxy requires connection-related permissions, which viewer does not include. As a result, the workload would be able to inspect metadata but not establish the authenticated proxy connection needed by the application. Viewer is a common distractor because it sounds relevant to Cloud SQL without actually enabling access.
問題分析
Core Concept: This question is about the correct IAM role to allow a GKE workload to connect to Cloud SQL for PostgreSQL through the Cloud SQL Auth Proxy while following Google-recommended practices and least privilege. For application connectivity through the proxy, Google’s standard predefined role is roles/cloudsql.client on the service account used by the workload. In GKE Autopilot, this is typically used with Workload Identity so the Pod can impersonate the Google service account without storing keys. Why correct: Option B is correct because roles/cloudsql.client is the recommended least-privilege predefined role for connecting to Cloud SQL through the Auth Proxy. The proxy can expose either a local TCP port or a Unix domain socket; using --unix-socket is valid and commonly used in Kubernetes, but the decisive part of the answer is granting roles/cloudsql.client. This matches Google guidance better than creating a narrowly scoped custom role for a standard connectivity pattern. Key features: - Grant roles/cloudsql.client to the Google service account used by the workload. - In GKE Autopilot, use Workload Identity to bind the Kubernetes service account to my-app-sa. - Run the Cloud SQL Auth Proxy as a sidecar in the same Pod as the application. - The proxy may listen on localhost TCP or a Unix socket; both are supported. Common misconceptions: - roles/cloudsql.viewer is not enough because viewing metadata does not allow connecting. - roles/cloudsql.editor is far too permissive for an app that only needs database connectivity. - A custom role with only cloudsql.instances.connect may sound more restrictive, but exam questions that ask for Google-recommended practice generally expect the predefined roles/cloudsql.client role. Exam tips: When a Google Cloud exam asks for least privilege plus recommended practice for Cloud SQL Auth Proxy access, prefer roles/cloudsql.client unless the question explicitly requires a custom role design. Also remember that on GKE Autopilot, Workload Identity is the preferred authentication mechanism instead of service account keys.
GlobeGigs, a global freelance marketplace, runs a MySQL primary in us-central1 with read replicas in europe-west1 and asia-southeast1 and routes reads to the nearest replica; users in Singapore and Frankfurt still see p99 write latencies over 800 ms because writes go to the primary, and the team targets sub-200 ms p95 for both reads and writes with minimal operational overhead and without introducing eventual consistency for critical transactions. What should they do to further reduce latency for all database interactions with the least amount of effort?
Bigtable is a wide-column NoSQL database optimized for massive throughput and low-latency key/value access patterns. It is not a relational MySQL replacement and does not provide SQL joins or the same transactional semantics expected for “critical transactions.” While it can be replicated for availability, it’s not the best fit for globally consistent relational writes. Migrating would require significant application redesign and may not meet strong consistency expectations for multi-row relational transactions.
Cloud Spanner is a globally distributed, strongly consistent relational database built for low-latency reads and writes across regions. By using a multi-region Spanner instance with read-write replicas close to users (e.g., Europe and Asia), writes can be served locally while maintaining external consistency for transactions. It is fully managed (sharding, replication, failover), meeting the “minimal operational overhead” requirement and directly addressing cross-region write latency inherent in single-primary MySQL.
Firestore in Datastore mode is a managed NoSQL document database. Although it can be deployed in multi-region configurations and offers strong consistency for many operations, it is not a relational database and lacks SQL querying, joins, and typical MySQL transactional patterns across complex relational schemas. Migrating a marketplace’s critical transactional workload from MySQL to Datastore mode usually requires major data model and query redesign, and it may not satisfy the relational/transaction requirements implied by “critical transactions.”
Moving services to GKE and adding a load balancer improves application scalability and availability, but it does not fix the fundamental issue: write latency is dominated by cross-region round-trip time to the single MySQL primary in us-central1. Even perfectly scaled compute cannot reduce the physics of intercontinental latency for database commits. The bottleneck is the database architecture (single-writer primary), so the solution must address global write locality and consistency at the data layer.
問題分析
Core concept: This question tests choosing a globally distributed database that can provide low-latency reads and writes across continents while preserving strong consistency for critical transactions and minimizing operational overhead. Why the answer is correct: Cloud Spanner is designed for global, strongly consistent relational workloads. With Spanner, you can place replicas (including read-write replicas) in multiple regions and have clients write to the nearest read-write replica, avoiding the single-primary cross-ocean write penalty seen with MySQL primary/replica. Spanner provides external consistency (strong consistency with TrueTime) for transactions, so you do not need to accept eventual consistency for critical operations. This directly addresses the requirement: sub-200 ms p95 for both reads and writes globally, without introducing eventual consistency. Key features / best practices: - Multi-region instance configurations with read-write replicas in multiple regions to reduce write latency by locality. - Strongly consistent SQL transactions, secondary indexes, and relational modeling similar to MySQL (though schema/SQL dialect differs). - Managed service: automatic sharding, replication, failover, and high availability, reducing operational overhead compared to self-managed or complex replication topologies. - Use client-side best practices: keep connections regional, use Spanner client libraries, and design schemas to avoid hot-spotting (e.g., avoid monotonically increasing keys). Common misconceptions: - “Read replicas solve global latency”: they only help reads; writes still pay RTT to the primary. - “Any NoSQL global DB will be faster”: many NoSQL options trade off strong consistency or relational transactions, which violates the requirement for critical transactions. - “Scaling compute (GKE/LB) fixes DB latency”: application scaling doesn’t remove cross-region database write RTT. Exam tips: When you see global users + need low-latency reads and writes + strong consistency/transactions + minimal ops, Cloud Spanner is the canonical choice. Bigtable is for wide-column, high-throughput analytics/serving patterns (not relational transactions). Firestore/Datastore can be multi-region but is document/NoSQL and may not meet strict relational/transactional requirements at scale. Always map requirements to CAP/consistency needs and to managed global replication capabilities.
Your company operates a ride-hailing dispatch platform that maintains a persistent cache of all edge worker VMs used for geo-routing; only instances that are in the RUNNING state and have the label fleet=edge-worker should be eligible for job assignment (exclude STOPPED, SUSPENDED, or DELETED instances). The dispatcher reads this cache every 10 seconds and must reflect lifecycle changes (start/stop/suspend/preempt/delete) within 5 seconds across a fleet of 500+ instances to avoid misrouting. You need to design how the application keeps this available-VM cache from becoming noncurrent while minimizing operational overhead. What should you do?
Cloud Storage log sinks are designed for archival and batch-style processing. Even if you trigger on object finalization, logs are written as files with variable batching/flush intervals, so end-to-end latency is not reliably within 5 seconds. It also adds operational overhead (bucket management, object lifecycle, parsing files) and is not the recommended pattern for near-real-time cache invalidation.
Cloud Asset Inventory real-time feeds are best for tracking asset inventory/metadata changes (create/delete, IAM/policy, some config changes). They are not a strong fit for rapid instance power-state transitions like RUNNING/STOPPED/SUSPENDED or preemption signals, and may not provide the consistent sub-5-second lifecycle fidelity required for dispatch correctness.
Pub/Sub log sinks from Cloud Logging provide near-real-time streaming of audit log entries. By filtering for Compute Engine lifecycle-related Admin Activity and System Event logs, you capture both user-driven actions and system-driven events like preemptions. Eventarc can then deliver these messages to your service with retries and low operational overhead, enabling cache updates within seconds across 500+ instances.
BigQuery log sinks are optimized for analytics, not low-latency eventing. Querying every minute already violates the 5-second freshness requirement, and frequent queries increase cost and complexity. This is a pull-based polling design that risks stale cache entries and misrouting, especially during bursts of lifecycle changes (preemptions, autoscaling, rolling updates).
問題分析
Core concept: This question tests event-driven integration for near-real-time infrastructure state changes. The key services are Cloud Logging (audit logs), log sinks to Pub/Sub, and Eventarc for reliable delivery to an application. The goal is to maintain a highly current cache of eligible Compute Engine instances (RUNNING + label fleet=edge-worker) with <5s propagation and minimal ops. Why the answer is correct: Option C uses Cloud Logging audit logs (Admin Activity + System Event) for Compute Engine instance lifecycle changes (start/stop/suspend/delete/preempt/terminate) and exports matching entries to Pub/Sub via an organization-level log sink. Pub/Sub provides low-latency fan-out and buffering, and Eventarc can route those Pub/Sub messages to a service (Cloud Run/GKE/Cloud Functions) that updates the cache immediately. This architecture is push-based, scales to 500+ instances, and meets the 5-second freshness requirement far better than polling. Key features / configuration notes: - Use an org-level sink to cover multiple projects/fleets and reduce operational overhead. - Filter for relevant Compute Engine audit log methods and resource.type="gce_instance" plus label constraints where possible (often labels are best enforced in the consumer by calling the Compute API to confirm current state/labels). - Include both Admin Activity (user/API-initiated) and System Event (system-generated, e.g., preemptions) to avoid missing lifecycle transitions. - Eventarc + Pub/Sub provides retries, dead-lettering patterns, and decoupling; Pub/Sub retention helps absorb bursts. Common misconceptions: - Asset Inventory feeds are about asset metadata changes and may not capture all runtime state transitions (RUNNING/STOPPED/SUSPENDED) with the required immediacy. - Cloud Storage or BigQuery sinks introduce extra latency and/or polling, which violates the 5-second requirement. Exam tips: When you need sub-minute (seconds) reaction to infrastructure changes, prefer push-based eventing: Cloud Logging -> Pub/Sub sink -> Eventarc/consumer. Use polling (BigQuery queries, periodic list calls) only when latency requirements are loose. Also remember preemptions are typically surfaced via system-generated logs/events, so include System Event coverage.
You are designing a real-time processing pipeline for a city's bike-sharing program: each bike sends a GPS/status event to a Pub/Sub topic at an average rate of 5,000 messages per minute with spikes up to 50,000; each message must be processed within 300 ms to update a live availability dashboard, the processing component must have no dependency on any other system or managed infrastructure (no VMs or clusters), and you must incur costs only when new messages arrive; how should you configure the architecture?
Compute Engine requires provisioning and managing VM instances (patching, scaling groups, health checks). Even if Pub/Sub push delivers messages efficiently, the VM must remain running to receive traffic, so you pay while idle—violating “costs only when new messages arrive.” It also conflicts with the requirement of no dependency on managed infrastructure such as VMs or clusters.
Cloud Functions should not create a pull subscription and poll Pub/Sub. Polling adds unnecessary latency and cost because the function would need to run continuously or be invoked on a schedule, which breaks the event-driven model. It also complicates scaling during spikes and can lead to missed 300 ms processing targets due to polling intervals and subscription management overhead.
GKE is explicitly a managed cluster (nodes, autoscaling, upgrades), which violates the “no VMs or clusters” constraint. While pull subscriptions with worker pods can handle high throughput, you pay for cluster resources even when no messages arrive unless you implement complex scale-to-zero patterns (not typical for GKE). Operational overhead is also much higher than serverless options.
Cloud Functions with a Pub/Sub trigger is the canonical serverless pattern for Pub/Sub message processing. It scales automatically with message volume, supports bursty workloads, and charges per invocation/compute time, aligning with pay-per-message arrival. It avoids managing VMs/clusters and provides low-latency event delivery suitable for near-real-time dashboard updates when the function logic is kept lightweight and idempotent.
問題分析
Core concept: This question tests event-driven, serverless stream processing on Google Cloud using Pub/Sub and Cloud Functions, emphasizing autoscaling, low operational overhead, and pay-per-use. It also implicitly tests the difference between Pub/Sub push/pull delivery models and when to avoid managed compute infrastructure (VMs/clusters). Why the answer is correct: Cloud Functions with a Pub/Sub trigger is purpose-built for processing Pub/Sub messages as they arrive. It has no VM/cluster management dependency, scales automatically with message volume (including spikes), and charges primarily for invocations and compute time—aligning with “incur costs only when new messages arrive.” With proper function design (fast startup, minimal external calls), meeting a 300 ms processing target is feasible for lightweight transformations and dashboard updates. Key features / configuration best practices: - Use a Pub/Sub-triggered function (2nd gen Cloud Functions runs on Cloud Run infrastructure) to receive messages via event delivery. - Ensure idempotent processing because Pub/Sub provides at-least-once delivery; handle duplicates using event IDs or timestamps. - Tune concurrency and instance limits (2nd gen) to handle spikes; keep processing CPU/memory sized appropriately to reduce latency. - Use dead-letter topics and retry settings on the subscription for resilience. - Keep dependencies minimal and avoid long network calls; if updating a dashboard datastore, use a low-latency managed service (e.g., Firestore/MemoryStore) but the compute component itself remains serverless. Common misconceptions: - “Push subscription to a VM” (Option A) seems simple, but violates the no-managed-infrastructure requirement and incurs costs even when idle. - “Polling with pull subscriptions” (Options B/C) is a common anti-pattern for serverless triggers; it increases latency, wastes compute, and complicates scaling. Exam tips: When requirements include: (1) no servers/clusters, (2) pay only on events, and (3) near-real-time processing from Pub/Sub, default to Cloud Functions (or Cloud Run) with a Pub/Sub trigger. Avoid designs that require always-on workers or polling. Also remember Pub/Sub is at-least-once; design for retries and duplicates.
外出先でもすべての問題を解きたいですか?
Cloud Passをダウンロード — 模擬試験、学習進捗の追跡などを提供します。
Your team uses Cloud Build to run CI for a Go microservice stored in a private GitHub repository mirrored to Cloud Source Repositories; one of the build steps requires a specific static analysis tool (version 3.7.2) that is not present in the default Cloud Build environment, the tool is ~120 MB and must be available within 5 seconds at step start to keep total build time under a 10-minute SLA, outbound internet access during builds is restricted, and you need reproducible results across ~50 builds per day—what should you do?
Downloading the binary during the build is fragile and typically fails the stated constraints. Outbound internet access is restricted, so the download may be blocked entirely. Even if allowed, network variability and upstream availability can easily exceed the 5-second startup requirement and threaten the 10-minute SLA. It also reduces reproducibility unless you pin checksums and handle mirrors, which adds complexity and risk.
A custom Cloud Build builder image is the best fit: it packages the exact tool version (3.7.2) into the container image so it is available immediately when the step starts. This avoids outbound internet access, improves performance (no runtime download), and ensures reproducible results by pinning the image tag or, better, the image digest. Storing the image in Artifact Registry supports controlled, auditable CI dependencies.
Committing a 120 MB binary into the source repository can make builds work without internet, but it is a poor practice for CI/CD. It bloats the repo, slows cloning and mirroring, complicates code review, and can create supply-chain governance issues (binary provenance, scanning, licensing). It also couples tool distribution to source changes and can be error-prone when multiple services or pipelines need the same tool.
Filing a feature request does not solve the immediate requirement and is not a reliable strategy for meeting SLAs. Default Cloud Build environments change on Google’s schedule and may not include niche tools or specific versions. Even if added, you still need version pinning for reproducibility. On exams, “wait for the platform to add it” is almost never the correct operational answer when you have clear constraints.
問題分析
Core Concept: This question tests Cloud Build execution environments and how to supply deterministic, fast, offline dependencies for build steps. In Cloud Build, each step runs in a container image. If a required tool is not in the default builders, you can either fetch it at build time or package it into a custom builder image. Why the Answer is Correct: A custom Cloud Build builder image that already contains the static analysis tool (v3.7.2) ensures the tool is available immediately when the step starts (meeting the 5-second requirement) and avoids outbound internet access (which is restricted). It also guarantees reproducibility across ~50 builds/day because the tool version is pinned in the image. This aligns with CI best practices: immutable, versioned build environments that reduce variability and external dependencies. Key Features / Configurations / Best Practices: - Create a custom builder image (e.g., based on a minimal Linux image or an official Go builder) and bake the 120 MB binary into the image layer. - Store the image in Artifact Registry (or Container Registry) and reference it in cloudbuild.yaml steps via the image name. - Pin by immutable digest (e.g., image@sha256:...) for maximum reproducibility. - Use Cloud Build private pools if you need tighter network egress control; however, even with restricted egress, prepackaged images avoid runtime downloads. - This approach supports Google Cloud Architecture Framework principles: reliability (consistent builds), operational excellence (repeatable pipelines), and performance efficiency (fast step startup). Common Misconceptions: Downloading during the build (Option A) seems simple, but it violates the restricted outbound internet requirement and introduces latency/availability risk that can break the 10-minute SLA. Committing binaries (Option C) can appear reproducible, but it bloats repos, complicates reviews, and is generally an anti-pattern for supply-chain and maintainability. Requesting default support (Option D) is not an actionable solution for an exam scenario and does not meet immediate SLA needs. Exam Tips: For Cloud Build questions involving “tool not available,” “no internet,” “fast startup,” and “reproducible builds,” the expected pattern is: build a custom builder image, store it in Artifact Registry, and reference it in build steps (often pinned by digest). Prefer immutable, versioned artifacts over runtime downloads or committing large binaries into source control.
Your fintech company runs payment microservices on GKE in project retail-prod-001 and must satisfy PCI DSS 10.3; compliance mandates mirroring a duplicate of all application logs matching resource.type="k8s_container" AND labels.app="payments" AND severity>=ERROR from retail-prod-001 to a separate project audit-logs-123 that is restricted to the audit team, without altering existing retention or disrupting current log flows, and without building custom batch jobs; delivery must be near real time (<60 seconds) and the audit project must control retention at 365 days. What should you do?
Correct. A cross-project Log Router sink exports matching logs in near real time to a user-defined log bucket in audit-logs-123. This duplicates logs without changing existing retention or disrupting current log flows in retail-prod-001. The audit project can set 365-day retention on its bucket, and granting the sink’s writer identity logs.bucketWriter enables secure, least-privilege delivery.
Incorrect. A scheduled Function is a custom batch/ETL approach, violating the requirement to avoid custom batch jobs and likely missing the <60-second near-real-time SLA (daily schedule is explicitly too slow). It also adds operational risk (retries, duplicates, pagination, quota limits) and cost. Additionally, reading from _Required is not the right source for application container logs.
Incorrect. You don’t “modify the _Default bucket’s routing rules” to redirect logs; routing is done via Log Router sinks, and redirecting would change existing log flows, which is prohibited. The requirement is to mirror/duplicate logs while keeping current behavior intact. Also, system buckets (_Default/_Required) have constraints; best practice is to create additional sinks rather than altering baseline ingestion patterns.
Incorrect. Admin Activity and System Event logs are audit logs, not application logs from GKE containers. The requirement is specifically for resource.type="k8s_container" with labels.app="payments" and severity>=ERROR, which are application logs. Copying only _Required audit log categories would not satisfy PCI DSS 10.3 for application error logging and would miss the specified filter criteria.
問題分析
Core Concept: This question tests Cloud Logging architecture: Log Router sinks, cross-project log routing to log buckets, and retention controls. It also touches PCI DSS 10.3 expectations around auditability and separation of duties, which maps to the Google Cloud Architecture Framework security pillar (centralized logging, controlled access, and immutable/retained audit evidence). Why the Answer is Correct: To mirror a subset of logs from retail-prod-001 to a separate, access-restricted audit project in near real time without disrupting existing log flows, you use a Log Router sink in the source project with an inclusion filter and route to a destination log bucket in audit-logs-123. This creates a duplicate stream: logs continue to land in the source project’s buckets unchanged, while matching entries are exported to the audit project within seconds (typically well under 60 seconds). The audit project can then set its own retention (365 days) on its user-defined bucket, satisfying the requirement that the audit team controls retention. Key Features / Configurations: - Create a user-defined log bucket in audit-logs-123 and set retention to 365 days. - In retail-prod-001, create a sink with an inclusion filter such as: resource.type="k8s_container" AND labels.app="payments" AND severity>=ERROR - Choose the destination as the audit project’s log bucket. - Grant the sink’s writer identity the minimum required IAM role on the destination bucket (logs.bucketWriter). This preserves least privilege and separation of duties. Common Misconceptions: Many assume you must “move” logs or change default buckets. In Cloud Logging, you generally export/copy via sinks; you do not modify system buckets or disrupt existing ingestion. Others reach for custom ETL (Functions/Scheduler), but that violates the “no custom batch jobs” and near-real-time constraints and is operationally brittle. Exam Tips: - For cross-project log duplication with retention control, think: Log Router sink -> destination log bucket. - _Required is special (platform-required logs) and not where application logs typically belong; application logs are usually in _Default unless routed. - Retention is controlled at the log bucket level in the destination project; exporting does not change source retention. - Always include the IAM step: grant the sink writer identity permission on the destination bucket.
Your retail analytics team has an IoT gateway that uploads a 5 MB CSV summary every 10 minutes to a Cloud Storage bucket gs://retail-iot-summaries-prod. Upon each successful upload, you must notify a downstream pipeline via the Pub/Sub topic projects/acme/topics/iot-summaries so a Dataflow job can start. You want a solution that requires the least development and operational effort, introduces no additional compute to manage, and can be set up within 1 hour; what should you do?
Correct. Cloud Storage can be configured to publish object finalize (OBJECT_FINALIZE) notifications directly to a Pub/Sub topic. This is a native integration requiring no code and no compute to manage, aligning with minimal operational effort and rapid setup. Ensure IAM allows the Cloud Storage service account to publish to the topic and design downstream consumers for at-least-once delivery semantics.
Incorrect. App Engine would require building and deploying an application endpoint to receive uploads and then publish to Pub/Sub. This adds development time, operational considerations (versions, scaling behavior, monitoring), and changes the ingestion path (gateway uploads to the app rather than directly to Cloud Storage). It violates the requirement for least development and no additional compute to manage.
Incorrect for this question’s constraints. A Cloud Function triggered by Cloud Storage finalize events can publish to Pub/Sub, but it still requires writing, deploying, and operating code (runtime configuration, retries, logging/alerting, IAM for the function). Since Cloud Storage can publish directly to Pub/Sub, the function is unnecessary extra moving parts for a simple notification.
Incorrect. Running a service on GKE introduces the highest operational overhead: cluster provisioning, node management (or even with Autopilot, still more setup), deployments, scaling, security patching, and monitoring. It also requires changing the upload flow to hit the service. This is far from the “within 1 hour” and “no additional compute to manage” requirement.
問題分析
Core Concept: This question tests event-driven integration between Cloud Storage and Pub/Sub with minimal operational overhead. The key capability is Cloud Storage event notifications (object finalize) that can publish directly to a Pub/Sub topic, enabling downstream systems (like Dataflow) to react to new objects without running any intermediary compute. Why the Answer is Correct: Configuring the bucket to send OBJECT_FINALIZE notifications to Pub/Sub is the lowest-development, lowest-ops approach. It requires no code, no runtime to deploy, and no scaling/patching/monitoring of compute. It can be configured quickly (often within minutes) and meets the requirement “upon each successful upload” because finalize events occur when an object is successfully created/overwritten in the bucket. Key Features / Configuration / Best Practices: - Use Cloud Storage Pub/Sub notifications for OBJECT_FINALIZE on gs://retail-iot-summaries-prod. - Ensure the Pub/Sub topic exists in the correct project (projects/acme/topics/iot-summaries) and grant the Cloud Storage service account permission to publish (pubsub.publisher) on the topic. - Consider filtering/handling duplicates downstream: storage notifications are at-least-once delivery, so Dataflow triggering logic should be idempotent (e.g., dedupe by object name + generation). - Include object metadata in the notification (bucket, objectId, generation) to let Dataflow locate the exact file. Common Misconceptions: Cloud Functions (option C) is also serverless, but it introduces code, deployment, IAM for function runtime, retries, and potential cold-start/observability overhead. App Engine and GKE add even more operational burden and are unnecessary because Cloud Storage can already emit Pub/Sub events directly. Exam Tips: When requirements emphasize “least development,” “no additional compute,” and “set up quickly,” prefer managed integrations (native event notifications) over writing glue code. Remember Cloud Storage → Pub/Sub notifications are a classic integration pattern; reserve Cloud Functions for cases needing transformation, validation, routing, or enrichment before publishing.
You are building a real-time leaderboard microservice for a gaming platform and plan to run it on Cloud Run in us-central1. Your source code is stored in a Cloud Source Repository named game-leaderboard, and new releases must deploy automatically whenever changes are pushed to the release/v2 branch. You have already created a cloudbuild.yaml that builds and pushes gcr.io/PROJECT_ID/leaderboard:$SHORT_SHA and then runs: gcloud run deploy leaderboard-api --image gcr.io/PROJECT_ID/leaderboard:$SHORT_SHA --region us-central1 --platform managed --allow-unauthenticated. You want the most efficient approach to ensure each commit to release/v2 triggers a deployment with no manual commands. What should you do next?
Pub/Sub is not the most efficient or standard approach for CSR-to-Cloud Build automation. While you can build event-driven pipelines with Pub/Sub, CSR already has first-class integration with Cloud Build triggers for push events. Adding Pub/Sub increases complexity (topic, permissions, message format, trigger wiring) without providing additional value for a simple “push-to-deploy” workflow.
This is the intended solution: create a Cloud Build trigger tied to the Cloud Source Repository and configure it to run on pushes to the release/v2 branch. The trigger will execute the existing cloudbuild.yaml, building and pushing the image and then deploying to Cloud Run. This provides true CI/CD with minimal components, strong auditability, and branch-based release control.
A generic webhook trigger can work, but it’s not the most efficient here because CSR is already a Google-native source with direct Cloud Build trigger support. Webhooks are typically used for external Git providers or custom systems that can POST to Cloud Build. Using a webhook adds operational overhead (managing the URL/secret and ensuring delivery) compared to a native CSR trigger.
Cloud Scheduler running gcloud builds submit every 24 hours is a polling-based approach and does not meet the requirement that each commit to release/v2 triggers a deployment. It also introduces unnecessary latency and can deploy stale code if multiple commits occur between runs. This is less reliable and less aligned with CI/CD best practices than event-driven triggers.
問題分析
Core Concept: This question tests continuous delivery on Google Cloud using Cloud Build triggers integrated with Cloud Source Repositories (CSR) to automatically build and deploy to Cloud Run on source changes. Why the Answer is Correct: A Cloud Build trigger can be directly connected to the CSR repository and configured to fire on pushes to a specific branch (release/v2). When the trigger runs, it executes the existing cloudbuild.yaml, which already builds the container image, pushes it to Container Registry (gcr.io), and deploys to Cloud Run using gcloud run deploy. This is the most efficient and native approach: no extra glue services, no polling, and no manual commands. Key Features / Configurations / Best Practices: - Cloud Build “Repository event” triggers support branch filtering (e.g., ^release/v2$) so only intended releases deploy. - The trigger runs with a service account; ensure it has roles/run.admin and roles/iam.serviceAccountUser (to deploy Cloud Run) and permissions to push images (e.g., roles/storage.admin or appropriate Artifact Registry/Container Registry permissions). - For least privilege and auditability (Architecture Framework: security and operations excellence), use a dedicated Cloud Build service account and Cloud Audit Logs. - Consider migrating from Container Registry (gcr.io) to Artifact Registry for newer best practices and regional repositories; but it’s not required to answer this question. Common Misconceptions: It may seem you need Pub/Sub or webhooks to “notify” builds, but CSR already integrates with Cloud Build triggers. Pub/Sub is more common for custom eventing pipelines or when the source system is external. Webhooks are useful when the repo is outside Google Cloud or when you can’t use native integration. Exam Tips: When you see “deploy on every push to a branch” and the repo is in CSR (or GitHub), the default answer is almost always a Cloud Build trigger with branch filters. Avoid solutions that poll (Cloud Scheduler) or add unnecessary components (Pub/Sub) unless the question explicitly requires cross-system integration or custom event routing.
You are rolling out an internal reporting service on a fleet of e2-standard-4 Compute Engine VMs in us-central1-a using Terraform; one VM restored from a snapshot has been stuck in 'Starting' for 12 minutes and the serial console shows repeated boot attempts—what two investigations should you prioritize to resolve the launch failure? (Choose two.)
Correct. Repeated boot attempts with serial console output strongly suggests an OS-level boot failure. A common cause after restoring from a snapshot is filesystem inconsistency/corruption (especially if the snapshot was taken while the source VM was running). Attaching the boot disk to a rescue VM to inspect logs and run fsck is a standard, high-signal investigation and aligns with Compute Engine troubleshooting best practices.
Incorrect. If the VM is stuck in “Starting” and repeatedly rebooting, the OS likely never reaches a stable multi-user state where sshd is running and accepting logins. Changing the Linux username does not address bootloader/kernel/filesystem failures. SSH troubleshooting is appropriate when the instance is RUNNING and serial console indicates the OS booted successfully.
Incorrect. VPC firewall rules and routes affect network connectivity to/from an instance, but they do not prevent the guest OS from booting. A VM can fully boot even with no network access. The symptom described (serial console shows repeated boot attempts and the instance remains in Starting) points to disk/OS boot issues rather than routing or firewall configuration.
Correct. A completely full boot disk can prevent essential boot-time writes (logs, temp files, systemd state, cloud-init, package scripts), causing services to fail and potentially triggering reboots/boot loops. A 10-GB boot disk is relatively small and increases the likelihood of filling up due to logs or application artifacts captured in the snapshot. Checking disk usage via rescue attach is a high-priority investigation.
Incorrect. Dropped network traffic (firewall/policy) can explain inability to SSH or reach the application, but it does not explain repeated boot attempts shown in the serial console or a VM stuck in “Starting.” Network policies operate after the OS boots and the NIC is configured; they do not typically cause kernel/init failures or reboot loops.
問題分析
Core concept: This scenario tests Compute Engine VM boot troubleshooting, especially failures after restoring from a snapshot. When an instance is stuck in “Starting” and the serial console shows repeated boot attempts, the problem is almost always inside the guest OS boot path (disk, filesystem, bootloader, init), not networking. The serial console is the primary signal because it works even when the OS never reaches a state where SSH or agents start. Why the answer is correct: A (root filesystem corruption) is a top-priority investigation because snapshot restores can capture an inconsistent filesystem if the source VM wasn’t cleanly shut down or if there were pending writes. Corruption can cause kernel panic, initramfs drops, or systemd failing and rebooting in a loop, which matches “repeated boot attempts.” The standard remediation is to detach/attach the boot disk to a known-good rescue VM, inspect logs, and run filesystem repair (fsck) or recover from backups. D (boot disk full) is also a high-probability cause of boot loops. If the root partition is 100% full, critical boot-time writes can fail (journald, systemd units, package triggers, cloud-init, log rotation), leading to services failing and watchdog/reboot behavior. A small 10-GB boot disk increases this risk, especially for internal reporting services that may write logs or caches. Key features / best practices: Use serial console output and “get-serial-port-output” to pinpoint the failure stage. Use a rescue workflow: stop the VM, detach the boot disk, attach to another VM, mount read-only first, check free space, run fsck, and review /var/log and journal files. Prefer larger boot disks or separate data disks; ensure clean shutdowns before snapshotting; consider filesystem types and journaling. Common misconceptions: Networking/firewall issues (C/E) can block SSH and application traffic but do not prevent the VM from booting; the platform “Starting” state with boot loops is not explained by dropped packets. Trying a different SSH user (B) is irrelevant if the OS never reaches sshd startup. Exam tips: When you see “stuck in Starting” plus serial console boot loops, prioritize disk/OS integrity checks (filesystem corruption, full disk, bad fstab/UUID, bootloader). Network checks are secondary and mainly apply when the VM is RUNNING but unreachable. Map symptoms to layers: platform/boot vs connectivity vs application.
外出先でもすべての問題を解きたいですか?
Cloud Passをダウンロード — 模擬試験、学習進捗の追跡などを提供します。
Your startup has a containerized Node.js 20 API for shipping rate calculations that must be accessible only to customers located within the European Union; traffic averages about 3,500 requests per minute from 09:00–21:00 CET and drops to near zero overnight; you are migrating this workload to Google Cloud and need uncaught exceptions and stack traces to appear in Error Reporting after the move; you want the lowest operational effort and to avoid paying for idle compute when there is no traffic. What should you do?
Cloud Run is serverless for containers, scales automatically, and can scale to zero, minimizing cost when traffic drops overnight. Deploying in europe-west1 supports EU regionality, and Cloud Run exports stdout/stderr to Cloud Logging by default. Uncaught Node.js exceptions and stack traces written to stderr (or logged with ERROR severity) are picked up by Error Reporting with minimal additional configuration.
Cloud Storage is not the primary integration path for Error Reporting. Streaming logs to a bucket adds operational complexity (log routing, lifecycle, parsing) and does not automatically create Error Reporting events. You would still need Cloud Logging-based error entries or additional processing to surface exceptions. Cloud Run is still a good compute choice, but the logging approach is not aligned with Error Reporting best practices.
GKE Autopilot reduces cluster management but still requires Kubernetes operations (deployments, services, policies) and typically incurs baseline costs; it does not naturally scale the entire platform to zero for an HTTP API. While stderr logs from containers can reach Cloud Logging and Error Reporting, the solution violates the “lowest operational effort” and “avoid paying for idle compute” requirements compared to Cloud Run.
This is the highest operational effort option: you manage Kubernetes resources and also add a nonstandard logging pipeline to Cloud Storage. Error Reporting expects errors in Cloud Logging (or supported error event formats), not raw bucket logs. You would pay for Autopilot cluster overhead and likely for always-on components, making it poorly aligned with the diurnal traffic and cost goals.
問題分析
Core Concept: This question tests choosing a serverless container platform that (1) enforces EU-only access/data residency needs, (2) scales with demand and scales to zero to avoid idle cost, and (3) integrates with Cloud Logging and Error Reporting so uncaught exceptions/stack traces are captured with minimal operational effort. Why the Answer is Correct: Cloud Run is the best fit for a containerized Node.js API with highly variable traffic (3,500 req/min during business hours, near zero overnight). Cloud Run automatically scales out based on incoming requests and can scale to zero instances when idle, which aligns with the requirement to avoid paying for idle compute and to minimize operations. Deploying in an EU region such as europe-west1 supports EU data residency and helps meet “accessible only to customers located within the EU” by keeping the service regional and enabling additional access controls (e.g., IAM, load balancer policies) without managing clusters. Key Features / Configurations: - Error Reporting integration: Cloud Run automatically exports stdout/stderr to Cloud Logging. Writing uncaught exceptions and stack traces to stderr (or using structured logging with severity=ERROR) allows Error Reporting to group and display them. - Scale-to-zero and per-request billing: Cloud Run charges primarily for CPU/memory during request handling (and configured minimum instances if set). Leaving min instances at 0 avoids overnight cost. - EU-only access: Deploy in europe-west1 and restrict ingress (internal and Cloud Load Balancing) plus identity-based access (IAM) and, if needed, geo-based access controls at the edge (commonly via an external HTTPS load balancer with Cloud Armor geo policies). The key is Cloud Run provides the lowest ops baseline. Common Misconceptions: A frequent trap is assuming you must store logs in Cloud Storage for Error Reporting. Error Reporting is driven by Cloud Logging entries (and supported error events), not by raw log files in a bucket. Another misconception is that GKE Autopilot is “fully managed so it’s the same ops as Cloud Run.” Autopilot reduces node management, but you still manage Kubernetes objects, upgrades/rollouts, and baseline cluster costs; it also won’t naturally scale to zero for an always-on API. Exam Tips: When you see “containerized web API,” “spiky/diurnal traffic,” “lowest operational effort,” and “avoid paying for idle,” default to Cloud Run unless there’s a hard requirement for Kubernetes primitives. For Error Reporting, remember: write errors to stderr (or structured logs with ERROR severity) so Cloud Logging can feed Error Reporting automatically.
Your manufacturing analytics batch runs every 10 minutes from a containerized job on GKE that invokes the bq CLI in batch mode to execute a SQL file against the BigQuery dataset iot_agg in project alpha-logs, piping the CLI output to a downstream formatter process; the workload uses the node-attached service account gke-batch@factory-ops.iam.gserviceaccount.com, and the bq CLI intermittently fails with a permission error indicating the job cannot be created when the query runs. You need to resolve the permission issue without changing the query logic or the piping behavior of the CLI output. What should you do?
Correct. BigQuery queries executed via bq require permission to create jobs (bigquery.jobs.create), granted by BigQuery Job User at the project level. The query also needs read access to tables/views, provided by BigQuery Data Viewer. Granting both roles on project alpha-logs addresses the stated “job cannot be created” error and ensures the dataset can be read, without changing query logic or output piping.
Incorrect. Data Editor and Data Viewer on the dataset control access to dataset objects (read/write) but do not grant permission to create BigQuery jobs. The bq CLI still must submit a query job, and without roles/bigquery.jobUser (or equivalent) on the project, the service account can continue to fail with bigquery.jobs.create permission errors.
Incorrect. Creating a view does not eliminate job creation; running SELECT * FROM view still executes as a BigQuery query job and still requires bigquery.jobs.create. It also changes the operational model (introduces a managed object and deployment lifecycle) and may require additional permissions to create/manage the view, which doesn’t solve the root cause.
Incorrect. Copying data to a temporary dataset is an architectural workaround that increases cost, complexity, and operational risk (data freshness, duplication, quotas). It also does not inherently fix job creation permissions; queries against the temporary dataset would still require bigquery.jobs.create on the project where the job runs, so the same permission error could persist.
問題分析
Core Concept: This question tests BigQuery IAM separation of permissions for (1) reading data (dataset/table access) and (2) creating/running query jobs (project-level job creation). The bq CLI always submits a BigQuery job for a query, even when output is streamed to stdout and piped to another process. Why the Answer is Correct: The error indicates the job cannot be created. In BigQuery, the permission to create query jobs is controlled by bigquery.jobs.create, typically granted via roles/bigquery.jobUser (BigQuery Job User) at the project level where the job is created/billed. Separately, the query needs read access to the referenced tables/views, commonly via roles/bigquery.dataViewer on the dataset. Granting both BigQuery Job User and BigQuery Data Viewer on project alpha-logs ensures the GKE node-attached service account can (a) create the query job and (b) read the iot_agg dataset objects, without changing query logic or the CLI piping behavior. Key Features / Best Practices: - BigQuery job creation is project-scoped; dataset roles alone do not grant job submission. - Least privilege: in many designs you grant Job User at the project and Data Viewer at the dataset. However, the option provided that reliably fixes both job creation and data access is project-level Job User + Data Viewer. - In GKE, ensure the workload identity/credential path is consistent; intermittent permission errors often surface when some pods/nodes use different identities. Still, the stated error is specifically about job creation permission. - Aligns with Google Cloud Architecture Framework security principle: grant only required permissions to the runtime identity and avoid redesigning data flows to work around IAM. Common Misconceptions: - Assuming dataset-level permissions are sufficient to run queries. They are not; you also need job creation permission. - Trying to “avoid jobs” by using views or different datasets. Queries still run as jobs, and views don’t remove the need for bigquery.jobs.create. Exam Tips: When you see BigQuery errors like “Access Denied: User does not have bigquery.jobs.create permission,” think: add BigQuery Job User on the billing/job project. When you see “Access Denied” on tables/datasets, think: Data Viewer (read) or Data Editor (write) on the dataset. Distinguish job permissions (project) from data permissions (dataset).
You are building an external review portal for a film festival that stores high‑bitrate video dailies in Cloud Storage, and you must let reviewers—some of whom do not have Google accounts—securely access only their assigned files with the ability to read, upload replacements, or delete them for a strict 24-hour window; how should you provide access to the objects?
Correct. V4 signed URLs let your application grant temporary access to specific Cloud Storage objects without requiring the reviewer to authenticate with a Google account. This matches the requirement for external users and supports least-privilege access by generating URLs only for the assigned files. A 24-hour expiration is supported, making signed URLs the best fit for secure, time-bound object access in this scenario.
Incorrect. Granting Service Account Token Creator enables impersonation, which is powerful and risky for external users. It effectively gives reviewers a pathway to obtain credentials and potentially access beyond assigned objects, depending on permissions. It also assumes reviewers can use Google IAM-based flows and identities, conflicting with “some do not have Google accounts,” and is not least privilege.
Incorrect. Distributing a service account key to external reviewers is a major security anti-pattern: keys can be copied, reused, and exfiltrated. Also, service account keys do not support a native “expire after 24 hours” setting in the way implied; you would need to rotate/delete keys manually. This approach grants broad access and violates best practices for credential management.
Incorrect. IAM roles (even with IAM Conditions that expire) require binding to a principal identity. Reviewers without Google accounts cannot be directly granted Storage Object User on the bucket. Additionally, bucket-level role assignment is broader than per-object access unless combined with complex conditional logic; signed URLs are simpler and more precise for object-level, time-bound external access.
問題分析
Core Concept: This question tests secure, time-bound access to Cloud Storage objects for external users who may not have Google identities. The key concept is using Cloud Storage signed URLs to delegate temporary access to specific objects without granting IAM permissions directly to the end user. Why the Answer is Correct: Because some reviewers do not have Google accounts, IAM role bindings are not a good fit. Signed URLs let your application grant access to individual objects for a limited time window, which aligns with the requirement to restrict each reviewer to only assigned files for 24 hours. This is the standard Google Cloud pattern for temporary external access to Cloud Storage objects. Key Features / Best Practices: - Use V4 signed URLs with a 24-hour expiration to provide temporary object access without requiring Google authentication. - Generate URLs per object so each reviewer receives access only to the files assigned to them. - Use signed URLs for object retrieval and uploads, and avoid distributing service account keys or broad IAM permissions. - Prefer application-controlled signing using managed service account credentials rather than exporting long-lived keys. Common Misconceptions: A common trap is assuming IAM Conditions solve all temporary-access problems; they still require a valid principal identity. Another misconception is that sharing service account credentials is an acceptable shortcut for external access, when it is actually a major security risk. Also, bucket-level IAM is usually too broad when the requirement is object-specific delegation. Exam Tips: When a question mentions external users without Google accounts and temporary access to Cloud Storage, signed URLs are usually the best answer. Focus on least privilege, object-level scope, and short-lived access. Eliminate options that require distributing credentials or assigning broad IAM roles to external parties.
Your startup manages 3,000 smart vending machines that publish 4 KB JSON telemetry to a Pub/Sub topic at an average rate of 600 messages per second (peaks up to 1,200). You must parse each message and persist it for analytics with end-to-end latency under 45 seconds, and each message must be processed exactly once to avoid double-counting transactions. You want the cheapest and simplest fully managed approach with minimal operations overhead and cannot maintain clusters or build custom deduplication workflows. What should you do?
Recurring Dataproc jobs are batch-oriented and typically won’t meet a strict <45-second end-to-end latency SLA unless run extremely frequently, which increases cost and complexity. Dataproc also implies cluster management (even if ephemeral), conflicting with “cannot maintain clusters.” Pulling from Pub/Sub in batch can also complicate offset management and exactly-once guarantees without additional state handling.
Dataflow streaming is fully managed, autoscaling, and designed for Pub/Sub ingestion with low latency. Apache Beam’s PubsubIO integrates cleanly, and Dataflow provides fault tolerance via checkpointing so messages are not double-counted within the pipeline. Windowed writes to Cloud Storage support efficient downstream analytics workflows while keeping operations overhead low and meeting the 45-second latency requirement.
Pub/Sub-triggered Cloud Functions provide at-least-once delivery, so duplicates can occur during retries, timeouts, or transient errors. Writing directly to BigQuery from Functions can therefore double-count unless you implement idempotency or deduplication. The option explicitly relies on a daily dedup query, which violates the “exactly once” requirement and also fails the <45-second end-to-end correctness requirement for analytics.
This design adds unnecessary complexity and operational overhead: writing to Bigtable and then running a second streaming pipeline to remove duplicates is explicitly a custom deduplication workflow, which the prompt disallows. It also increases cost (Bigtable instance + two pipelines) and introduces more failure modes and latency. Dataflow can handle exactly-once processing without this two-step approach.
問題分析
Core concept: This question tests selecting a fully managed streaming ingestion and processing architecture that meets low-latency SLAs and exactly-once processing semantics. The key services are Pub/Sub for ingestion and Dataflow (Apache Beam) for managed stream processing, with an analytics sink. Why the answer is correct: A Dataflow streaming pipeline reading from Pub/Sub and writing windowed outputs to Cloud Storage is the simplest fully managed option among the choices that can meet the <45s end-to-end latency requirement while providing exactly-once processing guarantees within the pipeline. Dataflow provides checkpointing, autoscaling, and fault-tolerant processing. With Pub/Sub as the source, Dataflow can ensure each message is processed once by the pipeline (no custom dedup workflow required) and can emit deterministic windowed files to Cloud Storage for downstream analytics (for example, batch loads to BigQuery or processing via Dataproc Serverless/BigQuery external tables). Key features / configurations / best practices: - Use Dataflow streaming with Pub/Sub source and enable streaming engine for efficiency. - Use event-time processing with fixed windows (e.g., 1-minute) and allowed lateness appropriate to device clock skew. - Write to Cloud Storage using windowed writes (e.g., file-per-window with sharding) to keep file sizes reasonable and avoid small-file problems. - Size for peaks: 1,200 msg/s * 4 KB ≈ 4.8 MB/s, which is well within Pub/Sub and Dataflow throughput; Dataflow autoscaling handles bursts. - Exactly-once: Dataflow’s checkpointing and replay handling avoids double-processing in the pipeline; avoid non-idempotent side effects unless the sink supports idempotency. Common misconceptions: - “Cloud Functions is simpler”: it is operationally simple, but exactly-once is not guaranteed with Pub/Sub-triggered functions (at-least-once delivery), so you must deduplicate, which the prompt forbids. - “Dataproc job is cheaper”: recurring batch jobs increase latency and require cluster operations (or at least job orchestration) and don’t naturally meet a 45-second streaming SLA. - “Use Bigtable then dedupe”: introduces extra pipelines and custom dedup logic, violating the requirement for minimal operations and no custom dedup workflows. Exam tips: - For Pub/Sub streaming with low latency and minimal ops, default to Dataflow. - If the requirement says “exactly once” and forbids custom dedup, avoid Cloud Functions/Cloud Run consumers unless the sink is inherently idempotent and the design explicitly uses unique keys. - Map requirements to the Google Cloud Architecture Framework: operational excellence (managed services), reliability (checkpointing/retries), performance (autoscaling), and cost (avoid always-on clusters).
Your CI pipeline runs 200 unit tests per commit for a fleet-management analytics service that consumes messages from a Cloud Pub/Sub topic named 'telemetry' using ordering keys set to vehicle_id; for each test you need to publish a sequence of 50 messages for a single vehicle_id and assert that your subscriber processes them strictly in order within the key, while keeping the tests reliable, fast, and at zero additional GCP cost; what should you do?
A custom mocking framework is risky because it is very hard to accurately reproduce Pub/Sub semantics (ordering keys, redelivery, ack deadlines, flow control, and concurrency effects). Such mocks often diverge from real behavior, creating tests that pass but fail in production. It also increases maintenance burden and does not align with best practices for testing managed services when an official emulator exists.
Creating a dedicated topic and subscription per tester can reduce interference, but it adds operational overhead (resource creation/cleanup, IAM, quotas) and can still be flaky due to real service dependencies. It also violates the “zero additional GCP cost” requirement because Pub/Sub usage (publish/deliver operations, storage) is billable, and scaling this across many CI runs can become expensive.
Subscription filters can isolate messages by tester_id, but they do not eliminate cost or external dependency. You still pay for publishing and delivery attempts, and filters add complexity (ensuring every message has correct attributes, managing filter expressions). Filters also don’t fully prevent flakiness from shared infrastructure, parallel test contention, or transient Pub/Sub service behavior in CI.
The local Cloud Pub/Sub emulator is designed for development and testing without incurring GCP charges. It provides an isolated environment that improves reliability and speed in CI by removing network and managed-service variability. It’s the best match for “reliable, fast, and zero additional GCP cost,” while still exercising real client libraries and your subscriber’s ordering-key logic.
問題分析
Core Concept: This question tests how to build reliable, fast, and cost-free automated tests for a Pub/Sub consumer that depends on message ordering keys. Pub/Sub ordering guarantees are subtle (ordering is per ordering key, requires message ordering enabled on the topic, and is enforced by the service), so tests should validate behavior without introducing flaky network/service dependencies. Why the Answer is Correct: Running unit tests against the local Cloud Pub/Sub emulator provides a deterministic, isolated environment with no GCP charges and minimal latency. It avoids shared-project interference (other CI jobs publishing to the same topic) and removes external factors like transient service throttling, IAM propagation delays, or regional network variability that can make CI tests flaky. For CI pipelines running 200 tests per commit, the emulator keeps execution fast and repeatable while still exercising your publisher/subscriber integration logic and ordering-key handling. Key Features / Best Practices: - Pub/Sub emulator runs locally (or in a CI container) and does not incur Pub/Sub usage costs. - Enables hermetic tests: each test can create its own topic/subscription names, publish the 50 messages for a single vehicle_id ordering key, and assert the subscriber processes them in order. - Aligns with Google Cloud Architecture Framework principles: reliability (repeatable tests), operational excellence (automated CI), and cost optimization (zero additional cost). - Practical approach: use unique resource names per test run to avoid cross-test contamination; keep acknowledgments and subscriber concurrency controlled to validate ordering within a key. Common Misconceptions: It’s tempting to isolate traffic in real Pub/Sub using separate topics/subscriptions or filters, but that still costs money, adds resource-management overhead, and can be flaky under parallel CI. Another trap is building custom mocks; they rarely match Pub/Sub’s real semantics (redelivery, ack deadlines, flow control, ordering behavior), leading to false confidence. Exam Tips: When a question emphasizes “reliable, fast, and zero additional GCP cost” for Pub/Sub testing, the emulator is the canonical choice. Prefer emulators for unit/integration tests in CI, and reserve real Pub/Sub for a smaller set of end-to-end tests. Also remember ordering is guaranteed only within an ordering key and depends on correct client configuration and subscriber processing patterns.
合格体験記(6)
学習期間: 2 months
The scenarios in this app were extremely useful. The explanations made even the tricky deployment questions easy to understand. Definitely worth using.
学習期間: 2 months
The questions weren’t just easy recalls — they taught me how to approach real developer scenarios. I passed this week thanks to these practice sets.
学習期間: 1 month
1개월 구독하니 빠르게 풀어야 한다는 강박이 생기면서 더 열심히 공부하게 됐던거 같아요. 다행히 문제들이 비슷해서 쉽게 풀 수 있었네요
学習期間: 1 month
이 앱의 문제들과 실제 시험 문제들이 많이 비슷해서 쉽게 풀었어요! 첫 시험만에 합격하니 좋네요 굿굿
学習期間: 1 month
I prepared for three weeks using Cloud Pass and the improvement was huge. The difficulty level was close to the real Cloud Developer exam, and the explanations helped me fill in my knowledge gaps quickly.
他のGCP認定資格

Google Professional Cloud DevOps Engineer
Professional

Google Associate Cloud Engineer
Associate

Google Professional Cloud Network Engineer
Professional

Google Associate Data Practitioner
Associate

Google Cloud Digital Leader
Foundational

Google Professional Cloud Security Engineer
Professional

Google Professional Cloud Architect
Professional

Google Professional Cloud Database Engineer
Professional

Google Professional Data Engineer
Professional

Google Professional Machine Learning Engineer
Professional

今すぐ学習を始める
Cloud Passをダウンロードして、すべてのGoogle Professional Cloud Developer練習問題を利用しましょう。
外出先でもすべての問題を解きたいですか?
アプリを入手
Cloud Passをダウンロード — 模擬試験、学習進捗の追跡などを提供します。